 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZineng Tang
CoDi-2: In-Context, Interleaved, and Interactive Any-to-Any Generation
Nov 30, 2023
We present CoDi-2, a versatile and interactive Multimodal Large Language Model (MLLM) that can follow complex multimodal interleaved instructions, conduct in-context learning (ICL), reason, chat, edit, etc., in an any-to-any input-output modality paradigm. By aligning modalities with language for both encoding and generation, CoDi-2 empowers Large Language Models (LLMs) to not only understand complex modality-interleaved instructions and in-context examples, but also autoregressively generate grounded and coherent multimodal outputs in the continuous feature space. To train CoDi-2, we build a large-scale generation dataset encompassing in-context multimodal instructions across text, vision, and audio. CoDi-2 demonstrates a wide range of zero-shot capabilities for multimodal generation, such as in-context learning, reasoning, and compositionality of any-to-any modality generation through multi-round interactive conversation. CoDi-2 surpasses previous domain-specific models on tasks such as subject-driven image generation, vision transformation, and audio editing. CoDi-2 signifies a substantial breakthrough in developing a comprehensive multimodal foundation model adept at interpreting in-context language-vision-audio interleaved instructions and producing multimodal outputs.
Paxion: Patching Action Knowledge in Video-Language Foundation Models
May 26, 2023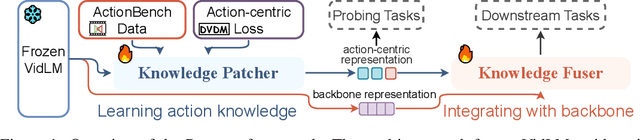

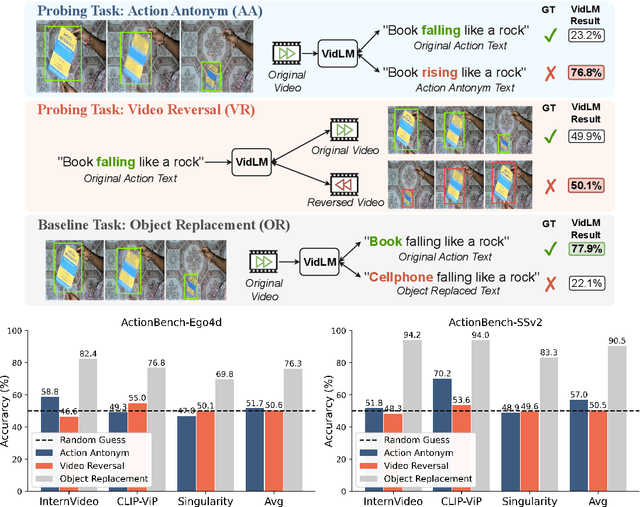

Action knowledge involves the understanding of textual, visual, and temporal aspects of actions. We introduce the Action Dynamics Benchmark (ActionBench) containing two carefully designed probing tasks: Action Antonym and Video Reversal, which targets multimodal alignment capabilities and temporal understanding skills of the model, respectively. Despite recent video-language models' (VidLM) impressive performance on various benchmark tasks, our diagnostic tasks reveal their surprising deficiency (near-random performance) in action knowledge, suggesting that current models rely on object recognition abilities as a shortcut for action understanding. To remedy this, we propose a novel framework, Paxion, along with a new Discriminative Video Dynamics Modeling (DVDM) objective. The Paxion framework utilizes a Knowledge Patcher network to encode new action knowledge and a Knowledge Fuser component to integrate the Patcher into frozen VidLMs without compromising their existing capabilities. Due to limitations of the widely-used Video-Text Contrastive (VTC) loss for learning action knowledge, we introduce the DVDM objective to train the Knowledge Patcher. DVDM forces the model to encode the correlation between the action text and the correct ordering of video frames. Our extensive analyses show that Paxion and DVDM together effectively fill the gap in action knowledge understanding (~50% to 80%), while maintaining or improving performance on a wide spectrum of both object- and action-centric downstream tasks.
Any-to-Any Generation via Composable Diffusion
May 19, 2023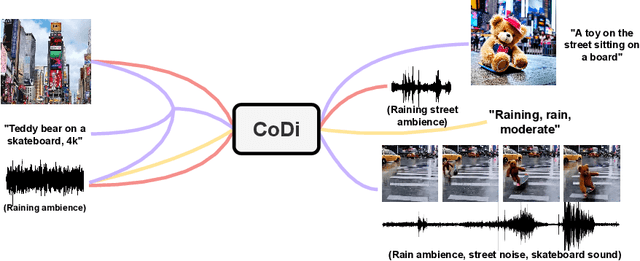

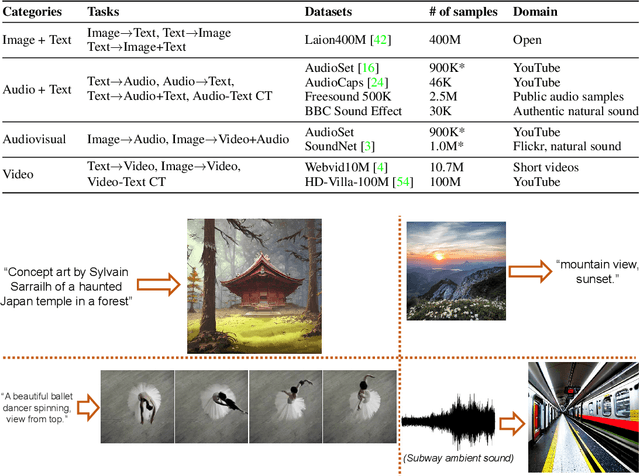

We present Composable Diffusion (CoDi), a novel generative model capable of generating any combination of output modalities, such as language, image, video, or audio, from any combination of input modalities. Unlike existing generative AI systems, CoDi can generate multiple modalities in parallel and its input is not limited to a subset of modalities like text or image. Despite the absence of training datasets for many combinations of modalities, we propose to align modalities in both the input and output space. This allows CoDi to freely condition on any input combination and generate any group of modalities, even if they are not present in the training data. CoDi employs a novel composable generation strategy which involves building a shared multimodal space by bridging alignment in the diffusion process, enabling the synchronized generation of intertwined modalities, such as temporally aligned video and audio. Highly customizable and flexible, CoDi achieves strong joint-modality generation quality, and outperforms or is on par with the unimodal state-of-the-art for single-modality synthesis. The project page with demonstrations and code is at https://codi-gen.github.io
Unifying Vision, Text, and Layout for Universal Document Processing
Dec 20, 2022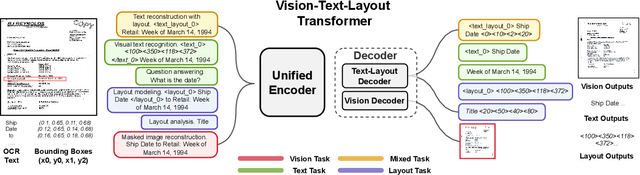

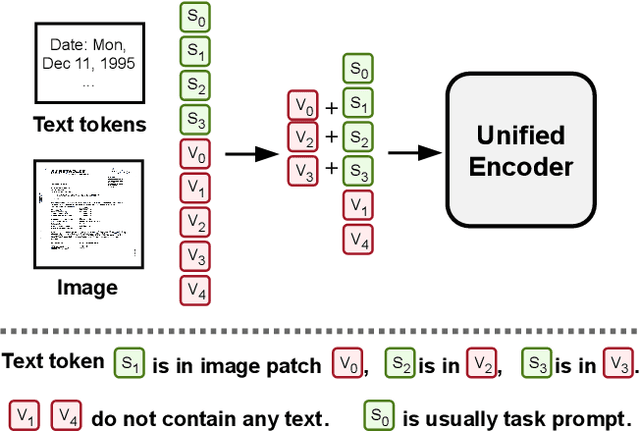
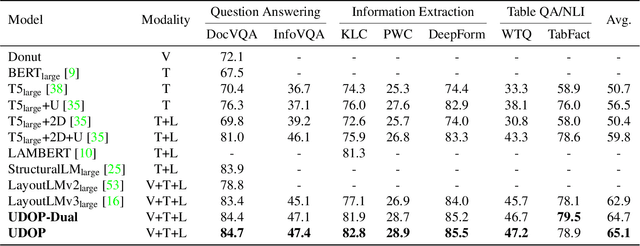
We propose Universal Document Processing (UDOP), a foundation Document AI model which unifies text, image, and layout modalities together with varied task formats, including document understanding and generation. UDOP leverages the spatial correlation between textual content and document image to model image, text, and layout modalities with one uniform representation. With a novel Vision-Text-Layout Transformer, UDOP unifies pretraining and multi-domain downstream tasks into a prompt-based sequence generation scheme. UDOP is pretrained on both large-scale unlabeled document corpora using innovative self-supervised objectives and diverse labeled data. UDOP also learns to generate document images from text and layout modalities via masked image reconstruction. To the best of our knowledge, this is the first time in the field of document AI that one model simultaneously achieves high-quality neural document editing and content customization. Our method sets the state-of-the-art on 9 Document AI tasks, e.g., document understanding and QA, across diverse data domains like finance reports, academic papers, and websites. UDOP ranks first on the leaderboard of the Document Understanding Benchmark (DUE).
Perceiver-VL: Efficient Vision-and-Language Modeling with Iterative Latent Attention
Nov 21, 2022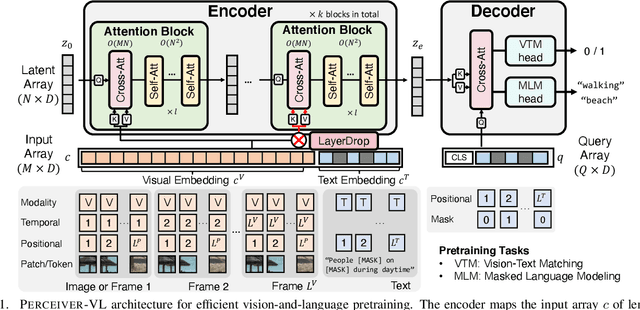
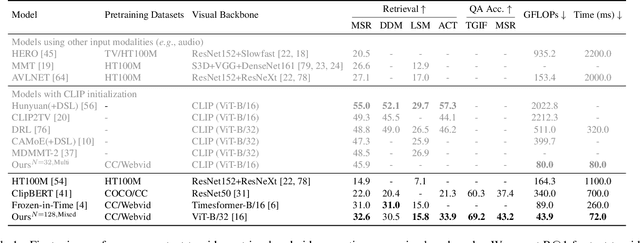

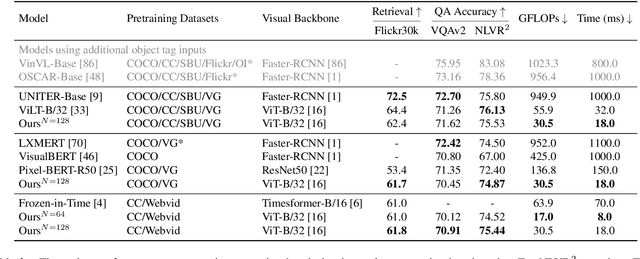
We present Perceiver-VL, a vision-and-language framework that efficiently handles high-dimensional multimodal inputs such as long videos and text. Powered by the iterative latent cross-attention of Perceiver, our framework scales with linear complexity, in contrast to the quadratic complexity of self-attention used in many state-of-the-art transformer-based models. To further improve the efficiency of our framework, we also study applying LayerDrop on cross-attention layers and introduce a mixed-stream architecture for cross-modal retrieval. We evaluate Perceiver-VL on diverse video-text and image-text benchmarks, where Perceiver-VL achieves the lowest GFLOPs and latency while maintaining competitive performance. In addition, we also provide comprehensive analyses of various aspects of our framework, including pretraining data, scalability of latent size and input size, dropping cross-attention layers at inference to reduce latency, modality aggregation strategy, positional encoding, and weight initialization strategy. Our code and checkpoints are available at: https://github.com/zinengtang/Perceiver_VL
TVLT: Textless Vision-Language Transformer
Sep 28, 2022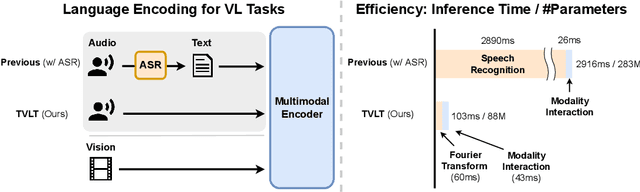
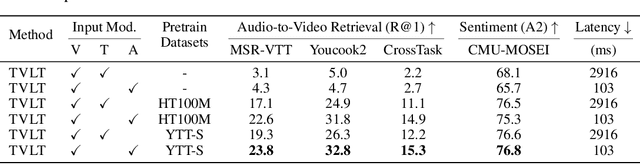

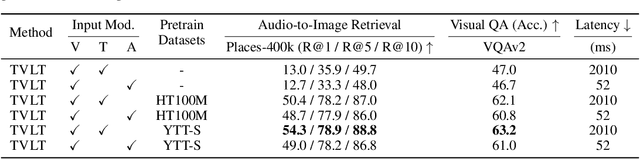
In this work, we present the Textless Vision-Language Transformer (TVLT), where homogeneous transformer blocks take raw visual and audio inputs for vision-and-language representation learning with minimal modality-specific design, and do not use text-specific modules such as tokenization or automatic speech recognition (ASR). TVLT is trained by reconstructing masked patches of continuous video frames and audio spectrograms (masked autoencoding) and contrastive modeling to align video and audio. TVLT attains performance comparable to its text-based counterpart, on various multimodal tasks, such as visual question answering, image retrieval, video retrieval, and multimodal sentiment analysis, with 28x faster inference speed and only 1/3 of the parameters. Our findings suggest the possibility of learning compact and efficient visual-linguistic representations from low-level visual and audio signals without assuming the prior existence of text. Our code and checkpoints are available at: https://github.com/zinengtang/TVLT
VidLanKD: Improving Language Understanding via Video-Distilled Knowledge Transfer
Jul 06, 2021



Since visual perception can give rich information beyond text descriptions for world understanding, there has been increasing interest in leveraging visual grounding for language learning. Recently, vokenization has attracted attention by using the predictions of a text-to-image retrieval model as labels for language model supervision. Despite its success, the method suffers from approximation error of using finite image labels and the lack of vocabulary diversity of a small image-text dataset. To overcome these limitations, we present VidLanKD, a video-language knowledge distillation method for improving language understanding. We train a multi-modal teacher model on a video-text dataset, and then transfer its knowledge to a student language model with a text dataset. To avoid approximation error, we propose to use different knowledge distillation objectives. In addition, the use of a large-scale video-text dataset helps learn diverse and richer vocabularies. In our experiments, VidLanKD achieves consistent improvements over text-only language models and vokenization models, on several downstream language understanding tasks including GLUE, SQuAD, and SWAG. We also demonstrate the improved world knowledge, physical reasoning, and temporal reasoning capabilities of our model by evaluating on the GLUE-diagnostics, PIQA, and TRACIE datasets. Lastly, we present comprehensive ablation studies as well as visualizations of the learned text-to-video grounding results of our teacher and student language models. Our code and models are available at: https://github.com/zinengtang/VidLanKD
Dense-Caption Matching and Frame-Selection Gating for Temporal Localization in VideoQA
May 13, 2020
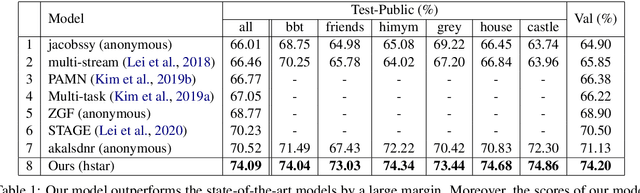

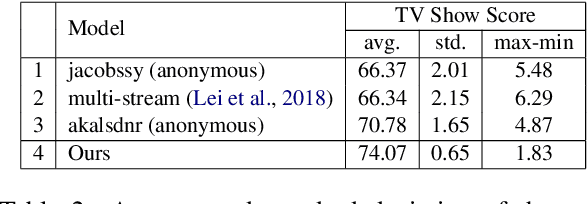
Videos convey rich information. Dynamic spatio-temporal relationships between people/objects, and diverse multimodal events are present in a video clip. Hence, it is important to develop automated models that can accurately extract such information from videos. Answering questions on videos is one of the tasks which can evaluate such AI abilities. In this paper, we propose a video question answering model which effectively integrates multi-modal input sources and finds the temporally relevant information to answer questions. Specifically, we first employ dense image captions to help identify objects and their detailed salient regions and actions, and hence give the model useful extra information (in explicit textual format to allow easier matching) for answering questions. Moreover, our model is also comprised of dual-level attention (word/object and frame level), multi-head self/cross-integration for different sources (video and dense captions), and gates which pass more relevant information to the classifier. Finally, we also cast the frame selection problem as a multi-label classification task and introduce two loss functions, In-andOut Frame Score Margin (IOFSM) and Balanced Binary Cross-Entropy (BBCE), to better supervise the model with human importance annotations. We evaluate our model on the challenging TVQA dataset, where each of our model components provides significant gains, and our overall model outperforms the state-of-the-art by a large margin (74.09% versus 70.52%). We also present several word, object, and frame level visualization studies. Our code is publicly available at: https://github.com/hyounghk/VideoQADenseCapFrameGate-ACL2020