 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJaemin Cho
DOCCI: Descriptions of Connected and Contrasting Images
Apr 30, 2024
Vision-language datasets are vital for both text-to-image (T2I) and image-to-text (I2T) research. However, current datasets lack descriptions with fine-grained detail that would allow for richer associations to be learned by models. To fill the gap, we introduce Descriptions of Connected and Contrasting Images (DOCCI), a dataset with long, human-annotated English descriptions for 15k images that were taken, curated and donated by a single researcher intent on capturing key challenges such as spatial relations, counting, text rendering, world knowledge, and more. We instruct human annotators to create comprehensive descriptions for each image; these average 136 words in length and are crafted to clearly distinguish each image from those that are related or similar. Each description is highly compositional and typically encompasses multiple challenges. Through both quantitative and qualitative analyses, we demonstrate that DOCCI serves as an effective training resource for image-to-text generation -- a PaLI 5B model finetuned on DOCCI shows equal or superior results compared to highly-performant larger models like LLaVA-1.5 7B and InstructBLIP 7B. Furthermore, we show that DOCCI is a useful testbed for text-to-image generation, highlighting the limitations of current text-to-image models in capturing long descriptions and fine details.
Ctrl-Adapter: An Efficient and Versatile Framework for Adapting Diverse Controls to Any Diffusion Model
Apr 15, 2024ControlNets are widely used for adding spatial control in image generation with different conditions, such as depth maps, canny edges, and human poses. However, there are several challenges when leveraging the pretrained image ControlNets for controlled video generation. First, pretrained ControlNet cannot be directly plugged into new backbone models due to the mismatch of feature spaces, and the cost of training ControlNets for new backbones is a big burden. Second, ControlNet features for different frames might not effectively handle the temporal consistency. To address these challenges, we introduce Ctrl-Adapter, an efficient and versatile framework that adds diverse controls to any image/video diffusion models, by adapting pretrained ControlNets (and improving temporal alignment for videos). Ctrl-Adapter provides diverse capabilities including image control, video control, video control with sparse frames, multi-condition control, compatibility with different backbones, adaptation to unseen control conditions, and video editing. In Ctrl-Adapter, we train adapter layers that fuse pretrained ControlNet features to different image/video diffusion models, while keeping the parameters of the ControlNets and the diffusion models frozen. Ctrl-Adapter consists of temporal and spatial modules so that it can effectively handle the temporal consistency of videos. We also propose latent skipping and inverse timestep sampling for robust adaptation and sparse control. Moreover, Ctrl-Adapter enables control from multiple conditions by simply taking the (weighted) average of ControlNet outputs. With diverse image/video diffusion backbones (SDXL, Hotshot-XL, I2VGen-XL, and SVD), Ctrl-Adapter matches ControlNet for image control and outperforms all baselines for video control (achieving the SOTA accuracy on the DAVIS 2017 dataset) with significantly lower computational costs (less than 10 GPU hours).
Rethinking Interactive Image Segmentation with Low Latency, High Quality, and Diverse Prompts
Mar 31, 2024The goal of interactive image segmentation is to delineate specific regions within an image via visual or language prompts. Low-latency and high-quality interactive segmentation with diverse prompts remain challenging for existing specialist and generalist models. Specialist models, with their limited prompts and task-specific designs, experience high latency because the image must be recomputed every time the prompt is updated, due to the joint encoding of image and visual prompts. Generalist models, exemplified by the Segment Anything Model (SAM), have recently excelled in prompt diversity and efficiency, lifting image segmentation to the foundation model era. However, for high-quality segmentations, SAM still lags behind state-of-the-art specialist models despite SAM being trained with x100 more segmentation masks. In this work, we delve deep into the architectural differences between the two types of models. We observe that dense representation and fusion of visual prompts are the key design choices contributing to the high segmentation quality of specialist models. In light of this, we reintroduce this dense design into the generalist models, to facilitate the development of generalist models with high segmentation quality. To densely represent diverse visual prompts, we propose to use a dense map to capture five types: clicks, boxes, polygons, scribbles, and masks. Thus, we propose SegNext, a next-generation interactive segmentation approach offering low latency, high quality, and diverse prompt support. Our method outperforms current state-of-the-art methods on HQSeg-44K and DAVIS, both quantitatively and qualitatively.
EnvGen: Generating and Adapting Environments via LLMs for Training Embodied Agents
Mar 18, 2024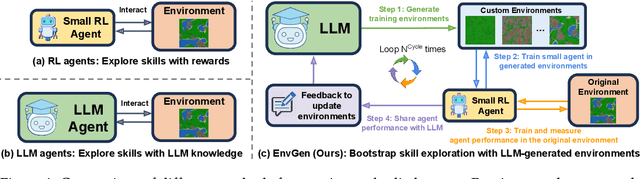

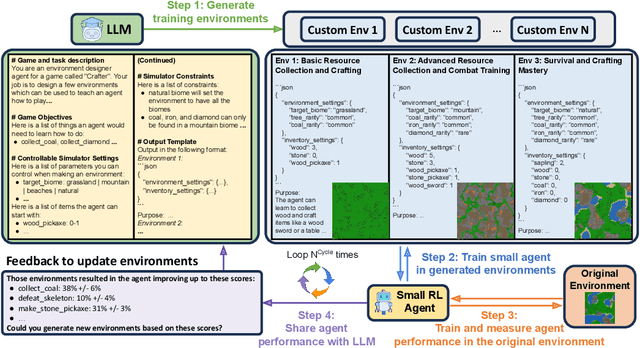

Recent SOTA approaches for embodied learning via interaction directly employ large language models (LLMs) as agents to determine the next steps in an environment. Due to their world knowledge and reasoning capabilities, LLM agents achieve stronger performance than previous smaller agents based on reinforcement learning (RL); however, frequently calling LLMs is slow and expensive. Instead of directly employing LLMs as agents, can we use LLMs' reasoning capabilities to adaptively create training environments to help smaller embodied RL agents learn useful skills that they are weak at? We propose EnvGen, a novel framework to address this question. First, we prompt an LLM to generate training environments that allow agents to quickly learn different tasks in parallel. Concretely, the LLM is given the task description and simulator objectives that the agents should learn and is then asked to generate a set of environment configurations (e.g., different terrains, items given to agents, etc.). Next, we train a small RL agent in a mixture of the original and LLM-generated environments. Then, we enable the LLM to continuously adapt the generated environments to progressively improve the skills that the agent is weak at, by providing feedback to the LLM in the form of the agent's performance. We demonstrate the usefulness of EnvGen with comprehensive experiments in Crafter and Heist environments. We find that a small RL agent trained with EnvGen can outperform SOTA methods, including a GPT-4 agent, and learns long-horizon tasks significantly faster. We show qualitatively how the LLM adapts training environments to help improve RL agents' weaker skills over time. Additionally, EnvGen is substantially more efficient as it only uses a small number of LLM calls (e.g., 4 in total), whereas LLM agents require thousands of LLM calls. Lastly, we present detailed ablation studies for our design choices.
SELMA: Learning and Merging Skill-Specific Text-to-Image Experts with Auto-Generated Data
Mar 11, 2024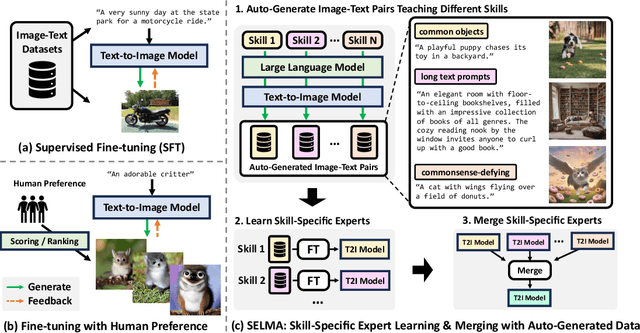
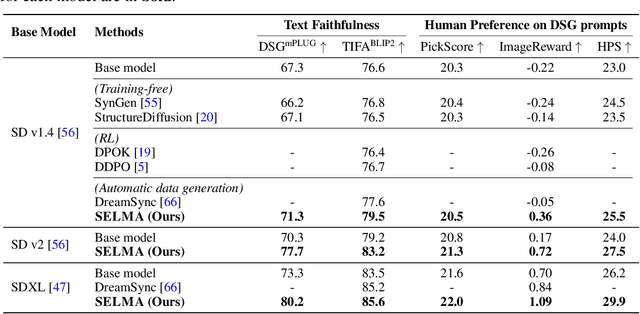
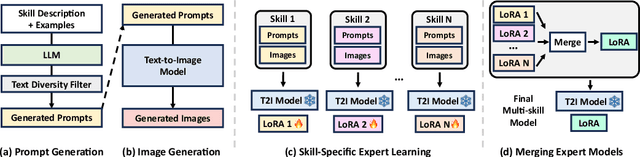
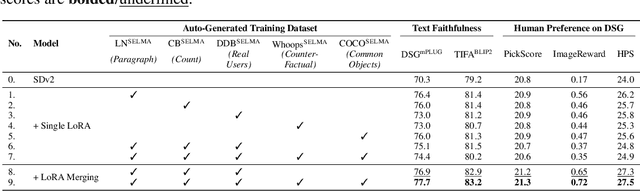
Recent text-to-image (T2I) generation models have demonstrated impressive capabilities in creating images from text descriptions. However, these T2I generation models often fall short of generating images that precisely match the details of the text inputs, such as incorrect spatial relationship or missing objects. In this paper, we introduce SELMA: Skill-Specific Expert Learning and Merging with Auto-Generated Data, a novel paradigm to improve the faithfulness of T2I models by fine-tuning models on automatically generated, multi-skill image-text datasets, with skill-specific expert learning and merging. First, SELMA leverages an LLM's in-context learning capability to generate multiple datasets of text prompts that can teach different skills, and then generates the images with a T2I model based on the prompts. Next, SELMA adapts the T2I model to the new skills by learning multiple single-skill LoRA (low-rank adaptation) experts followed by expert merging. Our independent expert fine-tuning specializes multiple models for different skills, and expert merging helps build a joint multi-skill T2I model that can generate faithful images given diverse text prompts, while mitigating the knowledge conflict from different datasets. We empirically demonstrate that SELMA significantly improves the semantic alignment and text faithfulness of state-of-the-art T2I diffusion models on multiple benchmarks (+2.1% on TIFA and +6.9% on DSG), human preference metrics (PickScore, ImageReward, and HPS), as well as human evaluation. Moreover, fine-tuning with image-text pairs auto-collected via SELMA shows comparable performance to fine-tuning with ground truth data. Lastly, we show that fine-tuning with images from a weaker T2I model can help improve the generation quality of a stronger T2I model, suggesting promising weak-to-strong generalization in T2I models.
Contrastive Region Guidance: Improving Grounding in Vision-Language Models without Training
Mar 04, 2024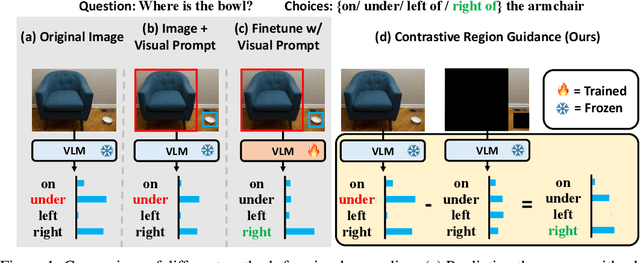
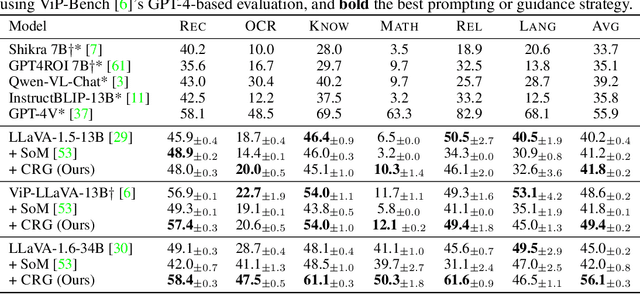
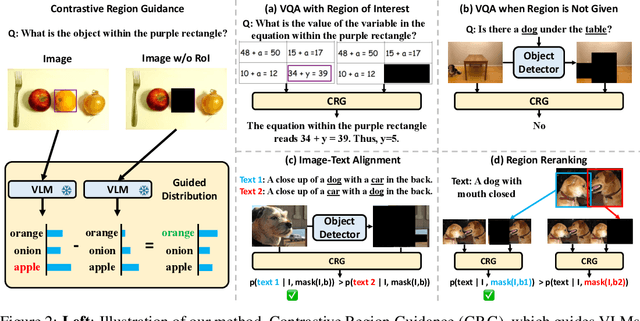
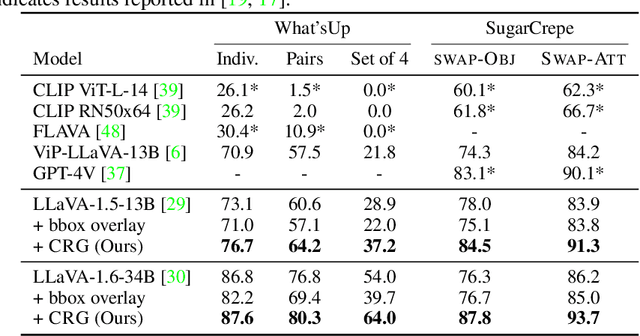
Highlighting particularly relevant regions of an image can improve the performance of vision-language models (VLMs) on various vision-language (VL) tasks by guiding the model to attend more closely to these regions of interest. For example, VLMs can be given a "visual prompt", where visual markers such as bounding boxes delineate key image regions. However, current VLMs that can incorporate visual guidance are either proprietary and expensive or require costly training on curated data that includes visual prompts. We introduce Contrastive Region Guidance (CRG), a training-free guidance method that enables open-source VLMs to respond to visual prompts. CRG contrasts model outputs produced with and without visual prompts, factoring out biases revealed by the model when answering without the information required to produce a correct answer (i.e., the model's prior). CRG achieves substantial improvements in a wide variety of VL tasks: When region annotations are provided, CRG increases absolute accuracy by up to 11.1% on ViP-Bench, a collection of six diverse region-based tasks such as recognition, math, and object relationship reasoning. We also show CRG's applicability to spatial reasoning, with 10% improvement on What'sUp, as well as to compositional generalization -- improving accuracy by 11.5% and 7.5% on two challenging splits from SugarCrepe -- and to image-text alignment for generated images, where we improve by up to 8.4 AUROC and 6.8 F1 points on SeeTRUE. When reference regions are absent, CRG allows us to re-rank proposed regions in referring expression comprehension and phrase grounding benchmarks like RefCOCO/+/g and Flickr30K Entities, with an average gain of 3.2% in accuracy. Our analysis explores alternative masking strategies for CRG, quantifies CRG's probability shift, and evaluates the role of region guidance strength, empirically validating CRG's design choices.
Davidsonian Scene Graph: Improving Reliability in Fine-grained Evaluation for Text-to-Image Generation
Oct 30, 2023Evaluating text-to-image models is notoriously difficult. A strong recent approach for assessing text-image faithfulness is based on QG/A (question generation and answering), which uses pre-trained foundational models to automatically generate a set of questions and answers from the prompt, and output images are scored based on whether these answers extracted with a visual question answering model are consistent with the prompt-based answers. This kind of evaluation is naturally dependent on the quality of the underlying QG and QA models. We identify and address several reliability challenges in existing QG/A work: (a) QG questions should respect the prompt (avoiding hallucinations, duplications, and omissions) and (b) VQA answers should be consistent (not asserting that there is no motorcycle in an image while also claiming the motorcycle is blue). We address these issues with Davidsonian Scene Graph (DSG), an empirically grounded evaluation framework inspired by formal semantics. DSG is an automatic, graph-based QG/A that is modularly implemented to be adaptable to any QG/A module. DSG produces atomic and unique questions organized in dependency graphs, which (i) ensure appropriate semantic coverage and (ii) sidestep inconsistent answers. With extensive experimentation and human evaluation on a range of model configurations (LLM, VQA, and T2I), we empirically demonstrate that DSG addresses the challenges noted above. Finally, we present DSG-1k, an open-sourced evaluation benchmark that includes 1,060 prompts, covering a wide range of fine-grained semantic categories with a balanced distribution. We release the DSG-1k prompts and the corresponding DSG questions.
DiagrammerGPT: Generating Open-Domain, Open-Platform Diagrams via LLM Planning
Oct 18, 2023Text-to-image (T2I) generation has seen significant growth over the past few years. Despite this, there has been little work on generating diagrams with T2I models. A diagram is a symbolic/schematic representation that explains information using structurally rich and spatially complex visualizations (e.g., a dense combination of related objects, text labels, directional arrows, connection lines, etc.). Existing state-of-the-art T2I models often fail at diagram generation because they lack fine-grained object layout control when many objects are densely connected via complex relations such as arrows/lines and also often fail to render comprehensible text labels. To address this gap, we present DiagrammerGPT, a novel two-stage text-to-diagram generation framework that leverages the layout guidance capabilities of LLMs (e.g., GPT-4) to generate more accurate open-domain, open-platform diagrams. In the first stage, we use LLMs to generate and iteratively refine 'diagram plans' (in a planner-auditor feedback loop) which describe all the entities (objects and text labels), their relationships (arrows or lines), and their bounding box layouts. In the second stage, we use a diagram generator, DiagramGLIGEN, and a text label rendering module to generate diagrams following the diagram plans. To benchmark the text-to-diagram generation task, we introduce AI2D-Caption, a densely annotated diagram dataset built on top of the AI2D dataset. We show quantitatively and qualitatively that our DiagrammerGPT framework produces more accurate diagrams, outperforming existing T2I models. We also provide comprehensive analysis including open-domain diagram generation, vector graphic diagram generation in different platforms, human-in-the-loop diagram plan editing, and multimodal planner/auditor LLMs (e.g., GPT-4Vision). We hope our work can inspire further research on diagram generation via T2I models and LLMs.
VideoDirectorGPT: Consistent Multi-scene Video Generation via LLM-Guided Planning
Sep 26, 2023

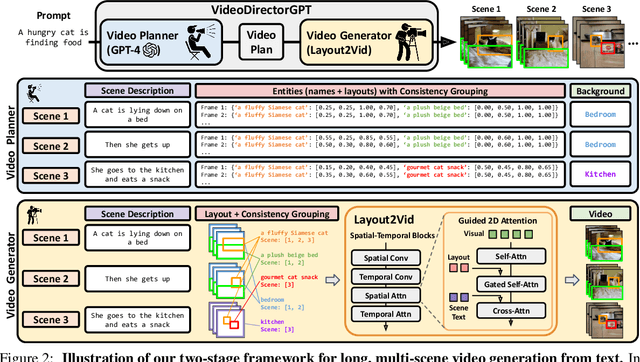
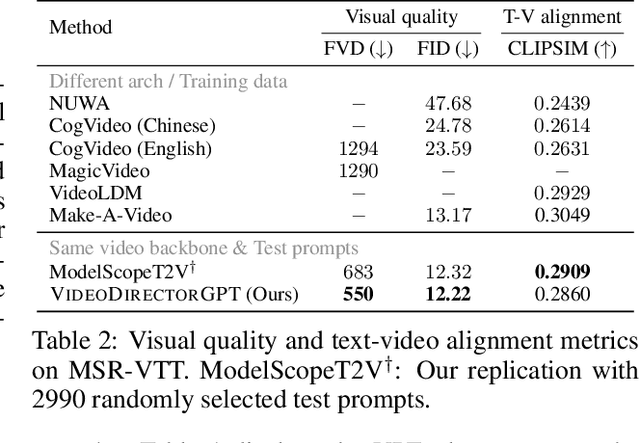
Although recent text-to-video (T2V) generation methods have seen significant advancements, most of these works focus on producing short video clips of a single event with a single background (i.e., single-scene videos). Meanwhile, recent large language models (LLMs) have demonstrated their capability in generating layouts and programs to control downstream visual modules such as image generation models. This raises an important question: can we leverage the knowledge embedded in these LLMs for temporally consistent long video generation? In this paper, we propose VideoDirectorGPT, a novel framework for consistent multi-scene video generation that uses the knowledge of LLMs for video content planning and grounded video generation. Specifically, given a single text prompt, we first ask our video planner LLM (GPT-4) to expand it into a 'video plan', which involves generating the scene descriptions, the entities with their respective layouts, the background for each scene, and consistency groupings of the entities and backgrounds. Next, guided by this output from the video planner, our video generator, Layout2Vid, has explicit control over spatial layouts and can maintain temporal consistency of entities/backgrounds across scenes, while only trained with image-level annotations. Our experiments demonstrate that VideoDirectorGPT framework substantially improves layout and movement control in both single- and multi-scene video generation and can generate multi-scene videos with visual consistency across scenes, while achieving competitive performance with SOTAs in open-domain single-scene T2V generation. We also demonstrate that our framework can dynamically control the strength for layout guidance and can also generate videos with user-provided images. We hope our framework can inspire future work on better integrating the planning ability of LLMs into consistent long video generation.
Paxion: Patching Action Knowledge in Video-Language Foundation Models
May 26, 2023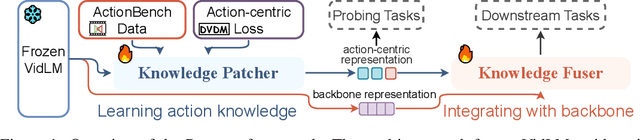

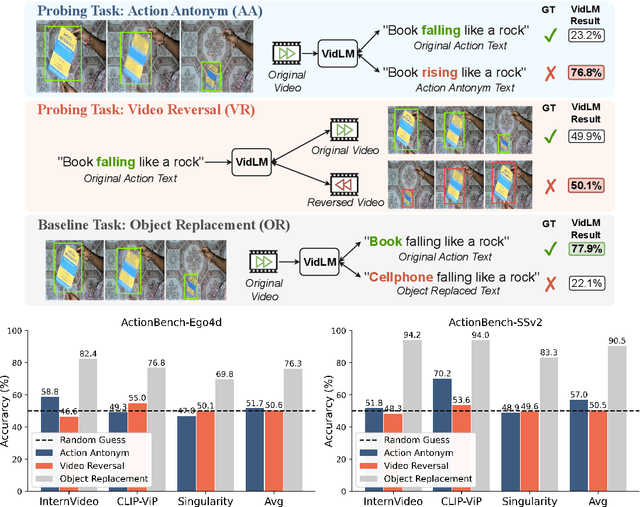

Action knowledge involves the understanding of textual, visual, and temporal aspects of actions. We introduce the Action Dynamics Benchmark (ActionBench) containing two carefully designed probing tasks: Action Antonym and Video Reversal, which targets multimodal alignment capabilities and temporal understanding skills of the model, respectively. Despite recent video-language models' (VidLM) impressive performance on various benchmark tasks, our diagnostic tasks reveal their surprising deficiency (near-random performance) in action knowledge, suggesting that current models rely on object recognition abilities as a shortcut for action understanding. To remedy this, we propose a novel framework, Paxion, along with a new Discriminative Video Dynamics Modeling (DVDM) objective. The Paxion framework utilizes a Knowledge Patcher network to encode new action knowledge and a Knowledge Fuser component to integrate the Patcher into frozen VidLMs without compromising their existing capabilities. Due to limitations of the widely-used Video-Text Contrastive (VTC) loss for learning action knowledge, we introduce the DVDM objective to train the Knowledge Patcher. DVDM forces the model to encode the correlation between the action text and the correct ordering of video frames. Our extensive analyses show that Paxion and DVDM together effectively fill the gap in action knowledge understanding (~50% to 80%), while maintaining or improving performance on a wide spectrum of both object- and action-centric downstream tasks.