 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGarrett Tanzer
DOCCI: Descriptions of Connected and Contrasting Images
Apr 30, 2024
Vision-language datasets are vital for both text-to-image (T2I) and image-to-text (I2T) research. However, current datasets lack descriptions with fine-grained detail that would allow for richer associations to be learned by models. To fill the gap, we introduce Descriptions of Connected and Contrasting Images (DOCCI), a dataset with long, human-annotated English descriptions for 15k images that were taken, curated and donated by a single researcher intent on capturing key challenges such as spatial relations, counting, text rendering, world knowledge, and more. We instruct human annotators to create comprehensive descriptions for each image; these average 136 words in length and are crafted to clearly distinguish each image from those that are related or similar. Each description is highly compositional and typically encompasses multiple challenges. Through both quantitative and qualitative analyses, we demonstrate that DOCCI serves as an effective training resource for image-to-text generation -- a PaLI 5B model finetuned on DOCCI shows equal or superior results compared to highly-performant larger models like LLaVA-1.5 7B and InstructBLIP 7B. Furthermore, we show that DOCCI is a useful testbed for text-to-image generation, highlighting the limitations of current text-to-image models in capturing long descriptions and fine details.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
A Benchmark for Learning to Translate a New Language from One Grammar Book
Sep 28, 2023Large language models (LLMs) can perform impressive feats with in-context learning or lightweight finetuning. It is natural to wonder how well these models adapt to genuinely new tasks, but how does one find tasks that are unseen in internet-scale training sets? We turn to a field that is explicitly motivated and bottlenecked by a scarcity of web data: low-resource languages. In this paper, we introduce MTOB (Machine Translation from One Book), a benchmark for learning to translate between English and Kalamang -- a language with less than 200 speakers and therefore virtually no presence on the web -- using several hundred pages of field linguistics reference materials. This task framing is novel in that it asks a model to learn a language from a single human-readable book of grammar explanations, rather than a large mined corpus of in-domain data, more akin to L2 learning than L1 acquisition. We demonstrate that baselines using current LLMs are promising but fall short of human performance, achieving 44.7 chrF on Kalamang to English translation and 45.8 chrF on English to Kalamang translation, compared to 51.6 and 57.0 chrF by a human who learned Kalamang from the same reference materials. We hope that MTOB will help measure LLM capabilities along a new dimension, and that the methods developed to solve it could help expand access to language technology for underserved communities by leveraging qualitatively different kinds of data than traditional machine translation.
YouTube-ASL: A Large-Scale, Open-Domain American Sign Language-English Parallel Corpus
Jun 27, 2023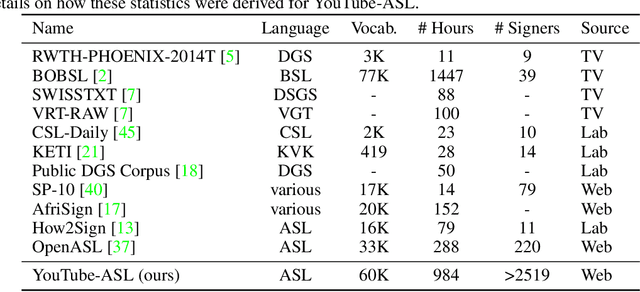
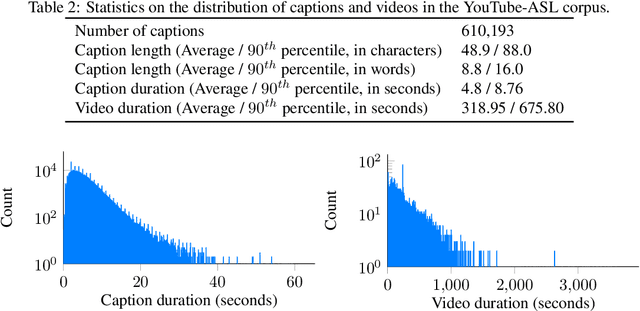
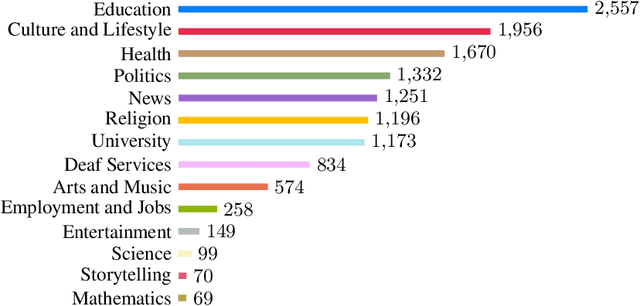
Machine learning for sign languages is bottlenecked by data. In this paper, we present YouTube-ASL, a large-scale, open-domain corpus of American Sign Language (ASL) videos and accompanying English captions drawn from YouTube. With ~1000 hours of videos and >2500 unique signers, YouTube-ASL is ~3x as large and has ~10x as many unique signers as the largest prior ASL dataset. We train baseline models for ASL to English translation on YouTube-ASL and evaluate them on How2Sign, where we achieve a new finetuned state of the art of 12.39 BLEU and, for the first time, report zero-shot results.