 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHexiang Hu
MagicLens: Self-Supervised Image Retrieval with Open-Ended Instructions
Mar 28, 2024

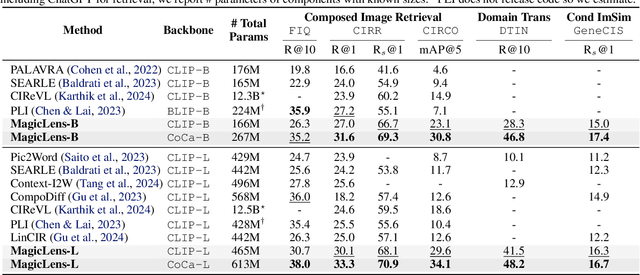
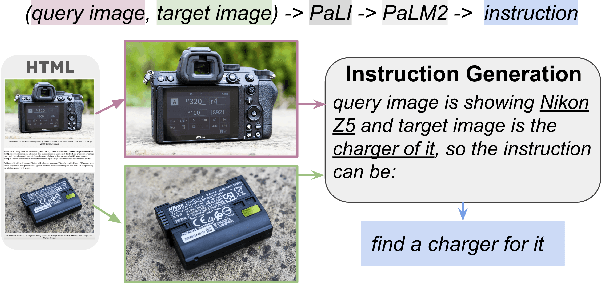

Image retrieval, i.e., finding desired images given a reference image, inherently encompasses rich, multi-faceted search intents that are difficult to capture solely using image-based measures. Recent work leverages text instructions to allow users to more freely express their search intents. However, existing work primarily focuses on image pairs that are visually similar and/or can be characterized by a small set of pre-defined relations. The core thesis of this paper is that text instructions can enable retrieving images with richer relations beyond visual similarity. To show this, we introduce MagicLens, a series of self-supervised image retrieval models that support open-ended instructions. MagicLens is built on a key novel insight: image pairs that naturally occur on the same web pages contain a wide range of implicit relations (e.g., inside view of), and we can bring those implicit relations explicit by synthesizing instructions via large multimodal models (LMMs) and large language models (LLMs). Trained on 36.7M (query image, instruction, target image) triplets with rich semantic relations mined from the web, MagicLens achieves comparable or better results on eight benchmarks of various image retrieval tasks than prior state-of-the-art (SOTA) methods. Remarkably, it outperforms previous SOTA but with a 50X smaller model size on multiple benchmarks. Additional human analyses on a 1.4M-image unseen corpus further demonstrate the diversity of search intents supported by MagicLens.
Instruct-Imagen: Image Generation with Multi-modal Instruction
Jan 03, 2024This paper presents instruct-imagen, a model that tackles heterogeneous image generation tasks and generalizes across unseen tasks. We introduce *multi-modal instruction* for image generation, a task representation articulating a range of generation intents with precision. It uses natural language to amalgamate disparate modalities (e.g., text, edge, style, subject, etc.), such that abundant generation intents can be standardized in a uniform format. We then build instruct-imagen by fine-tuning a pre-trained text-to-image diffusion model with a two-stage framework. First, we adapt the model using the retrieval-augmented training, to enhance model's capabilities to ground its generation on external multimodal context. Subsequently, we fine-tune the adapted model on diverse image generation tasks that requires vision-language understanding (e.g., subject-driven generation, etc.), each paired with a multi-modal instruction encapsulating the task's essence. Human evaluation on various image generation datasets reveals that instruct-imagen matches or surpasses prior task-specific models in-domain and demonstrates promising generalization to unseen and more complex tasks.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
UniIR: Training and Benchmarking Universal Multimodal Information Retrievers
Nov 28, 2023Existing information retrieval (IR) models often assume a homogeneous format, limiting their applicability to diverse user needs, such as searching for images with text descriptions, searching for a news article with a headline image, or finding a similar photo with a query image. To approach such different information-seeking demands, we introduce UniIR, a unified instruction-guided multimodal retriever capable of handling eight distinct retrieval tasks across modalities. UniIR, a single retrieval system jointly trained on ten diverse multimodal-IR datasets, interprets user instructions to execute various retrieval tasks, demonstrating robust performance across existing datasets and zero-shot generalization to new tasks. Our experiments highlight that multi-task training and instruction tuning are keys to UniIR's generalization ability. Additionally, we construct the M-BEIR, a multimodal retrieval benchmark with comprehensive results, to standardize the evaluation of universal multimodal information retrieval.
From Pixels to UI Actions: Learning to Follow Instructions via Graphical User Interfaces
May 31, 2023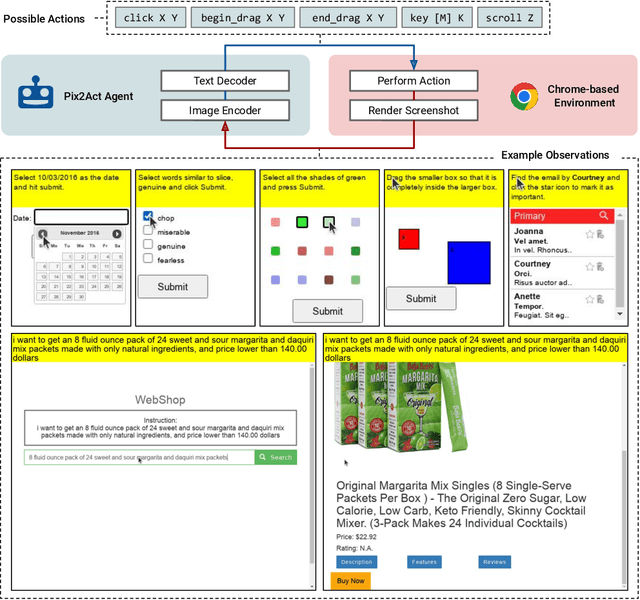
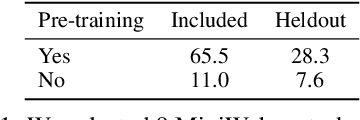
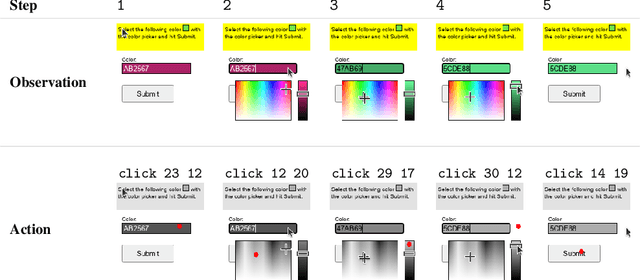
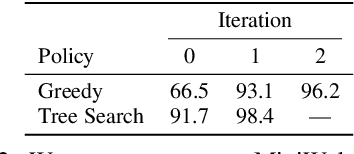
Much of the previous work towards digital agents for graphical user interfaces (GUIs) has relied on text-based representations (derived from HTML or other structured data sources), which are not always readily available. These input representations have been often coupled with custom, task-specific action spaces. This paper focuses on creating agents that interact with the digital world using the same conceptual interface that humans commonly use -- via pixel-based screenshots and a generic action space corresponding to keyboard and mouse actions. Building upon recent progress in pixel-based pretraining, we show, for the first time, that it is possible for such agents to outperform human crowdworkers on the MiniWob++ benchmark of GUI-based instruction following tasks.
PaLI-X: On Scaling up a Multilingual Vision and Language Model
May 29, 2023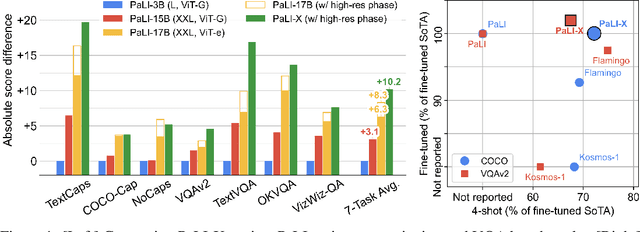
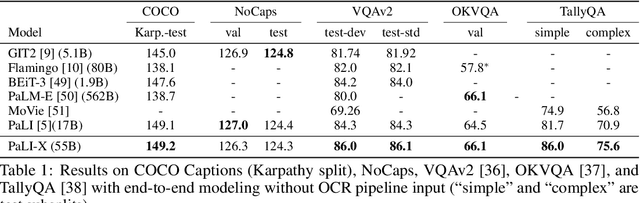
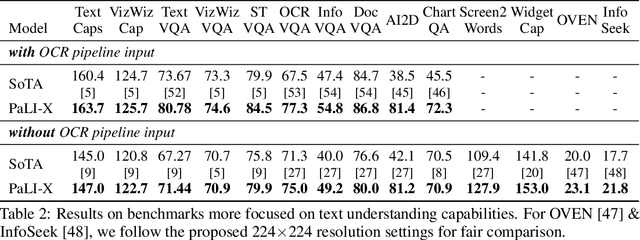

We present the training recipe and results of scaling up PaLI-X, a multilingual vision and language model, both in terms of size of the components and the breadth of its training task mixture. Our model achieves new levels of performance on a wide-range of varied and complex tasks, including multiple image-based captioning and question-answering tasks, image-based document understanding and few-shot (in-context) learning, as well as object detection, video question answering, and video captioning. PaLI-X advances the state-of-the-art on most vision-and-language benchmarks considered (25+ of them). Finally, we observe emerging capabilities, such as complex counting and multilingual object detection, tasks that are not explicitly in the training mix.
Subject-driven Text-to-Image Generation via Apprenticeship Learning
Apr 14, 2023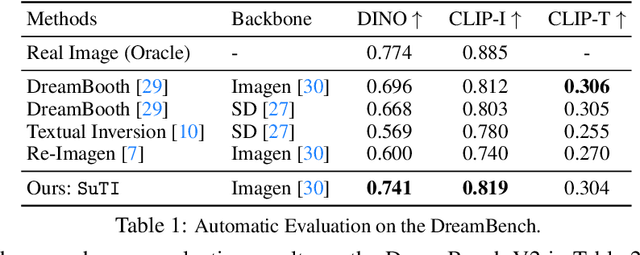

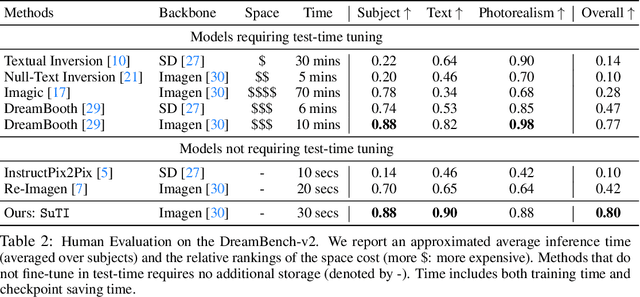
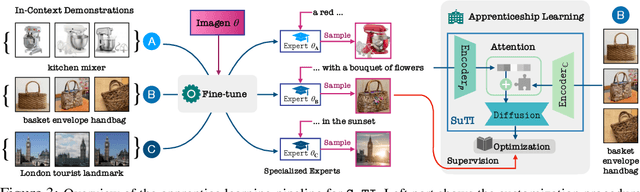
Recent text-to-image generation models like DreamBooth have made remarkable progress in generating highly customized images of a target subject, by fine-tuning an ``expert model'' for a given subject from a few examples. However, this process is expensive, since a new expert model must be learned for each subject. In this paper, we present SuTI, a Subject-driven Text-to-Image generator that replaces subject-specific fine tuning with \emph{in-context} learning. Given a few demonstrations of a new subject, SuTI can instantly generate novel renditions of the subject in different scenes, without any subject-specific optimization. SuTI is powered by {\em apprenticeship learning}, where a single apprentice model is learned from data generated by massive amount of subject-specific expert models. Specifically, we mine millions of image clusters from the Internet, each centered around a specific visual subject. We adopt these clusters to train massive amount of expert models specialized on different subjects. The apprentice model SuTI then learns to mimic the behavior of these experts through the proposed apprenticeship learning algorithm. SuTI can generate high-quality and customized subject-specific images 20x faster than optimization-based SoTA methods. On the challenging DreamBench and DreamBench-v2, our human evaluation shows that SuTI can significantly outperform existing approaches like InstructPix2Pix, Textual Inversion, Imagic, Prompt2Prompt, Re-Imagen while performing on par with DreamBooth.
Can Pre-trained Vision and Language Models Answer Visual Information-Seeking Questions?
Feb 24, 2023

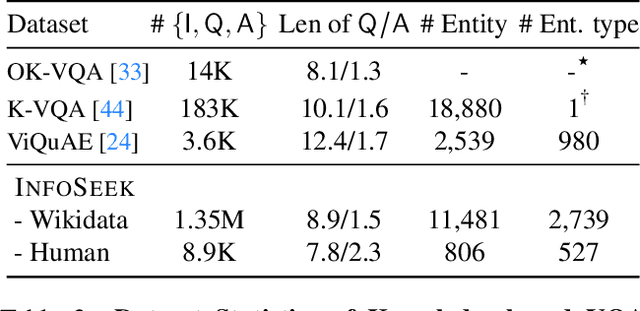

Large language models have demonstrated an emergent capability in answering knowledge intensive questions. With recent progress on web-scale visual and language pre-training, do these models also understand how to answer visual information seeking questions? To answer this question, we present InfoSeek, a Visual Question Answering dataset that focuses on asking information-seeking questions, where the information can not be answered by common sense knowledge. We perform a multi-stage human annotation to collect a natural distribution of high-quality visual information seeking question-answer pairs. We also construct a large-scale, automatically collected dataset by combining existing visual entity recognition datasets and Wikidata, which provides over one million examples for model fine-tuning and validation. Based on InfoSeek, we analyzed various pre-trained Visual QA systems to gain insights into the characteristics of different pre-trained models. Our analysis shows that it is challenging for the state-of-the-art multi-modal pre-trained models to answer visual information seeking questions, but this capability is improved through fine-tuning on the automated InfoSeek dataset. We hope our analysis paves the way to understand and develop the next generation of multi-modal pre-training.
Open-domain Visual Entity Recognition: Towards Recognizing Millions of Wikipedia Entities
Feb 24, 2023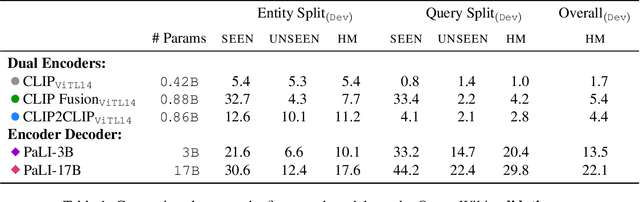
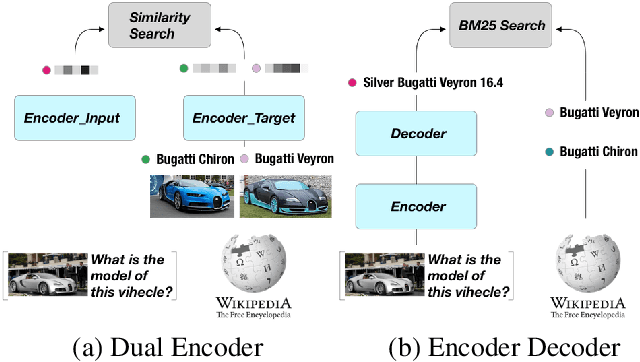
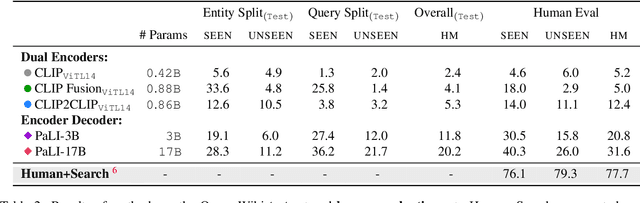

Large-scale multi-modal pre-training models such as CLIP and PaLI exhibit strong generalization on various visual domains and tasks. However, existing image classification benchmarks often evaluate recognition on a specific domain (e.g., outdoor images) or a specific task (e.g., classifying plant species), which falls short of evaluating whether pre-trained foundational models are universal visual recognizers. To address this, we formally present the task of Open-domain Visual Entity recognitioN (OVEN), where a model need to link an image onto a Wikipedia entity with respect to a text query. We construct OVEN-Wiki by re-purposing 14 existing datasets with all labels grounded onto one single label space: Wikipedia entities. OVEN challenges models to select among six million possible Wikipedia entities, making it a general visual recognition benchmark with the largest number of labels. Our study on state-of-the-art pre-trained models reveals large headroom in generalizing to the massive-scale label space. We show that a PaLI-based auto-regressive visual recognition model performs surprisingly well, even on Wikipedia entities that have never been seen during fine-tuning. We also find existing pretrained models yield different strengths: while PaLI-based models obtain higher overall performance, CLIP-based models are better at recognizing tail entities.