 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmir Globerson
EgoPet: Egomotion and Interaction Data from an Animal's Perspective
Apr 15, 2024
Animals perceive the world to plan their actions and interact with other agents to accomplish complex tasks, demonstrating capabilities that are still unmatched by AI systems. To advance our understanding and reduce the gap between the capabilities of animals and AI systems, we introduce a dataset of pet egomotion imagery with diverse examples of simultaneous egomotion and multi-agent interaction. Current video datasets separately contain egomotion and interaction examples, but rarely both at the same time. In addition, EgoPet offers a radically distinct perspective from existing egocentric datasets of humans or vehicles. We define two in-domain benchmark tasks that capture animal behavior, and a third benchmark to assess the utility of EgoPet as a pretraining resource to robotic quadruped locomotion, showing that models trained from EgoPet outperform those trained from prior datasets.
Finding Visual Task Vectors
Apr 08, 2024Visual Prompting is a technique for teaching models to perform a visual task via in-context examples, without any additional training. In this work, we analyze the activations of MAE-VQGAN, a recent Visual Prompting model, and find task vectors, activations that encode task-specific information. Equipped with this insight, we demonstrate that it is possible to identify the task vectors and use them to guide the network towards performing different tasks without providing any input-output examples. To find task vectors, we compute the average intermediate activations per task and use the REINFORCE algorithm to search for the subset of task vectors. The resulting task vectors guide the model towards performing a task better than the original model without the need for input-output examples.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Implicit Bias of Policy Gradient in Linear Quadratic Control: Extrapolation to Unseen Initial States
Feb 12, 2024In modern machine learning, models can often fit training data in numerous ways, some of which perform well on unseen (test) data, while others do not. Remarkably, in such cases gradient descent frequently exhibits an implicit bias that leads to excellent performance on unseen data. This implicit bias was extensively studied in supervised learning, but is far less understood in optimal control (reinforcement learning). There, learning a controller applied to a system via gradient descent is known as policy gradient, and a question of prime importance is the extent to which a learned controller extrapolates to unseen initial states. This paper theoretically studies the implicit bias of policy gradient in terms of extrapolation to unseen initial states. Focusing on the fundamental Linear Quadratic Regulator (LQR) problem, we establish that the extent of extrapolation depends on the degree of exploration induced by the system when commencing from initial states included in training. Experiments corroborate our theory, and demonstrate its conclusions on problems beyond LQR, where systems are non-linear and controllers are neural networks. We hypothesize that real-world optimal control may be greatly improved by developing methods for informed selection of initial states to train on.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
In-Context Learning Creates Task Vectors
Oct 24, 2023

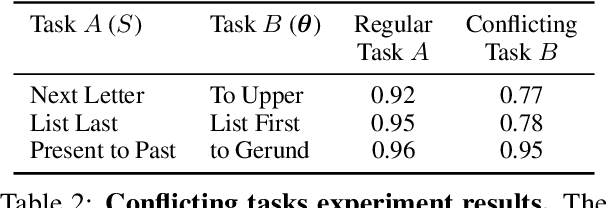
In-context learning (ICL) in Large Language Models (LLMs) has emerged as a powerful new learning paradigm. However, its underlying mechanism is still not well understood. In particular, it is challenging to map it to the "standard" machine learning framework, where one uses a training set $S$ to find a best-fitting function $f(x)$ in some hypothesis class. Here we make progress on this problem by showing that the functions learned by ICL often have a very simple structure: they correspond to the transformer LLM whose only inputs are the query $x$ and a single "task vector" calculated from the training set. Thus, ICL can be seen as compressing $S$ into a single task vector $\boldsymbol{\theta}(S)$ and then using this task vector to modulate the transformer to produce the output. We support the above claim via comprehensive experiments across a range of models and tasks.
Graph Neural Networks Use Graphs When They Shouldn't
Sep 08, 2023Predictions over graphs play a crucial role in various domains, including social networks, molecular biology, medicine, and more. Graph Neural Networks (GNNs) have emerged as the dominant approach for learning on graph data. Instances of graph labeling problems consist of the graph-structure (i.e., the adjacency matrix), along with node-specific feature vectors. In some cases, this graph-structure is non-informative for the predictive task. For instance, molecular properties such as molar mass depend solely on the constituent atoms (node features), and not on the molecular structure. While GNNs have the ability to ignore the graph-structure in such cases, it is not clear that they will. In this work, we show that GNNs actually tend to overfit the graph-structure in the sense that they use it even when a better solution can be obtained by ignoring it. We examine this phenomenon with respect to different graph distributions and find that regular graphs are more robust to this overfitting. We then provide a theoretical explanation for this phenomenon, via analyzing the implicit bias of gradient-descent-based learning of GNNs in this setting. Finally, based on our empirical and theoretical findings, we propose a graph-editing method to mitigate the tendency of GNNs to overfit graph-structures that should be ignored. We show that this method indeed improves the accuracy of GNNs across multiple benchmarks.
Predicting masked tokens in stochastic locations improves masked image modeling
Jul 31, 2023
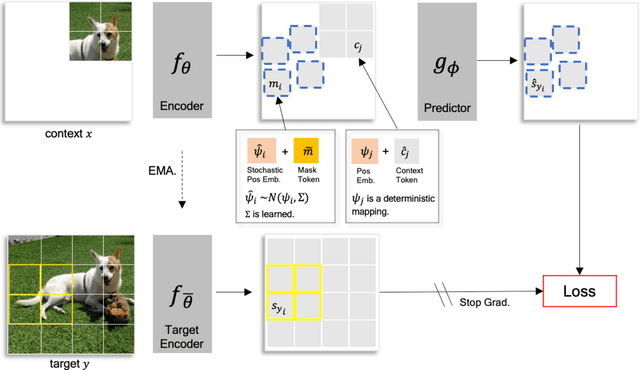
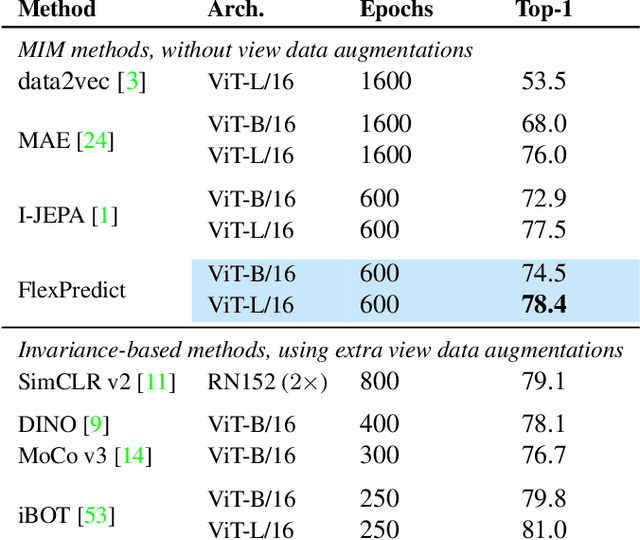
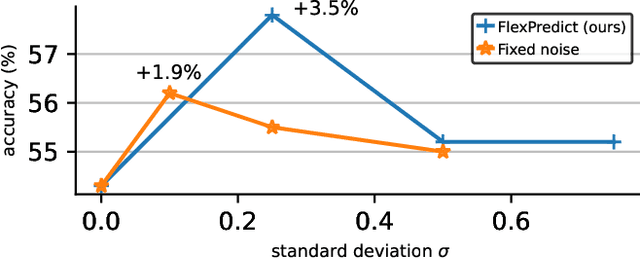
Self-supervised learning is a promising paradigm in deep learning that enables learning from unlabeled data by constructing pretext tasks that require learning useful representations. In natural language processing, the dominant pretext task has been masked language modeling (MLM), while in computer vision there exists an equivalent called Masked Image Modeling (MIM). However, MIM is challenging because it requires predicting semantic content in accurate locations. E.g, given an incomplete picture of a dog, we can guess that there is a tail, but we cannot determine its exact location. In this work, we propose FlexPredict, a stochastic model that addresses this challenge by incorporating location uncertainty into the model. Specifically, we condition the model on stochastic masked token positions to guide the model toward learning features that are more robust to location uncertainties. Our approach improves downstream performance on a range of tasks, e.g, compared to MIM baselines, FlexPredict boosts ImageNet linear probing by 1.6% with ViT-B and by 2.5% for semi-supervised video segmentation using ViT-L.
Evaluating the Ripple Effects of Knowledge Editing in Language Models
Jul 24, 2023Modern language models capture a large body of factual knowledge. However, some facts can be incorrectly induced or become obsolete over time, resulting in factually incorrect generations. This has led to the development of various editing methods that allow updating facts encoded by the model. Evaluation of these methods has primarily focused on testing whether an individual fact has been successfully injected, and if similar predictions for other subjects have not changed. Here we argue that such evaluation is limited, since injecting one fact (e.g. ``Jack Depp is the son of Johnny Depp'') introduces a ``ripple effect'' in the form of additional facts that the model needs to update (e.g.``Jack Depp is the sibling of Lily-Rose Depp''). To address this issue, we propose a novel set of evaluation criteria that consider the implications of an edit on related facts. Using these criteria, we then construct \ripple{}, a diagnostic benchmark of 5K factual edits, capturing a variety of types of ripple effects. We evaluate prominent editing methods on \ripple{}, showing that current methods fail to introduce consistent changes in the model's knowledge. In addition, we find that a simple in-context editing baseline obtains the best scores on our benchmark, suggesting a promising research direction for model editing.
Covering Uncommon Ground: Gap-Focused Question Generation for Answer Assessment
Jul 06, 2023
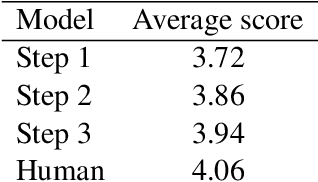
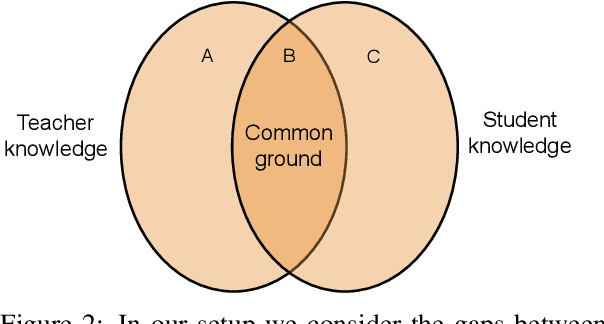

Human communication often involves information gaps between the interlocutors. For example, in an educational dialogue, a student often provides an answer that is incomplete, and there is a gap between this answer and the perfect one expected by the teacher. Successful dialogue then hinges on the teacher asking about this gap in an effective manner, thus creating a rich and interactive educational experience. We focus on the problem of generating such gap-focused questions (GFQs) automatically. We define the task, highlight key desired aspects of a good GFQ, and propose a model that satisfies these. Finally, we provide an evaluation by human annotators of our generated questions compared against human generated ones, demonstrating competitive performance.