 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKoray Kavukcuoglu
RecurrentGemma: Moving Past Transformers for Efficient Open Language Models
Apr 11, 2024
We introduce RecurrentGemma, an open language model which uses Google's novel Griffin architecture. Griffin combines linear recurrences with local attention to achieve excellent performance on language. It has a fixed-sized state, which reduces memory use and enables efficient inference on long sequences. We provide a pre-trained model with 2B non-embedding parameters, and an instruction tuned variant. Both models achieve comparable performance to Gemma-2B despite being trained on fewer tokens.
Gemma: Open Models Based on Gemini Research and Technology
Mar 13, 2024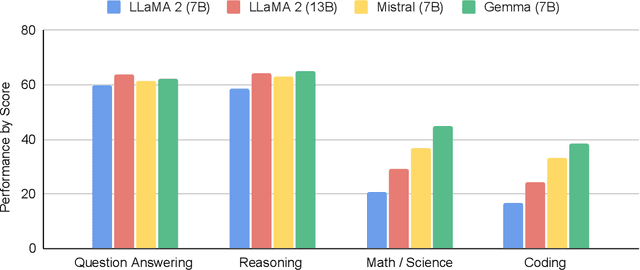

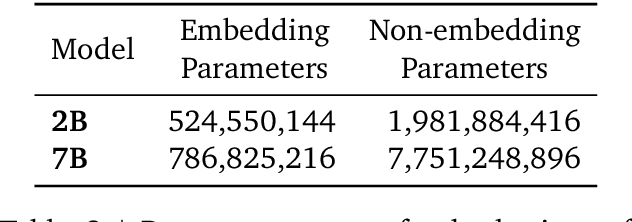
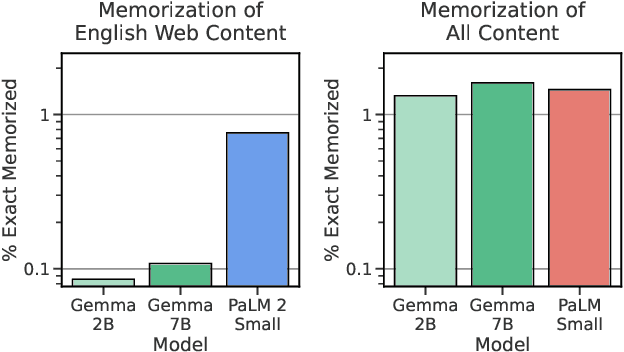
This work introduces Gemma, a family of lightweight, state-of-the art open models built from the research and technology used to create Gemini models. Gemma models demonstrate strong performance across academic benchmarks for language understanding, reasoning, and safety. We release two sizes of models (2 billion and 7 billion parameters), and provide both pretrained and fine-tuned checkpoints. Gemma outperforms similarly sized open models on 11 out of 18 text-based tasks, and we present comprehensive evaluations of safety and responsibility aspects of the models, alongside a detailed description of model development. We believe the responsible release of LLMs is critical for improving the safety of frontier models, and for enabling the next wave of LLM innovations.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Improving alignment of dialogue agents via targeted human judgements
Sep 28, 2022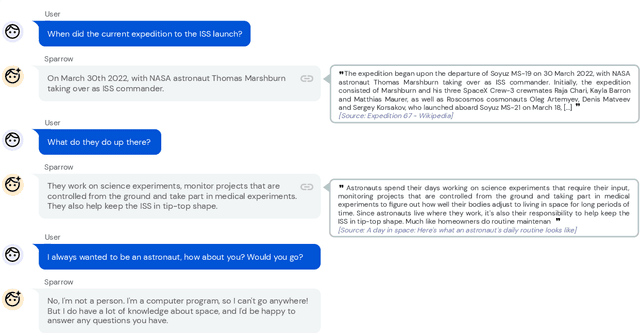

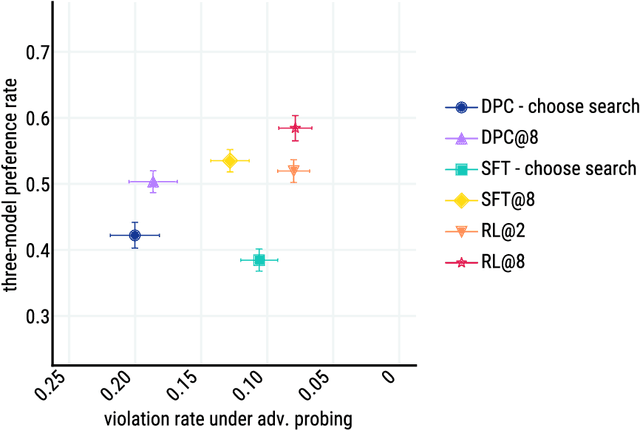
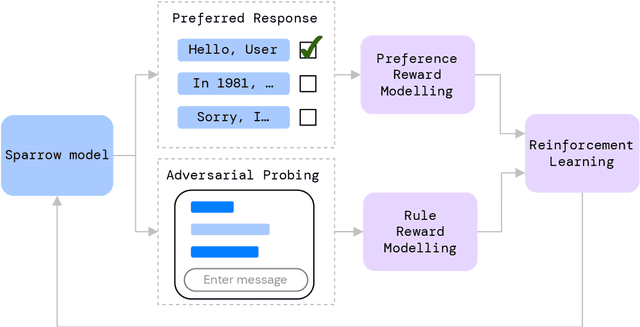
We present Sparrow, an information-seeking dialogue agent trained to be more helpful, correct, and harmless compared to prompted language model baselines. We use reinforcement learning from human feedback to train our models with two new additions to help human raters judge agent behaviour. First, to make our agent more helpful and harmless, we break down the requirements for good dialogue into natural language rules the agent should follow, and ask raters about each rule separately. We demonstrate that this breakdown enables us to collect more targeted human judgements of agent behaviour and allows for more efficient rule-conditional reward models. Second, our agent provides evidence from sources supporting factual claims when collecting preference judgements over model statements. For factual questions, evidence provided by Sparrow supports the sampled response 78% of the time. Sparrow is preferred more often than baselines while being more resilient to adversarial probing by humans, violating our rules only 8% of the time when probed. Finally, we conduct extensive analyses showing that though our model learns to follow our rules it can exhibit distributional biases.
Unified Scaling Laws for Routed Language Models
Feb 09, 2022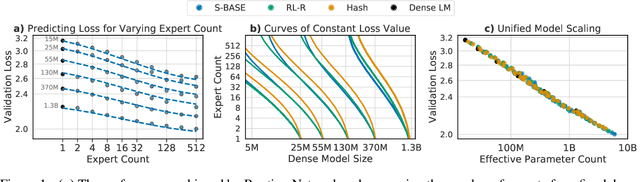

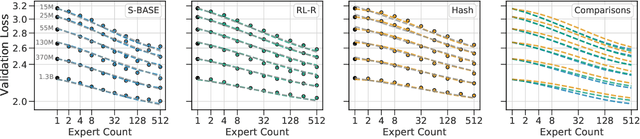
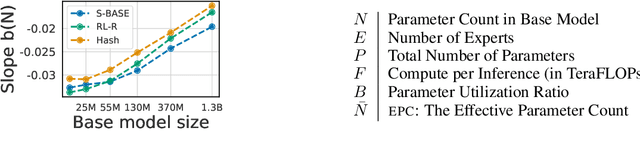
The performance of a language model has been shown to be effectively modeled as a power-law in its parameter count. Here we study the scaling behaviors of Routing Networks: architectures that conditionally use only a subset of their parameters while processing an input. For these models, parameter count and computational requirement form two independent axes along which an increase leads to better performance. In this work we derive and justify scaling laws defined on these two variables which generalize those known for standard language models and describe the performance of a wide range of routing architectures trained via three different techniques. Afterwards we provide two applications of these laws: first deriving an Effective Parameter Count along which all models scale at the same rate, and then using the scaling coefficients to give a quantitative comparison of the three routing techniques considered. Our analysis derives from an extensive evaluation of Routing Networks across five orders of magnitude of size, including models with hundreds of experts and hundreds of billions of parameters.
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Dec 08, 2021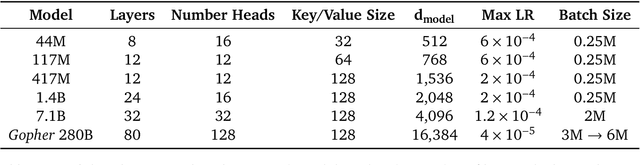
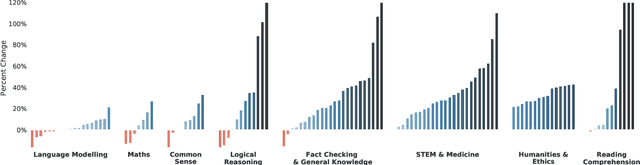
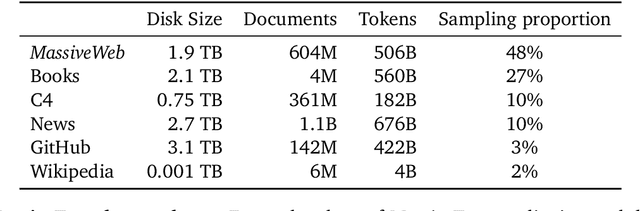
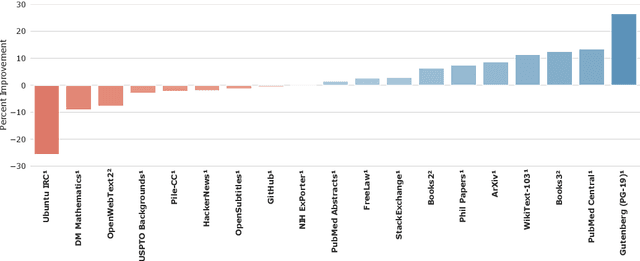
Language modelling provides a step towards intelligent communication systems by harnessing large repositories of written human knowledge to better predict and understand the world. In this paper, we present an analysis of Transformer-based language model performance across a wide range of model scales -- from models with tens of millions of parameters up to a 280 billion parameter model called Gopher. These models are evaluated on 152 diverse tasks, achieving state-of-the-art performance across the majority. Gains from scale are largest in areas such as reading comprehension, fact-checking, and the identification of toxic language, but logical and mathematical reasoning see less benefit. We provide a holistic analysis of the training dataset and model's behaviour, covering the intersection of model scale with bias and toxicity. Finally we discuss the application of language models to AI safety and the mitigation of downstream harms.
Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning
Jun 13, 2020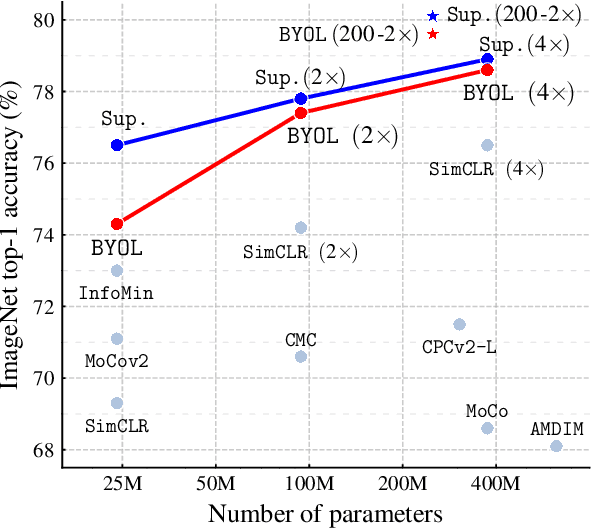

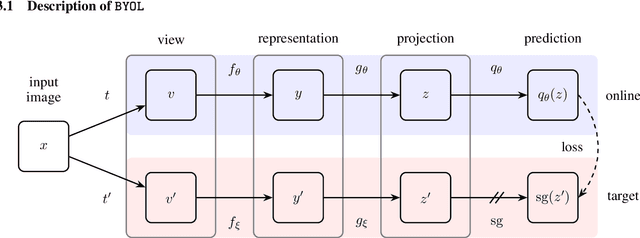
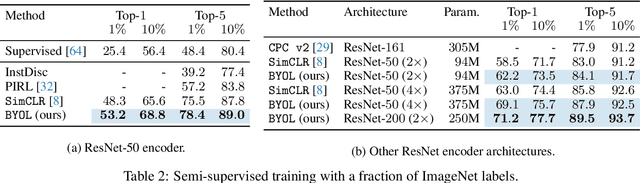
We introduce Bootstrap Your Own Latent (BYOL), a new approach to self-supervised image representation learning. BYOL relies on two neural networks, referred to as online and target networks, that interact and learn from each other. From an augmented view of an image, we train the online network to predict the target network representation of the same image under a different augmented view. At the same time, we update the target network with a slow-moving average of the online network. While state-of-the art methods intrinsically rely on negative pairs, BYOL achieves a new state of the art without them. BYOL reaches $74.3\%$ top-1 classification accuracy on ImageNet using the standard linear evaluation protocol with a ResNet-50 architecture and $79.6\%$ with a larger ResNet. We show that BYOL performs on par or better than the current state of the art on both transfer and semi-supervised benchmarks.
The StreetLearn Environment and Dataset
Mar 04, 2019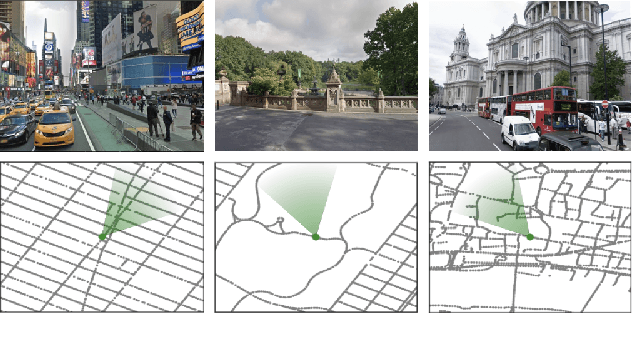
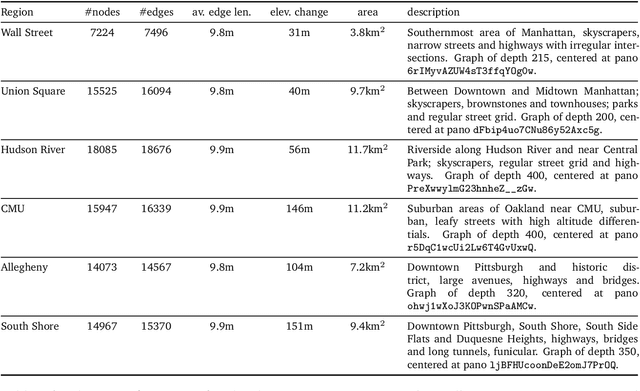
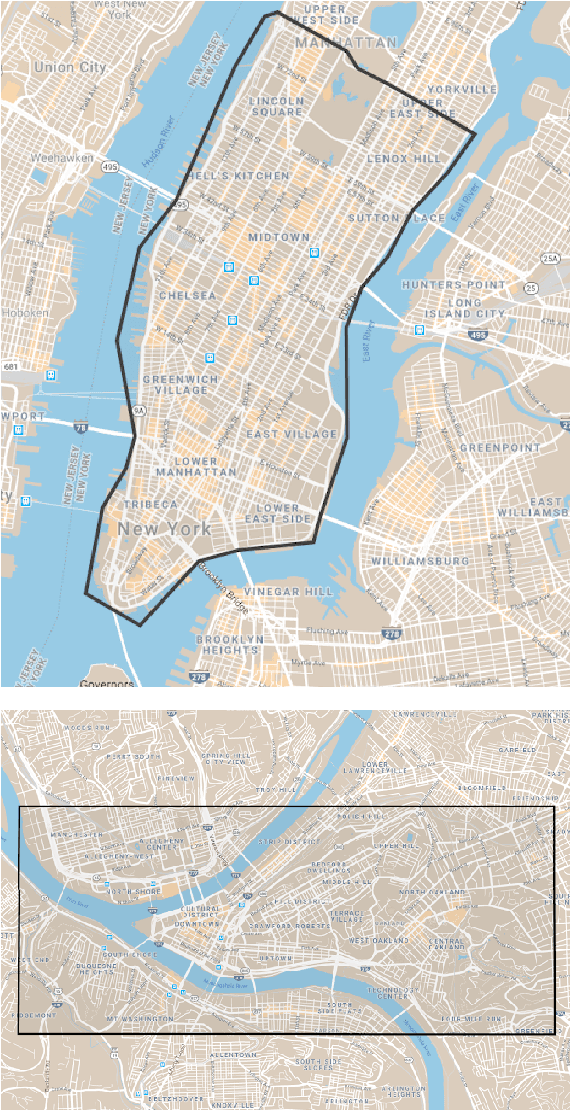
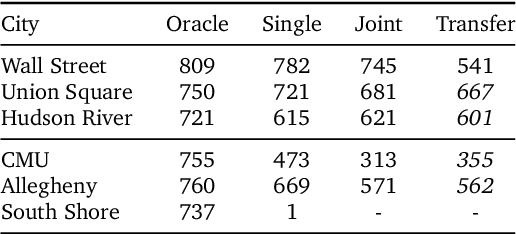
Navigation is a rich and well-grounded problem domain that drives progress in many different areas of research: perception, planning, memory, exploration, and optimisation in particular. Historically these challenges have been separately considered and solutions built that rely on stationary datasets - for example, recorded trajectories through an environment. These datasets cannot be used for decision-making and reinforcement learning, however, and in general the perspective of navigation as an interactive learning task, where the actions and behaviours of a learning agent are learned simultaneously with the perception and planning, is relatively unsupported. Thus, existing navigation benchmarks generally rely on static datasets (Geiger et al., 2013; Kendall et al., 2015) or simulators (Beattie et al., 2016; Shah et al., 2018). To support and validate research in end-to-end navigation, we present StreetLearn: an interactive, first-person, partially-observed visual environment that uses Google Street View for its photographic content and broad coverage, and give performance baselines for a challenging goal-driven navigation task. The environment code, baseline agent code, and the dataset are available at http://streetlearn.cc
Human-level performance in first-person multiplayer games with population-based deep reinforcement learning
Jul 03, 2018Recent progress in artificial intelligence through reinforcement learning (RL) has shown great success on increasingly complex single-agent environments and two-player turn-based games. However, the real-world contains multiple agents, each learning and acting independently to cooperate and compete with other agents, and environments reflecting this degree of complexity remain an open challenge. In this work, we demonstrate for the first time that an agent can achieve human-level in a popular 3D multiplayer first-person video game, Quake III Arena Capture the Flag, using only pixels and game points as input. These results were achieved by a novel two-tier optimisation process in which a population of independent RL agents are trained concurrently from thousands of parallel matches with agents playing in teams together and against each other on randomly generated environments. Each agent in the population learns its own internal reward signal to complement the sparse delayed reward from winning, and selects actions using a novel temporally hierarchical representation that enables the agent to reason at multiple timescales. During game-play, these agents display human-like behaviours such as navigating, following, and defending based on a rich learned representation that is shown to encode high-level game knowledge. In an extensive tournament-style evaluation the trained agents exceeded the win-rate of strong human players both as teammates and opponents, and proved far stronger than existing state-of-the-art agents. These results demonstrate a significant jump in the capabilities of artificial agents, bringing us closer to the goal of human-level intelligence.