 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaojun Quan
RoleInteract: Evaluating the Social Interaction of Role-Playing Agents
Mar 22, 2024
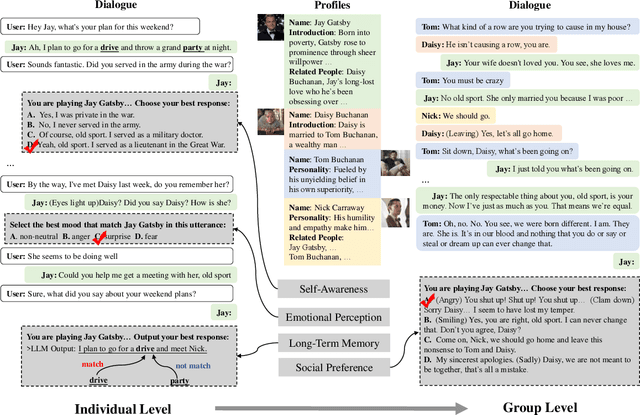
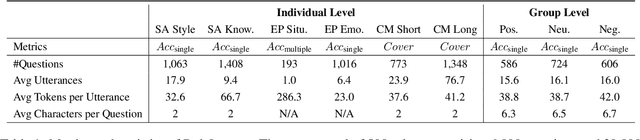
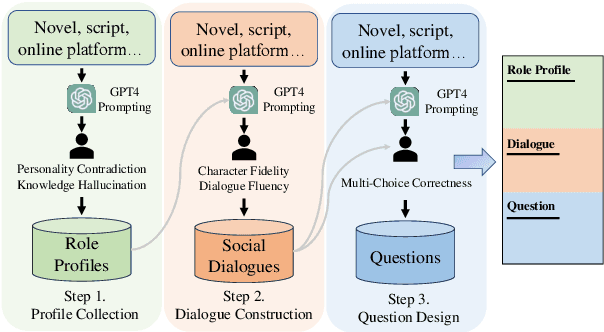
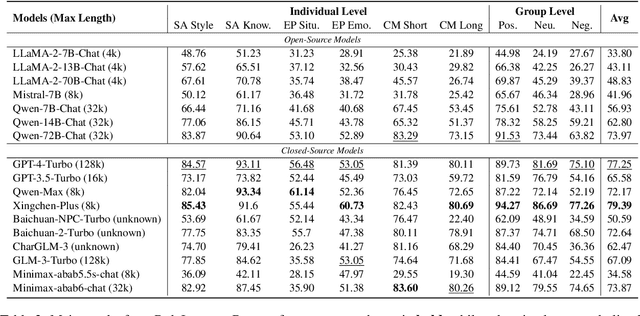
Large language models (LLMs) have advanced the development of various AI conversational agents, including role-playing conversational agents that mimic diverse characters and human behaviors. While prior research has predominantly focused on enhancing the conversational capability, role-specific knowledge, and stylistic attributes of these agents, there has been a noticeable gap in assessing their social intelligence. In this paper, we introduce RoleInteract, the first benchmark designed to systematically evaluate the sociality of role-playing conversational agents at both individual and group levels of social interactions. The benchmark is constructed from a variety of sources and covers a wide range of 500 characters and over 6,000 question prompts and 30,800 multi-turn role-playing utterances. We conduct comprehensive evaluations on this benchmark using mainstream open-source and closed-source LLMs. We find that agents excelling in individual level does not imply their proficiency in group level. Moreover, the behavior of individuals may drift as a result of the influence exerted by other agents within the group. Experimental results on RoleInteract confirm its significance as a testbed for assessing the social interaction of role-playing conversational agents. The benchmark is publicly accessible at https://github.com/X-PLUG/RoleInteract.
FuseChat: Knowledge Fusion of Chat Models
Mar 03, 2024While training large language models (LLMs) from scratch can indeed lead to models with distinct capabilities and strengths, this approach incurs substantial costs and may lead to potential redundancy in competencies. An alternative strategy is to combine existing LLMs into a more robust LLM, thereby diminishing the necessity for expensive pre-training. However, due to the diverse architectures of LLMs, direct parameter blending proves to be unfeasible. Recently, \textsc{FuseLLM} introduced the concept of knowledge fusion to transfer the collective knowledge of multiple structurally varied LLMs into a target LLM through lightweight continual training. In this report, we extend the scalability and flexibility of the \textsc{FuseLLM} framework to realize the fusion of chat LLMs, resulting in \textsc{FuseChat}. \textsc{FuseChat} comprises two main stages. Firstly, we undertake knowledge fusion for structurally and scale-varied source LLMs to derive multiple target LLMs of identical structure and size via lightweight fine-tuning. Then, these target LLMs are merged within the parameter space, wherein we propose a novel method for determining the merging weights based on the variation ratio of parameter matrices before and after fine-tuning. We validate our approach using three prominent chat LLMs with diverse architectures and scales, namely \texttt{NH2-Mixtral-8x7B}, \texttt{NH2-Solar-10.7B}, and \texttt{OpenChat-3.5-7B}. Experimental results spanning various chat domains demonstrate the superiority of \texttt{\textsc{FuseChat}-7B} across a broad spectrum of chat LLMs at 7B and 34B scales, even surpassing \texttt{GPT-3.5 (March)} and approaching \texttt{Mixtral-8x7B-Instruct}. Our code, model weights, and data are openly accessible at \url{https://github.com/fanqiwan/FuseLLM}.
Alirector: Alignment-Enhanced Chinese Grammatical Error Corrector
Feb 07, 2024Chinese grammatical error correction (CGEC) faces serious overcorrection challenges when employing autoregressive generative models such as sequence-to-sequence (Seq2Seq) models and decoder-only large language models (LLMs). While previous methods aim to address overcorrection in Seq2Seq models, they are difficult to adapt to decoder-only LLMs. In this paper, we propose an alignment-enhanced corrector for the overcorrection problem that applies to both Seq2Seq models and decoder-only LLMs. Our method first trains a correction model to generate an initial correction of the source sentence. Then, we combine the source sentence with the initial correction and feed it through an alignment model for another round of correction, aiming to enforce the alignment model to focus on potential overcorrection. Moreover, to enhance the model's ability to identify nuances, we further explore the reverse alignment of the source sentence and the initial correction. Finally, we transfer the alignment knowledge from two alignment models to the correction model, instructing it on how to avoid overcorrection. Experimental results on three CGEC datasets demonstrate the effectiveness of our approach in alleviating overcorrection and improving overall performance.
Small LLMs Are Weak Tool Learners: A Multi-LLM Agent
Feb 01, 2024Large Language Model (LLM) agents significantly extend the capabilities of standalone LLMs, empowering them to interact with external tools (e.g., APIs, functions) and complete complex tasks in a self-directed fashion. The challenge of tool use demands that LLMs not only understand user queries and generate answers but also excel in task planning, memory management, tool invocation, and result summarization. While traditional approaches focus on training a single LLM with all these capabilities, performance limitations become apparent, particularly with smaller models. Moreover, the entire LLM may require retraining when tools are updated. To overcome these challenges, we propose a novel strategy that decomposes the aforementioned capabilities into a planner, caller, and summarizer. Each component is implemented by a single LLM that focuses on a specific capability and collaborates with other components to accomplish the task. This modular framework facilitates individual updates and the potential use of smaller LLMs for building each capability. To effectively train this framework, we introduce a two-stage training paradigm. First, we fine-tune a backbone LLM on the entire dataset without discriminating sub-tasks, providing the model with a comprehensive understanding of the task. Second, the fine-tuned LLM is used to instantiate the planner, caller, and summarizer respectively, which are continually fine-tuned on respective sub-tasks. Evaluation across various tool-use benchmarks illustrates that our proposed multi-LLM framework surpasses the traditional single-LLM approach, highlighting its efficacy and advantages in tool learning.
Mitigating Hallucinations of Large Language Models via Knowledge Consistent Alignment
Jan 28, 2024While Large Language Models (LLMs) have proven to be exceptional on a variety of tasks after alignment, they may still produce responses that contradict the context or world knowledge confidently, a phenomenon known as ``hallucination''. In this paper, we demonstrate that reducing the inconsistency between the external knowledge encapsulated in the training data and the intrinsic knowledge inherited in the pretraining corpus could mitigate hallucination in alignment. Specifically, we introduce a novel knowledge consistent alignment (KCA) approach, which involves automatically formulating examinations based on external knowledge for accessing the comprehension of LLMs. For data encompassing knowledge inconsistency, KCA implements several simple yet efficient strategies for processing. We illustrate the superior performance of the proposed KCA approach in mitigating hallucinations across six benchmarks using LLMs of different backbones and scales. Furthermore, we confirm the correlation between knowledge inconsistency and hallucination, signifying the effectiveness of reducing knowledge inconsistency in alleviating hallucinations. Our code, model weights, and data are public at \url{https://github.com/fanqiwan/KCA}.
Knowledge Fusion of Large Language Models
Jan 22, 2024While training large language models (LLMs) from scratch can generate models with distinct functionalities and strengths, it comes at significant costs and may result in redundant capabilities. Alternatively, a cost-effective and compelling approach is to merge existing pre-trained LLMs into a more potent model. However, due to the varying architectures of these LLMs, directly blending their weights is impractical. In this paper, we introduce the notion of knowledge fusion for LLMs, aimed at combining the capabilities of existing LLMs and transferring them into a single LLM. By leveraging the generative distributions of source LLMs, we externalize their collective knowledge and unique strengths, thereby potentially elevating the capabilities of the target model beyond those of any individual source LLM. We validate our approach using three popular LLMs with different architectures--Llama-2, MPT, and OpenLLaMA--across various benchmarks and tasks. Our findings confirm that the fusion of LLMs can improve the performance of the target model across a range of capabilities such as reasoning, commonsense, and code generation. Our code, model weights, and data are public at \url{https://github.com/fanqiwan/FuseLLM}.
Knowledge Distillation for Closed-Source Language Models
Jan 13, 2024Closed-source language models such as GPT-4 have achieved remarkable performance. Many recent studies focus on enhancing the capabilities of smaller models through knowledge distillation from closed-source language models. However, due to the incapability to directly access the weights, hidden states, and output distributions of these closed-source models, the distillation can only be performed by fine-tuning smaller models with data samples generated by closed-source language models, which constrains the effectiveness of knowledge distillation. In this paper, we propose to estimate the output distributions of closed-source language models within a Bayesian estimation framework, involving both prior and posterior estimation. The prior estimation aims to derive a prior distribution by utilizing the corpus generated by closed-source language models, while the posterior estimation employs a proxy model to update the prior distribution and derive a posterior distribution. By leveraging the estimated output distribution of closed-source language models, traditional knowledge distillation can be executed. Experimental results demonstrate that our method surpasses the performance of current models directly fine-tuned on data generated by closed-source language models.
PsyCoT: Psychological Questionnaire as Powerful Chain-of-Thought for Personality Detection
Nov 05, 2023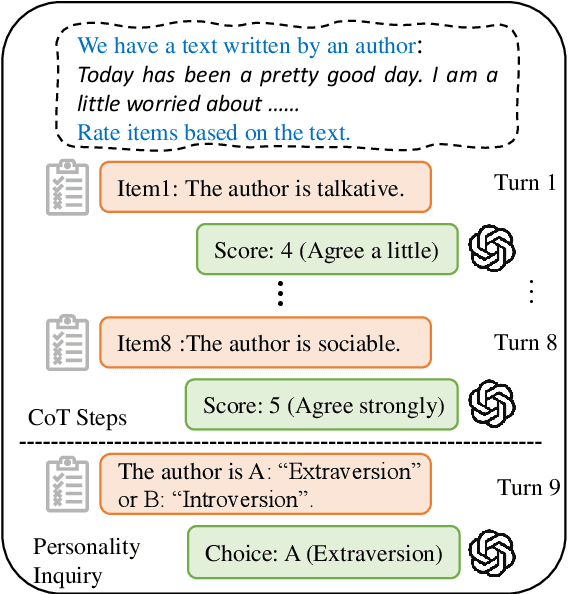
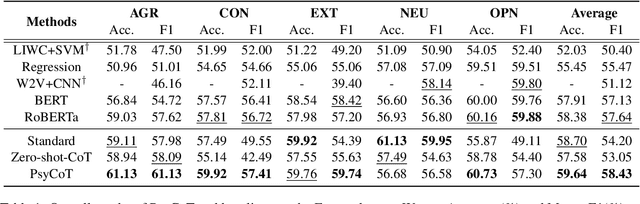

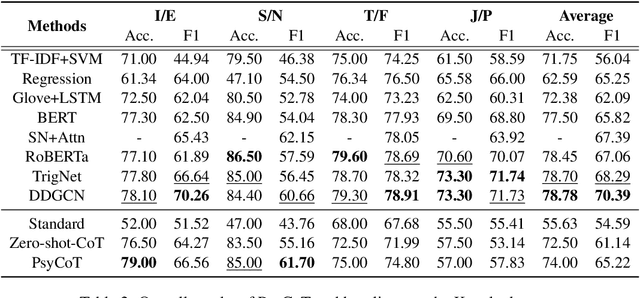
Recent advances in large language models (LLMs), such as ChatGPT, have showcased remarkable zero-shot performance across various NLP tasks. However, the potential of LLMs in personality detection, which involves identifying an individual's personality from their written texts, remains largely unexplored. Drawing inspiration from Psychological Questionnaires, which are carefully designed by psychologists to evaluate individual personality traits through a series of targeted items, we argue that these items can be regarded as a collection of well-structured chain-of-thought (CoT) processes. By incorporating these processes, LLMs can enhance their capabilities to make more reasonable inferences on personality from textual input. In light of this, we propose a novel personality detection method, called PsyCoT, which mimics the way individuals complete psychological questionnaires in a multi-turn dialogue manner. In particular, we employ a LLM as an AI assistant with a specialization in text analysis. We prompt the assistant to rate individual items at each turn and leverage the historical rating results to derive a conclusive personality preference. Our experiments demonstrate that PsyCoT significantly improves the performance and robustness of GPT-3.5 in personality detection, achieving an average F1 score improvement of 4.23/10.63 points on two benchmark datasets compared to the standard prompting method. Our code is available at https://github.com/TaoYang225/PsyCoT.
MCC-KD: Multi-CoT Consistent Knowledge Distillation
Oct 24, 2023
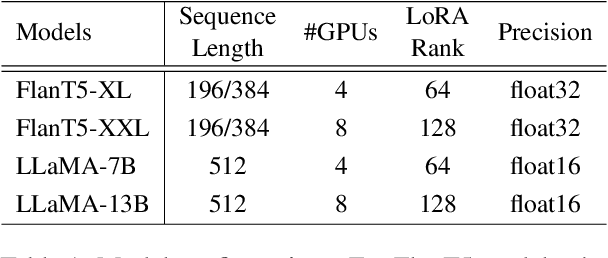
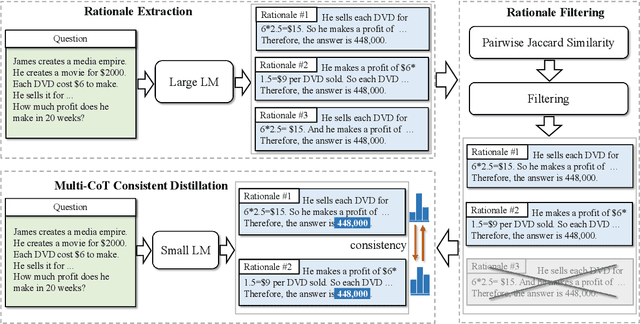
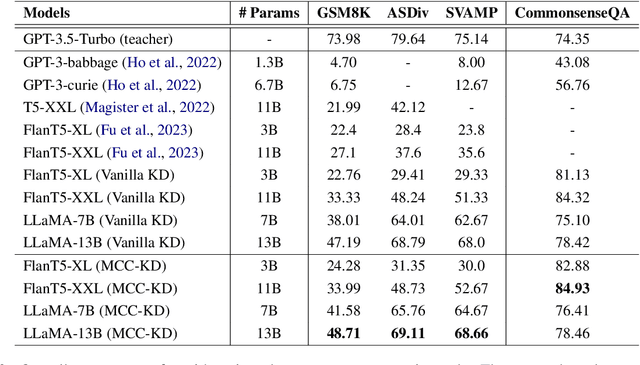
Large language models (LLMs) have showcased remarkable capabilities in complex reasoning through chain of thought (CoT) prompting. Recently, there has been a growing interest in transferring these reasoning abilities from LLMs to smaller models. However, achieving both the diversity and consistency in rationales presents a challenge. In this paper, we focus on enhancing these two aspects and propose Multi-CoT Consistent Knowledge Distillation (MCC-KD) to efficiently distill the reasoning capabilities. In MCC-KD, we generate multiple rationales for each question and enforce consistency among the corresponding predictions by minimizing the bidirectional KL-divergence between the answer distributions. We investigate the effectiveness of MCC-KD with different model architectures (LLaMA/FlanT5) and various model scales (3B/7B/11B/13B) on both mathematical reasoning and commonsense reasoning benchmarks. The empirical results not only confirm MCC-KD's superior performance on in-distribution datasets but also highlight its robust generalization ability on out-of-distribution datasets.
Explore-Instruct: Enhancing Domain-Specific Instruction Coverage through Active Exploration
Oct 24, 2023
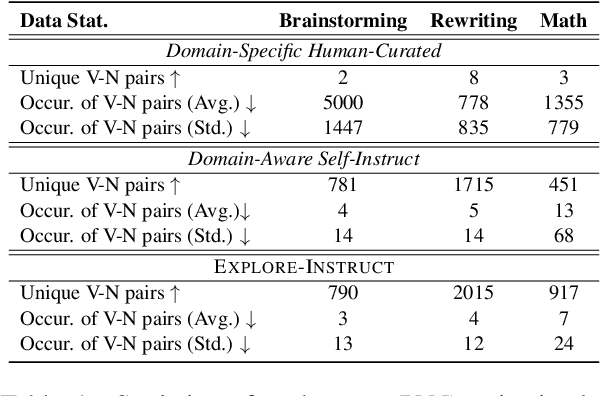

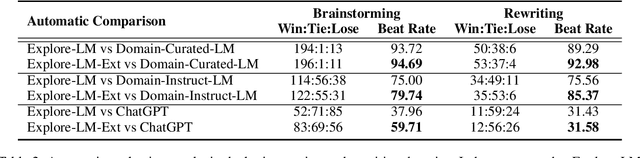
Instruction-tuning can be substantially optimized through enhanced diversity, resulting in models capable of handling a broader spectrum of tasks. However, existing data employed for such tuning often exhibit an inadequate coverage of individual domains, limiting the scope for nuanced comprehension and interactions within these areas. To address this deficiency, we propose Explore-Instruct, a novel approach to enhance the data coverage to be used in domain-specific instruction-tuning through active exploration via Large Language Models (LLMs). Built upon representative domain use cases, Explore-Instruct explores a multitude of variations or possibilities by implementing a search algorithm to obtain diversified and domain-focused instruction-tuning data. Our data-centric analysis validates the effectiveness of this proposed approach in improving domain-specific instruction coverage. Moreover, our model's performance demonstrates considerable advancements over multiple baselines, including those utilizing domain-specific data enhancement. Our findings offer a promising opportunity to improve instruction coverage, especially in domain-specific contexts, thereby advancing the development of adaptable language models. Our code, model weights, and data are public at \url{https://github.com/fanqiwan/Explore-Instruct}.