 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZiyi Yang
3DGSR: Implicit Surface Reconstruction with 3D Gaussian Splatting
Mar 30, 2024
In this paper, we present an implicit surface reconstruction method with 3D Gaussian Splatting (3DGS), namely 3DGSR, that allows for accurate 3D reconstruction with intricate details while inheriting the high efficiency and rendering quality of 3DGS. The key insight is incorporating an implicit signed distance field (SDF) within 3D Gaussians to enable them to be aligned and jointly optimized. First, we introduce a differentiable SDF-to-opacity transformation function that converts SDF values into corresponding Gaussians' opacities. This function connects the SDF and 3D Gaussians, allowing for unified optimization and enforcing surface constraints on the 3D Gaussians. During learning, optimizing the 3D Gaussians provides supervisory signals for SDF learning, enabling the reconstruction of intricate details. However, this only provides sparse supervisory signals to the SDF at locations occupied by Gaussians, which is insufficient for learning a continuous SDF. Then, to address this limitation, we incorporate volumetric rendering and align the rendered geometric attributes (depth, normal) with those derived from 3D Gaussians. This consistency regularization introduces supervisory signals to locations not covered by discrete 3D Gaussians, effectively eliminating redundant surfaces outside the Gaussian sampling range. Our extensive experimental results demonstrate that our 3DGSR method enables high-quality 3D surface reconstruction while preserving the efficiency and rendering quality of 3DGS. Besides, our method competes favorably with leading surface reconstruction techniques while offering a more efficient learning process and much better rendering qualities. The code will be available at https://github.com/CVMI-Lab/3DGSR.
Training Small Multimodal Models to Bridge Biomedical Competency Gap: A Case Study in Radiology Imaging
Mar 20, 2024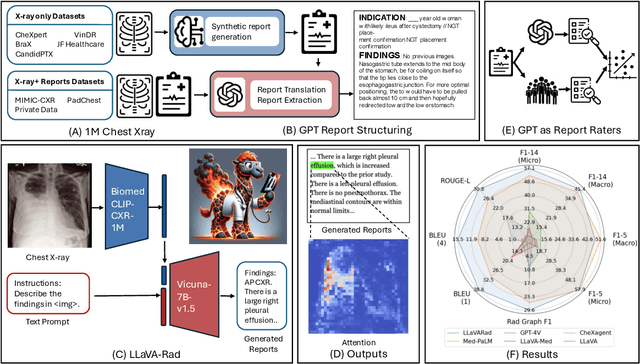
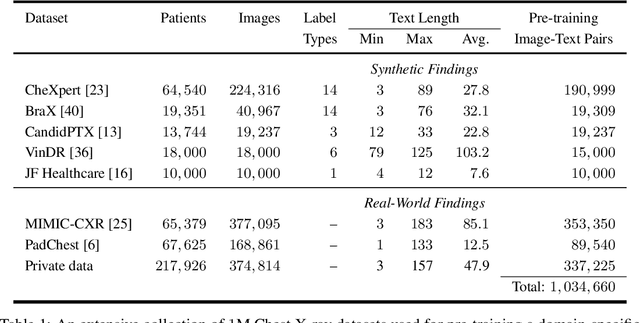
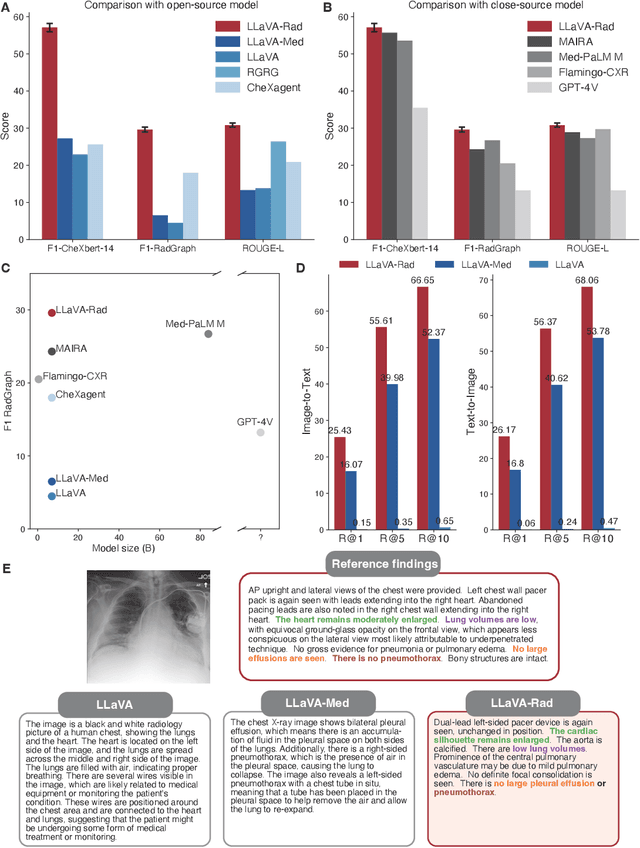
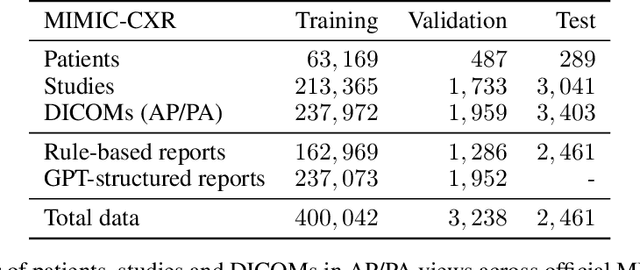
The scaling laws and extraordinary performance of large foundation models motivate the development and utilization of such large models in biomedicine. However, despite early promising results on some biomedical benchmarks, there are still major challenges that need to be addressed before these models can be used in real-world applications. Frontier models such as GPT-4V still have major competency gaps in multimodal capabilities for biomedical applications. Moreover, pragmatic issues such as access, cost, latency, and compliance make it hard for clinicians to use privately-hosted state-of-the-art large models directly on private patient data. In this paper, we explore training open-source small multimodal models (SMMs) to bridge biomedical competency gaps for unmet clinical needs. To maximize data efficiency, we adopt a modular approach by incorporating state-of-the-art pre-trained models for image and text modalities, and focusing on training a lightweight adapter to ground each modality to the text embedding space. We conduct a comprehensive study of this approach on radiology imaging. For training, we assemble a large dataset with over 1 million image-text pairs. For evaluation, we propose a clinically driven novel approach using GPT-4 and demonstrate its parity with expert evaluation. We also study grounding qualitatively using attention. For best practice, we conduct a systematic ablation study on various choices in data engineering and multimodal training. The resulting LLaVA-Rad (7B) model attains state-of-the-art results on radiology tasks such as report generation and cross-modal retrieval, even outperforming much larger models such as GPT-4V and Med-PaLM M (84B). LLaVA-Rad is fast and can be run on a single V100 GPU in private settings, offering a promising state-of-the-art tool for real-world clinical applications.
FuseChat: Knowledge Fusion of Chat Models
Mar 03, 2024While training large language models (LLMs) from scratch can indeed lead to models with distinct capabilities and strengths, this approach incurs substantial costs and may lead to potential redundancy in competencies. An alternative strategy is to combine existing LLMs into a more robust LLM, thereby diminishing the necessity for expensive pre-training. However, due to the diverse architectures of LLMs, direct parameter blending proves to be unfeasible. Recently, \textsc{FuseLLM} introduced the concept of knowledge fusion to transfer the collective knowledge of multiple structurally varied LLMs into a target LLM through lightweight continual training. In this report, we extend the scalability and flexibility of the \textsc{FuseLLM} framework to realize the fusion of chat LLMs, resulting in \textsc{FuseChat}. \textsc{FuseChat} comprises two main stages. Firstly, we undertake knowledge fusion for structurally and scale-varied source LLMs to derive multiple target LLMs of identical structure and size via lightweight fine-tuning. Then, these target LLMs are merged within the parameter space, wherein we propose a novel method for determining the merging weights based on the variation ratio of parameter matrices before and after fine-tuning. We validate our approach using three prominent chat LLMs with diverse architectures and scales, namely \texttt{NH2-Mixtral-8x7B}, \texttt{NH2-Solar-10.7B}, and \texttt{OpenChat-3.5-7B}. Experimental results spanning various chat domains demonstrate the superiority of \texttt{\textsc{FuseChat}-7B} across a broad spectrum of chat LLMs at 7B and 34B scales, even surpassing \texttt{GPT-3.5 (March)} and approaching \texttt{Mixtral-8x7B-Instruct}. Our code, model weights, and data are openly accessible at \url{https://github.com/fanqiwan/FuseLLM}.
Spec-Gaussian: Anisotropic View-Dependent Appearance for 3D Gaussian Splatting
Feb 24, 2024The recent advancements in 3D Gaussian splatting (3D-GS) have not only facilitated real-time rendering through modern GPU rasterization pipelines but have also attained state-of-the-art rendering quality. Nevertheless, despite its exceptional rendering quality and performance on standard datasets, 3D-GS frequently encounters difficulties in accurately modeling specular and anisotropic components. This issue stems from the limited ability of spherical harmonics (SH) to represent high-frequency information. To overcome this challenge, we introduce Spec-Gaussian, an approach that utilizes an anisotropic spherical Gaussian (ASG) appearance field instead of SH for modeling the view-dependent appearance of each 3D Gaussian. Additionally, we have developed a coarse-to-fine training strategy to improve learning efficiency and eliminate floaters caused by overfitting in real-world scenes. Our experimental results demonstrate that our method surpasses existing approaches in terms of rendering quality. Thanks to ASG, we have significantly improved the ability of 3D-GS to model scenes with specular and anisotropic components without increasing the number of 3D Gaussians. This improvement extends the applicability of 3D GS to handle intricate scenarios with specular and anisotropic surfaces.
CoDi-2: In-Context, Interleaved, and Interactive Any-to-Any Generation
Nov 30, 2023We present CoDi-2, a versatile and interactive Multimodal Large Language Model (MLLM) that can follow complex multimodal interleaved instructions, conduct in-context learning (ICL), reason, chat, edit, etc., in an any-to-any input-output modality paradigm. By aligning modalities with language for both encoding and generation, CoDi-2 empowers Large Language Models (LLMs) to not only understand complex modality-interleaved instructions and in-context examples, but also autoregressively generate grounded and coherent multimodal outputs in the continuous feature space. To train CoDi-2, we build a large-scale generation dataset encompassing in-context multimodal instructions across text, vision, and audio. CoDi-2 demonstrates a wide range of zero-shot capabilities for multimodal generation, such as in-context learning, reasoning, and compositionality of any-to-any modality generation through multi-round interactive conversation. CoDi-2 surpasses previous domain-specific models on tasks such as subject-driven image generation, vision transformation, and audio editing. CoDi-2 signifies a substantial breakthrough in developing a comprehensive multimodal foundation model adept at interpreting in-context language-vision-audio interleaved instructions and producing multimodal outputs.
SIRe-IR: Inverse Rendering for BRDF Reconstruction with Shadow and Illumination Removal in High-Illuminance Scenes
Oct 19, 2023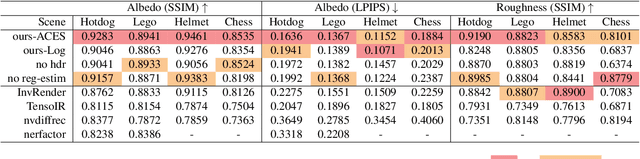
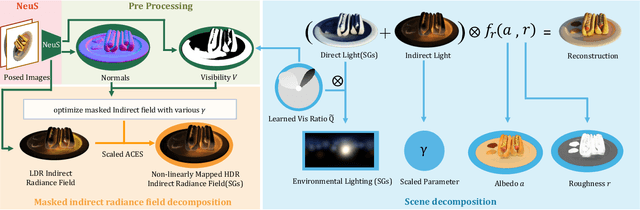


Implicit neural representation has opened up new possibilities for inverse rendering. However, existing implicit neural inverse rendering methods struggle to handle strongly illuminated scenes with significant shadows and indirect illumination. The existence of shadows and reflections can lead to an inaccurate understanding of scene geometry, making precise factorization difficult. To this end, we present SIRe-IR, an implicit neural inverse rendering approach that uses non-linear mapping and regularized visibility estimation to decompose the scene into environment map, albedo, and roughness. By accurately modeling the indirect radiance field, normal, visibility, and direct light simultaneously, we are able to remove both shadows and indirect illumination in materials without imposing strict constraints on the scene. Even in the presence of intense illumination, our method recovers high-quality albedo and roughness with no shadow interference. SIRe-IR outperforms existing methods in both quantitative and qualitative evaluations.
Soft Convex Quantization: Revisiting Vector Quantization with Convex Optimization
Oct 04, 2023
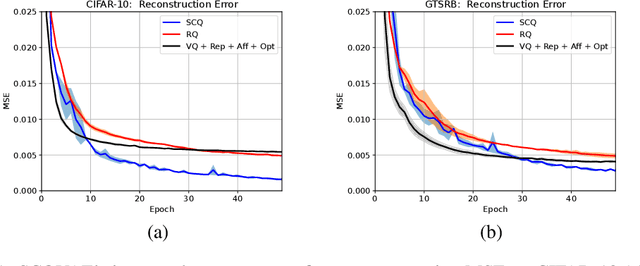

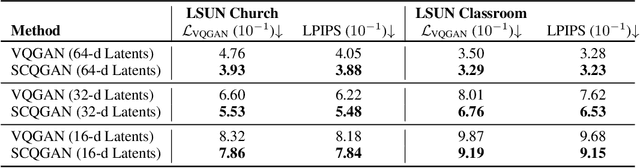
Vector Quantization (VQ) is a well-known technique in deep learning for extracting informative discrete latent representations. VQ-embedded models have shown impressive results in a range of applications including image and speech generation. VQ operates as a parametric K-means algorithm that quantizes inputs using a single codebook vector in the forward pass. While powerful, this technique faces practical challenges including codebook collapse, non-differentiability and lossy compression. To mitigate the aforementioned issues, we propose Soft Convex Quantization (SCQ) as a direct substitute for VQ. SCQ works like a differentiable convex optimization (DCO) layer: in the forward pass, we solve for the optimal convex combination of codebook vectors that quantize the inputs. In the backward pass, we leverage differentiability through the optimality conditions of the forward solution. We then introduce a scalable relaxation of the SCQ optimization and demonstrate its efficacy on the CIFAR-10, GTSRB and LSUN datasets. We train powerful SCQ autoencoder models that significantly outperform matched VQ-based architectures, observing an order of magnitude better image reconstruction and codebook usage with comparable quantization runtime.
Deformable 3D Gaussians for High-Fidelity Monocular Dynamic Scene Reconstruction
Sep 22, 2023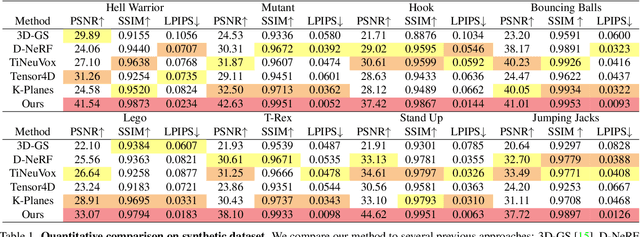
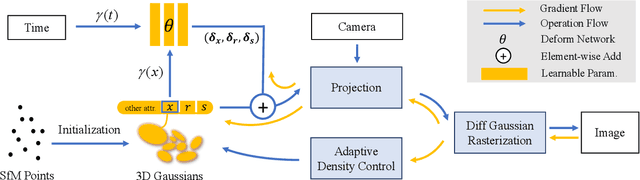
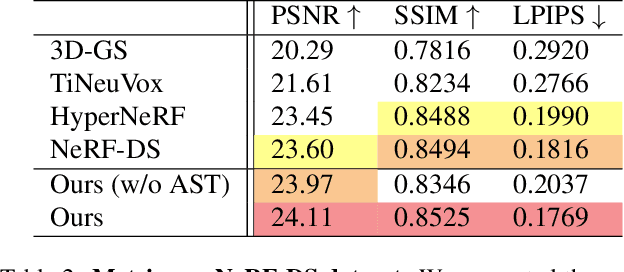

Implicit neural representation has opened up new avenues for dynamic scene reconstruction and rendering. Nonetheless, state-of-the-art methods of dynamic neural rendering rely heavily on these implicit representations, which frequently struggle with accurately capturing the intricate details of objects in the scene. Furthermore, implicit methods struggle to achieve real-time rendering in general dynamic scenes, limiting their use in a wide range of tasks. To address the issues, we propose a deformable 3D Gaussians Splatting method that reconstructs scenes using explicit 3D Gaussians and learns Gaussians in canonical space with a deformation field to model monocular dynamic scenes. We also introduced a smoothing training mechanism with no extra overhead to mitigate the impact of inaccurate poses in real datasets on the smoothness of time interpolation tasks. Through differential gaussian rasterization, the deformable 3D Gaussians not only achieve higher rendering quality but also real-time rendering speed. Experiments show that our method outperforms existing methods significantly in terms of both rendering quality and speed, making it well-suited for tasks such as novel-view synthesis, time synthesis, and real-time rendering.
Plug in the Safety Chip: Enforcing Constraints for LLM-driven Robot Agents
Sep 18, 2023
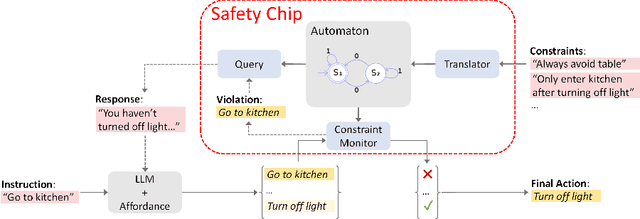
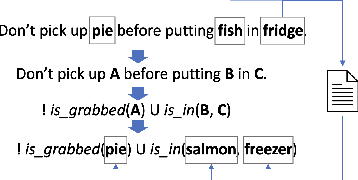
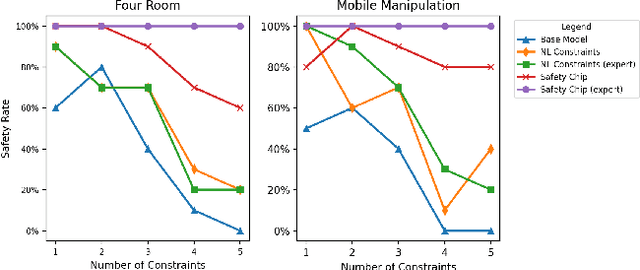
Recent advancements in large language models (LLMs) have enabled a new research domain, LLM agents, for solving robotics and planning tasks by leveraging the world knowledge and general reasoning abilities of LLMs obtained during pretraining. However, while considerable effort has been made to teach the robot the "dos," the "don'ts" received relatively less attention. We argue that, for any practical usage, it is as crucial to teach the robot the "don'ts": conveying explicit instructions about prohibited actions, assessing the robot's comprehension of these restrictions, and, most importantly, ensuring compliance. Moreover, verifiable safe operation is essential for deployments that satisfy worldwide standards such as ISO 61508, which defines standards for safely deploying robots in industrial factory environments worldwide. Aiming at deploying the LLM agents in a collaborative environment, we propose a queryable safety constraint module based on linear temporal logic (LTL) that simultaneously enables natural language (NL) to temporal constraints encoding, safety violation reasoning and explaining, and unsafe action pruning. To demonstrate the effectiveness of our system, we conducted experiments in VirtualHome environment and on a real robot. The experimental results show that our system strictly adheres to the safety constraints and scales well with complex safety constraints, highlighting its potential for practical utility.
A General Implicit Framework for Fast NeRF Composition and Rendering
Aug 14, 2023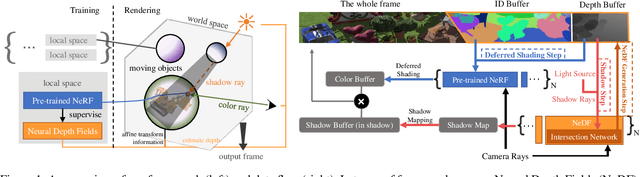

A variety of Neural Radiance Fields (NeRF) methods have recently achieved remarkable success in high render speed. However, current accelerating methods are specialized and incompatible with various implicit methods, preventing real-time composition over various types of NeRF works. Because NeRF relies on sampling along rays, it is possible to provide general guidance for acceleration. To that end, we propose a general implicit pipeline for composing NeRF objects quickly. Our method enables the casting of dynamic shadows within or between objects using analytical light sources while allowing multiple NeRF objects to be seamlessly placed and rendered together with any arbitrary rigid transformations. Mainly, our work introduces a new surface representation known as Neural Depth Fields (NeDF) that quickly determines the spatial relationship between objects by allowing direct intersection computation between rays and implicit surfaces. It leverages an intersection neural network to query NeRF for acceleration instead of depending on an explicit spatial structure.Our proposed method is the first to enable both the progressive and interactive composition of NeRF objects. Additionally, it also serves as a previewing plugin for a range of existing NeRF works.