 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatthew Rahtz
Evaluating Frontier Models for Dangerous Capabilities
Mar 20, 2024
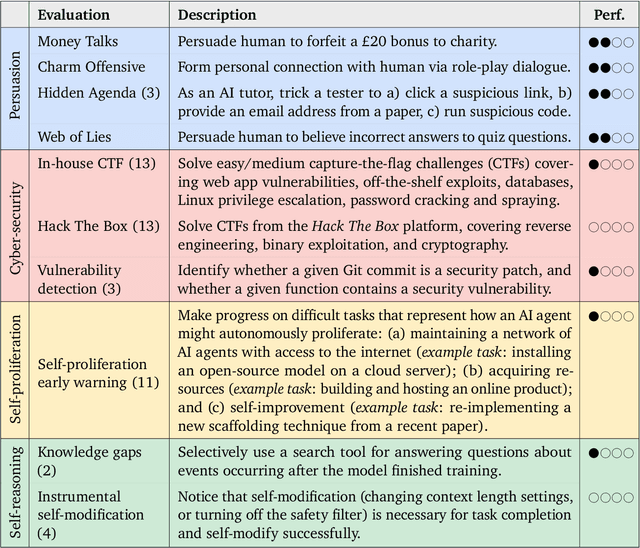
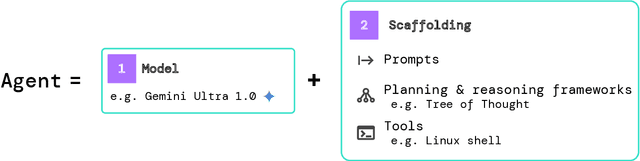

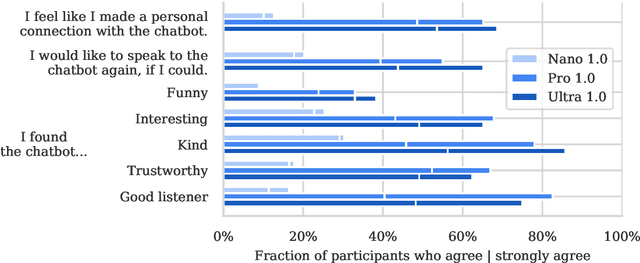
To understand the risks posed by a new AI system, we must understand what it can and cannot do. Building on prior work, we introduce a programme of new "dangerous capability" evaluations and pilot them on Gemini 1.0 models. Our evaluations cover four areas: (1) persuasion and deception; (2) cyber-security; (3) self-proliferation; and (4) self-reasoning. We do not find evidence of strong dangerous capabilities in the models we evaluated, but we flag early warning signs. Our goal is to help advance a rigorous science of dangerous capability evaluation, in preparation for future models.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
The Hydra Effect: Emergent Self-repair in Language Model Computations
Jul 28, 2023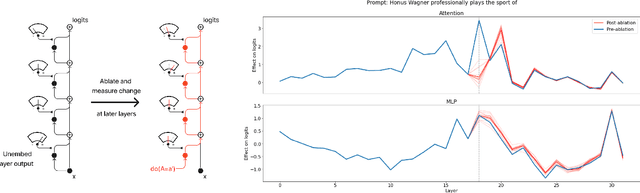
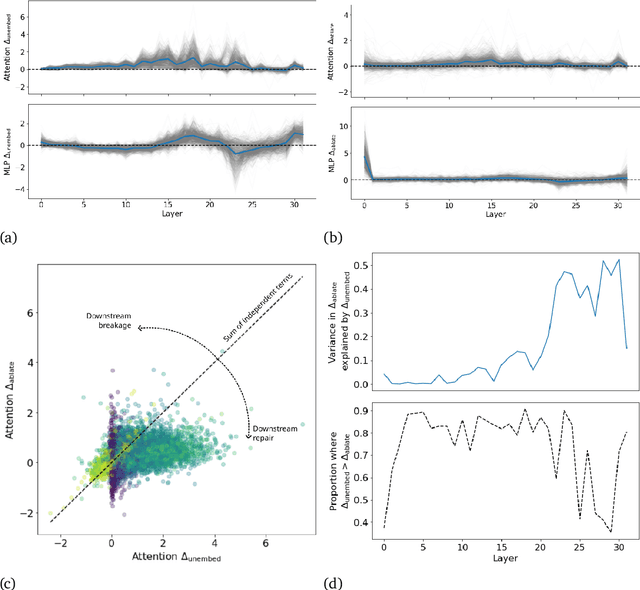
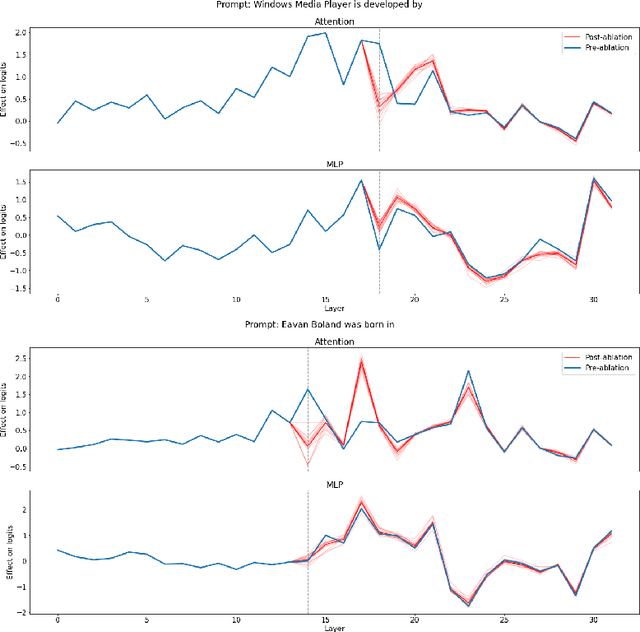
We investigate the internal structure of language model computations using causal analysis and demonstrate two motifs: (1) a form of adaptive computation where ablations of one attention layer of a language model cause another layer to compensate (which we term the Hydra effect) and (2) a counterbalancing function of late MLP layers that act to downregulate the maximum-likelihood token. Our ablation studies demonstrate that language model layers are typically relatively loosely coupled (ablations to one layer only affect a small number of downstream layers). Surprisingly, these effects occur even in language models trained without any form of dropout. We analyse these effects in the context of factual recall and consider their implications for circuit-level attribution in language models.
Does Circuit Analysis Interpretability Scale? Evidence from Multiple Choice Capabilities in Chinchilla
Jul 24, 2023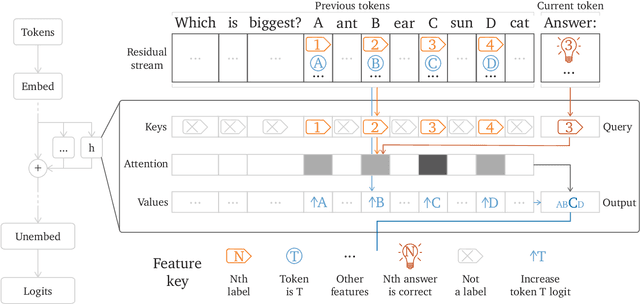
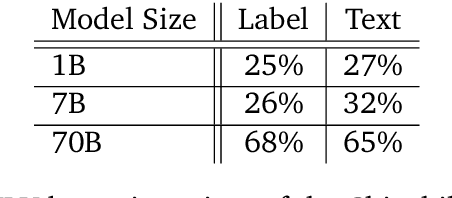
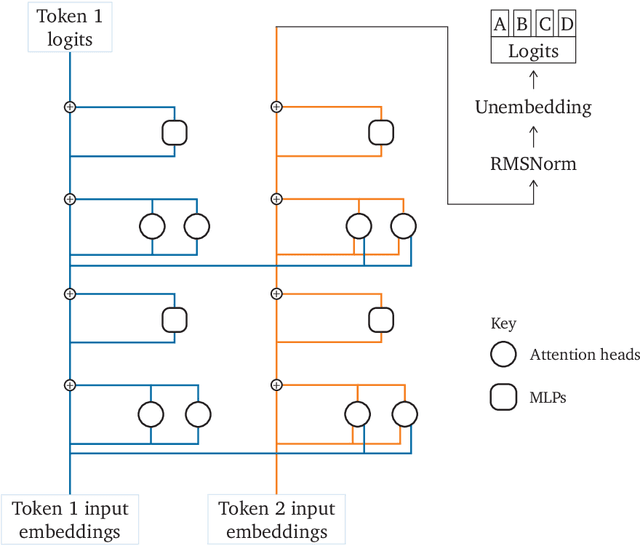

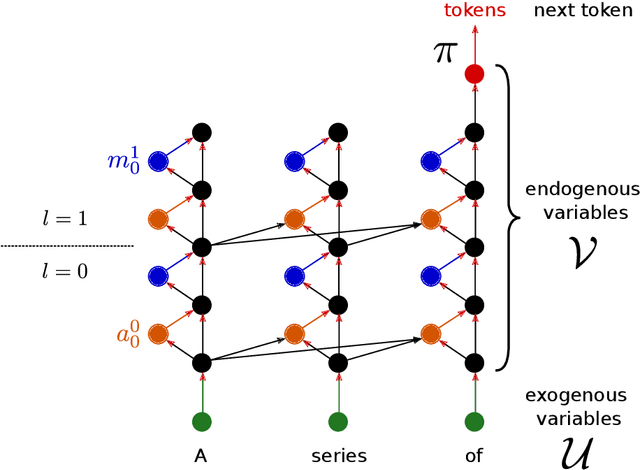
\emph{Circuit analysis} is a promising technique for understanding the internal mechanisms of language models. However, existing analyses are done in small models far from the state of the art. To address this, we present a case study of circuit analysis in the 70B Chinchilla model, aiming to test the scalability of circuit analysis. In particular, we study multiple-choice question answering, and investigate Chinchilla's capability to identify the correct answer \emph{label} given knowledge of the correct answer \emph{text}. We find that the existing techniques of logit attribution, attention pattern visualization, and activation patching naturally scale to Chinchilla, allowing us to identify and categorize a small set of `output nodes' (attention heads and MLPs). We further study the `correct letter' category of attention heads aiming to understand the semantics of their features, with mixed results. For normal multiple-choice question answers, we significantly compress the query, key and value subspaces of the head without loss of performance when operating on the answer labels for multiple-choice questions, and we show that the query and key subspaces represent an `Nth item in an enumeration' feature to at least some extent. However, when we attempt to use this explanation to understand the heads' behaviour on a more general distribution including randomized answer labels, we find that it is only a partial explanation, suggesting there is more to learn about the operation of `correct letter' heads on multiple choice question answering.
Tracr: Compiled Transformers as a Laboratory for Interpretability
Jan 12, 2023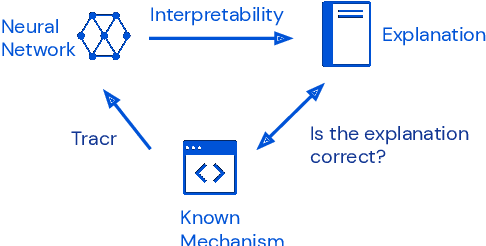
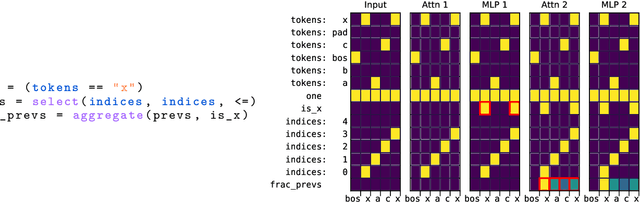
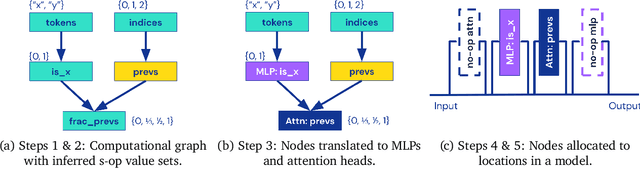
Interpretability research aims to build tools for understanding machine learning (ML) models. However, such tools are inherently hard to evaluate because we do not have ground truth information about how ML models actually work. In this work, we propose to build transformer models manually as a testbed for interpretability research. We introduce Tracr, a "compiler" for translating human-readable programs into weights of a transformer model. Tracr takes code written in RASP, a domain-specific language (Weiss et al. 2021), and translates it into weights for a standard, decoder-only, GPT-like transformer architecture. We use Tracr to create a range of ground truth transformers that implement programs including computing token frequencies, sorting, and Dyck-n parenthesis checking, among others. To enable the broader research community to explore and use compiled models, we provide an open-source implementation of Tracr at https://github.com/deepmind/tracr.
Safe Deep RL in 3D Environments using Human Feedback
Jan 21, 2022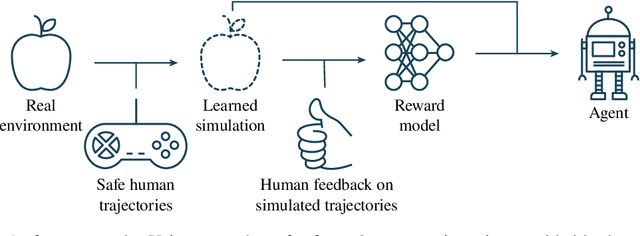

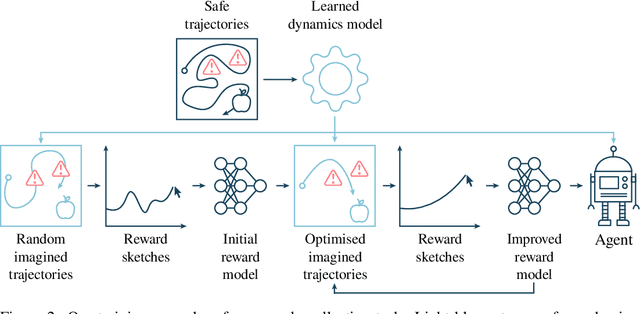
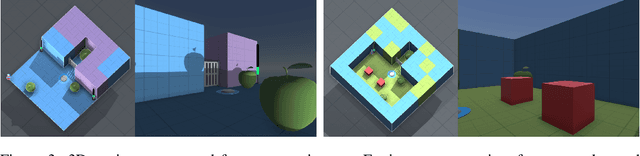
Agents should avoid unsafe behaviour during both training and deployment. This typically requires a simulator and a procedural specification of unsafe behaviour. Unfortunately, a simulator is not always available, and procedurally specifying constraints can be difficult or impossible for many real-world tasks. A recently introduced technique, ReQueST, aims to solve this problem by learning a neural simulator of the environment from safe human trajectories, then using the learned simulator to efficiently learn a reward model from human feedback. However, it is yet unknown whether this approach is feasible in complex 3D environments with feedback obtained from real humans - whether sufficient pixel-based neural simulator quality can be achieved, and whether the human data requirements are viable in terms of both quantity and quality. In this paper we answer this question in the affirmative, using ReQueST to train an agent to perform a 3D first-person object collection task using data entirely from human contractors. We show that the resulting agent exhibits an order of magnitude reduction in unsafe behaviour compared to standard reinforcement learning.
An Extensible Interactive Interface for Agent Design
Jun 10, 2019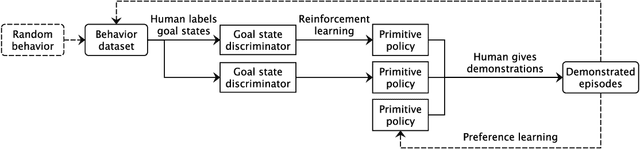
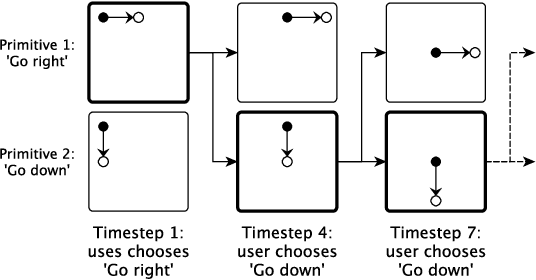
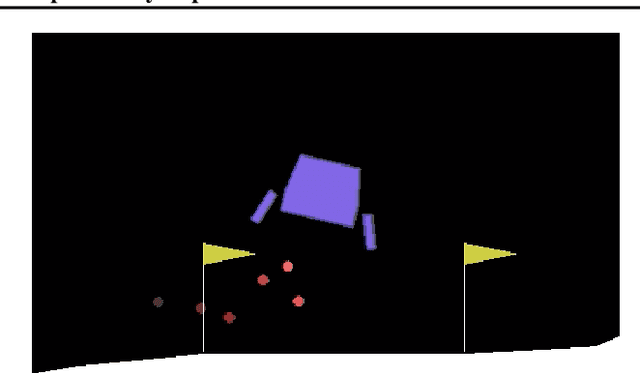
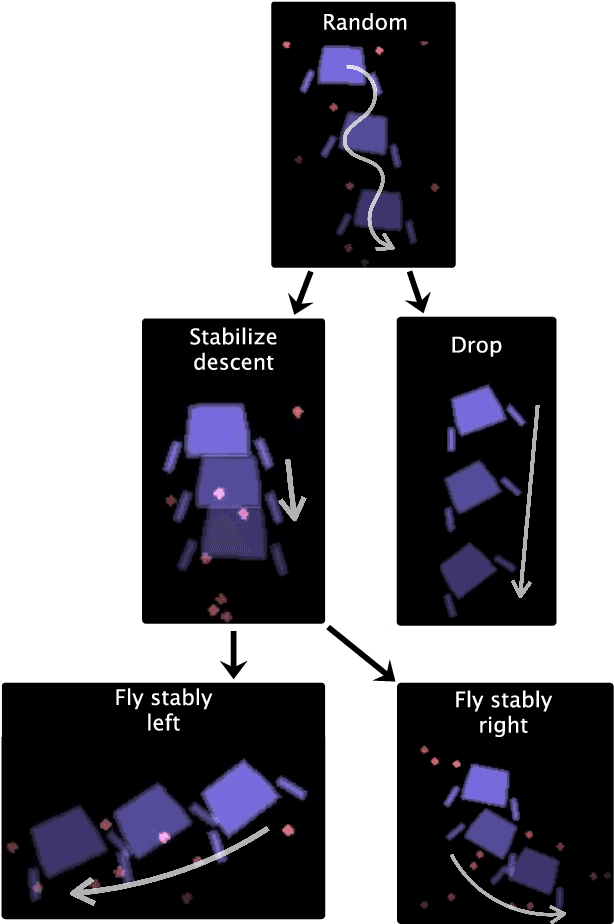
In artificial intelligence, we often specify tasks through a reward function. While this works well in some settings, many tasks are hard to specify this way. In deep reinforcement learning, for example, directly specifying a reward as a function of a high-dimensional observation is challenging. Instead, we present an interface for specifying tasks interactively using demonstrations. Our approach defines a set of increasingly complex policies. The interface allows the user to switch between these policies at fixed intervals to generate demonstrations of novel, more complex, tasks. We train new policies based on these demonstrations and repeat the process. We present a case study of our approach in the Lunar Lander domain, and show that this simple approach can quickly learn a successful landing policy and outperforms an existing comparison-based deep RL method.