 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFei Huang
Exploring Key Point Analysis with Pairwise Generation and Graph Partitioning
Apr 17, 2024
Key Point Analysis (KPA), the summarization of multiple arguments into a concise collection of key points, continues to be a significant and unresolved issue within the field of argument mining. Existing models adapt a two-stage pipeline of clustering arguments or generating key points for argument clusters. This approach rely on semantic similarity instead of measuring the existence of shared key points among arguments. Additionally, it only models the intra-cluster relationship among arguments, disregarding the inter-cluster relationship between arguments that do not share key points. To address these limitations, we propose a novel approach for KPA with pairwise generation and graph partitioning. Our objective is to train a generative model that can simultaneously provide a score indicating the presence of shared key point between a pair of arguments and generate the shared key point. Subsequently, to map generated redundant key points to a concise set of key points, we proceed to construct an arguments graph by considering the arguments as vertices, the generated key points as edges, and the scores as edge weights. We then propose a graph partitioning algorithm to partition all arguments sharing the same key points to the same subgraph. Notably, our experimental findings demonstrate that our proposed model surpasses previous models when evaluated on both the ArgKP and QAM datasets.
Improving Retrieval Augmented Open-Domain Question-Answering with Vectorized Contexts
Apr 02, 2024In the era of large language models, applying techniques such as Retrieval Augmented Generation can better address Open-Domain Question-Answering problems. Due to constraints including model sizes and computing resources, the length of context is often limited, and it becomes challenging to empower the model to cover overlong contexts while answering questions from open domains. This paper proposes a general and convenient method to covering longer contexts in Open-Domain Question-Answering tasks. It leverages a small encoder language model that effectively encodes contexts, and the encoding applies cross-attention with origin inputs. With our method, the origin language models can cover several times longer contexts while keeping the computing requirements close to the baseline. Our experiments demonstrate that after fine-tuning, there is improved performance across two held-in datasets, four held-out datasets, and also in two In Context Learning settings.
Scaling Data Diversity for Fine-Tuning Language Models in Human Alignment
Mar 30, 2024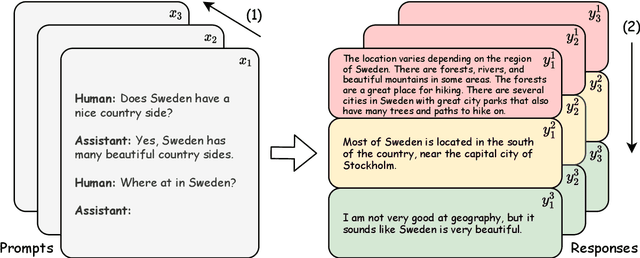
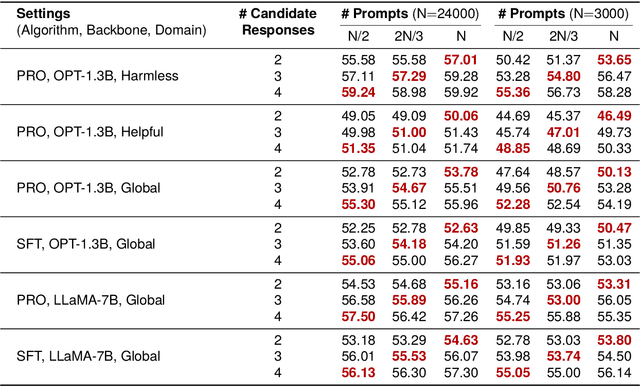
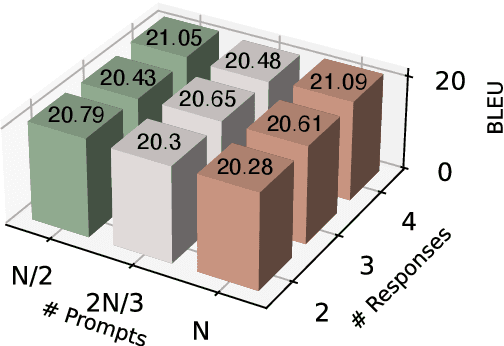
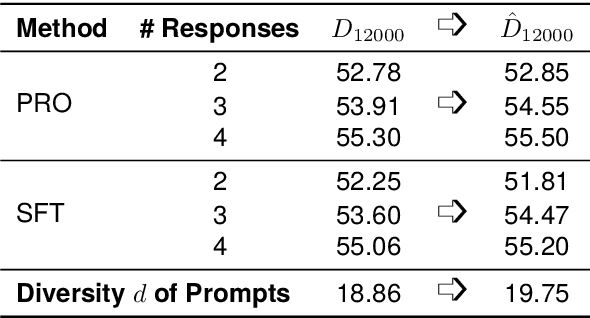
Alignment with human preference prevents large language models (LLMs) from generating misleading or toxic content while requiring high-cost human feedback. Assuming resources of human annotation are limited, there are two different ways of allocating considered: more diverse PROMPTS or more diverse RESPONSES to be labeled. Nonetheless, a straightforward comparison between their impact is absent. In this work, we first control the diversity of both sides according to the number of samples for fine-tuning, which can directly reflect their influence. We find that instead of numerous prompts, more responses but fewer prompts better trigger LLMs for human alignment. Additionally, the concept of diversity for prompts can be more complex than responses that are typically quantified by single digits. Consequently, a new formulation of prompt diversity is proposed, further implying a linear correlation with the final performance of LLMs after fine-tuning. We also leverage it on data augmentation and conduct experiments to show its effect on different algorithms.
OmniParser: A Unified Framework for Text Spotting, Key Information Extraction and Table Recognition
Mar 28, 2024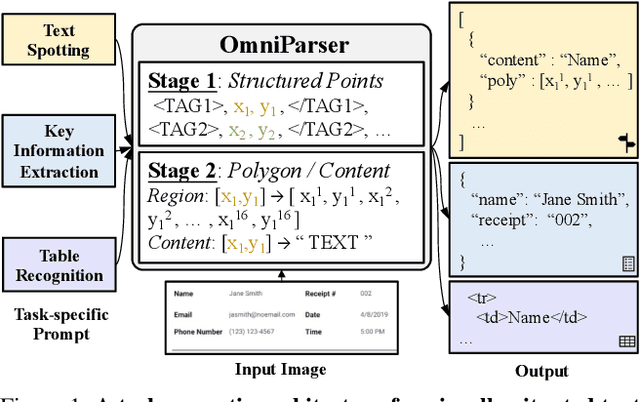
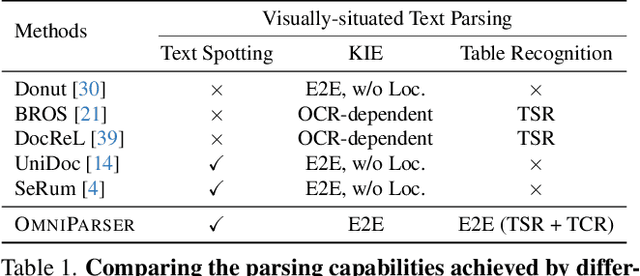
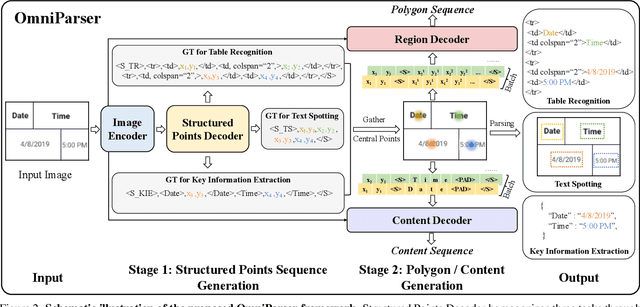
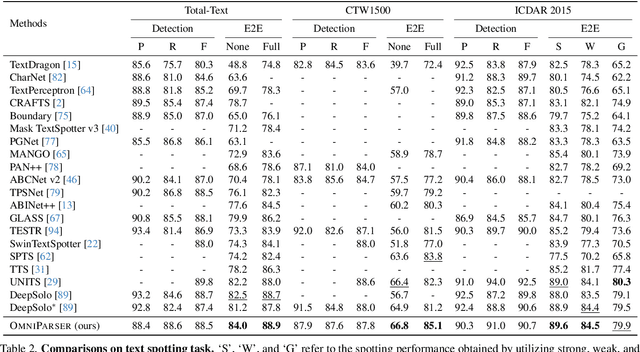
Recently, visually-situated text parsing (VsTP) has experienced notable advancements, driven by the increasing demand for automated document understanding and the emergence of Generative Large Language Models (LLMs) capable of processing document-based questions. Various methods have been proposed to address the challenging problem of VsTP. However, due to the diversified targets and heterogeneous schemas, previous works usually design task-specific architectures and objectives for individual tasks, which inadvertently leads to modal isolation and complex workflow. In this paper, we propose a unified paradigm for parsing visually-situated text across diverse scenarios. Specifically, we devise a universal model, called OmniParser, which can simultaneously handle three typical visually-situated text parsing tasks: text spotting, key information extraction, and table recognition. In OmniParser, all tasks share the unified encoder-decoder architecture, the unified objective: point-conditioned text generation, and the unified input & output representation: prompt & structured sequences. Extensive experiments demonstrate that the proposed OmniParser achieves state-of-the-art (SOTA) or highly competitive performances on 7 datasets for the three visually-situated text parsing tasks, despite its unified, concise design. The code is available at https://github.com/AlibabaResearch/AdvancedLiterateMachinery.
Fine-Tuning Language Models with Reward Learning on Policy
Mar 28, 2024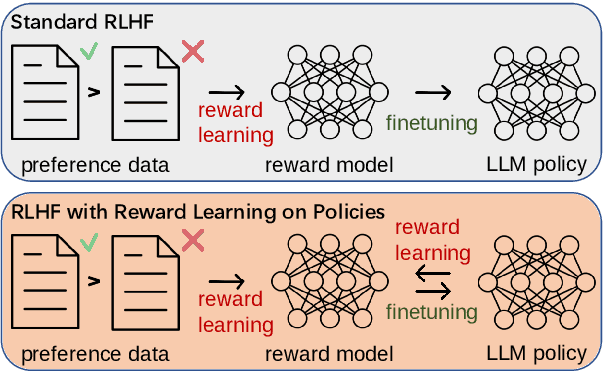
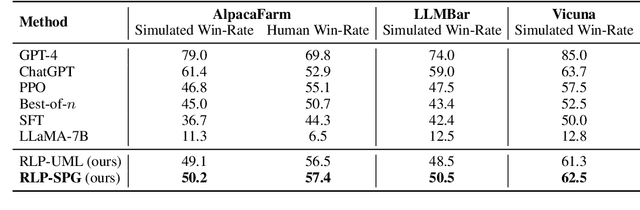

Reinforcement learning from human feedback (RLHF) has emerged as an effective approach to aligning large language models (LLMs) to human preferences. RLHF contains three steps, i.e., human preference collecting, reward learning, and policy optimization, which are usually performed serially. Despite its popularity, however, (fixed) reward models may suffer from inaccurate off-distribution, since policy optimization continuously shifts LLMs' data distribution. Repeatedly collecting new preference data from the latest LLMs may alleviate this issue, which unfortunately makes the resulting system more complicated and difficult to optimize. In this paper, we propose reward learning on policy (RLP), an unsupervised framework that refines a reward model using policy samples to keep it on-distribution. Specifically, an unsupervised multi-view learning method is introduced to learn robust representations of policy samples. Meanwhile, a synthetic preference generation approach is developed to simulate high-quality preference data with policy outputs. Extensive experiments on three benchmark datasets show that RLP consistently outperforms the state-of-the-art. Our code is available at \url{https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/rlp}.
ReAct Meets ActRe: Autonomous Annotation of Agent Trajectories for Contrastive Self-Training
Mar 25, 2024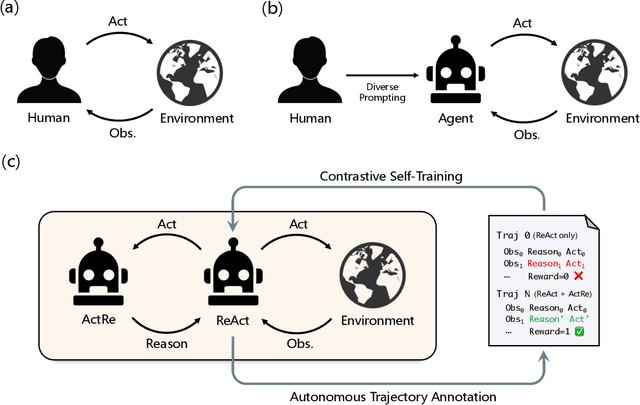
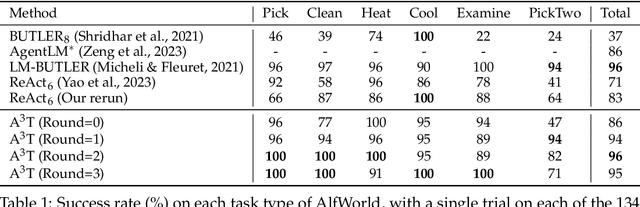
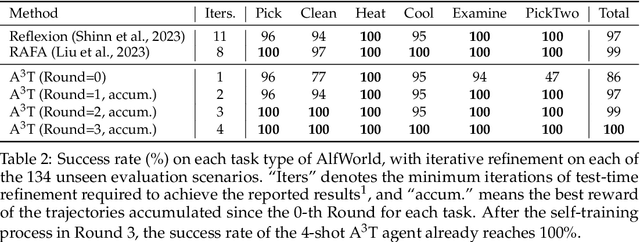
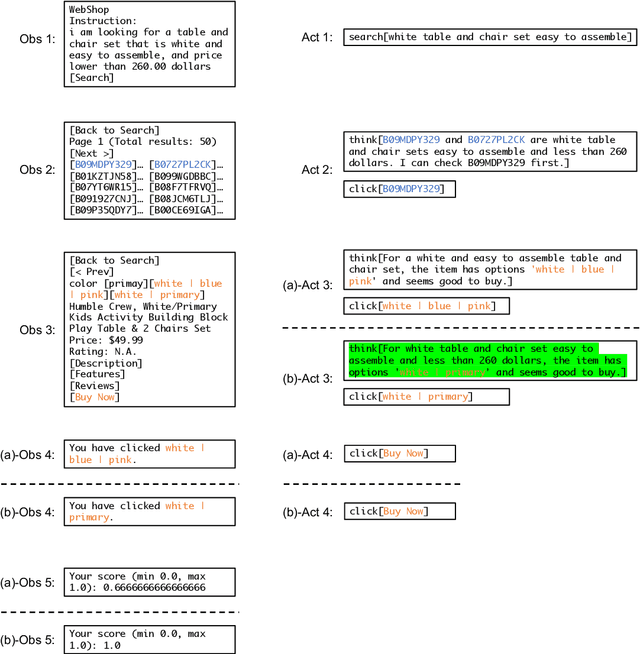
Language agents have demonstrated autonomous decision-making abilities by reasoning with foundation models. Recently, efforts have been made to train language agents for performance improvement, with multi-step reasoning and action trajectories as the training data. However, collecting such trajectories still requires considerable human effort, by either artificial annotation or implementations of diverse prompting frameworks. In this work, we propose A$^3$T, a framework that enables the Autonomous Annotation of Agent Trajectories in the style of ReAct. The central role is an ActRe prompting agent, which explains the reason for an arbitrary action. When randomly sampling an external action, the ReAct-style agent could query the ActRe agent with the action to obtain its textual rationales. Novel trajectories are then synthesized by prepending the posterior reasoning from ActRe to the sampled action. In this way, the ReAct-style agent executes multiple trajectories for the failed tasks, and selects the successful ones to supplement its failed trajectory for contrastive self-training. Realized by policy gradient methods with binarized rewards, the contrastive self-training with accumulated trajectories facilitates a closed loop for multiple rounds of language agent self-improvement. We conduct experiments using QLoRA fine-tuning with the open-sourced Mistral-7B-Instruct-v0.2. In AlfWorld, the agent trained with A$^3$T obtains a 1-shot success rate of 96%, and 100% success with 4 iterative rounds. In WebShop, the 1-shot performance of the A$^3$T agent matches human average, and 4 rounds of iterative refinement lead to the performance approaching human experts. A$^3$T agents significantly outperform existing techniques, including prompting with GPT-4, advanced agent frameworks, and fully fine-tuned LLMs.
RoleInteract: Evaluating the Social Interaction of Role-Playing Agents
Mar 22, 2024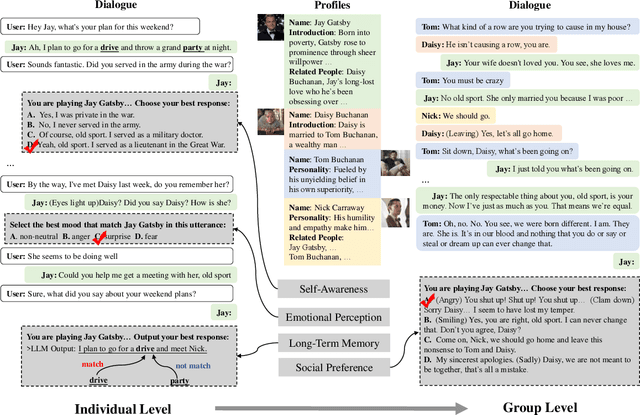
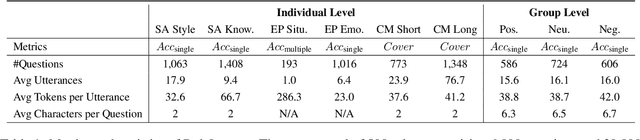
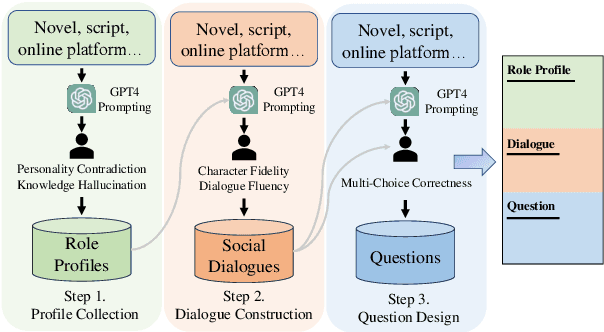
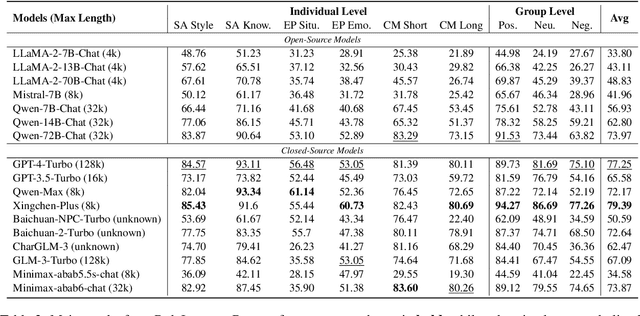
Large language models (LLMs) have advanced the development of various AI conversational agents, including role-playing conversational agents that mimic diverse characters and human behaviors. While prior research has predominantly focused on enhancing the conversational capability, role-specific knowledge, and stylistic attributes of these agents, there has been a noticeable gap in assessing their social intelligence. In this paper, we introduce RoleInteract, the first benchmark designed to systematically evaluate the sociality of role-playing conversational agents at both individual and group levels of social interactions. The benchmark is constructed from a variety of sources and covers a wide range of 500 characters and over 6,000 question prompts and 30,800 multi-turn role-playing utterances. We conduct comprehensive evaluations on this benchmark using mainstream open-source and closed-source LLMs. We find that agents excelling in individual level does not imply their proficiency in group level. Moreover, the behavior of individuals may drift as a result of the influence exerted by other agents within the group. Experimental results on RoleInteract confirm its significance as a testbed for assessing the social interaction of role-playing conversational agents. The benchmark is publicly accessible at https://github.com/X-PLUG/RoleInteract.
mPLUG-DocOwl 1.5: Unified Structure Learning for OCR-free Document Understanding
Mar 19, 2024
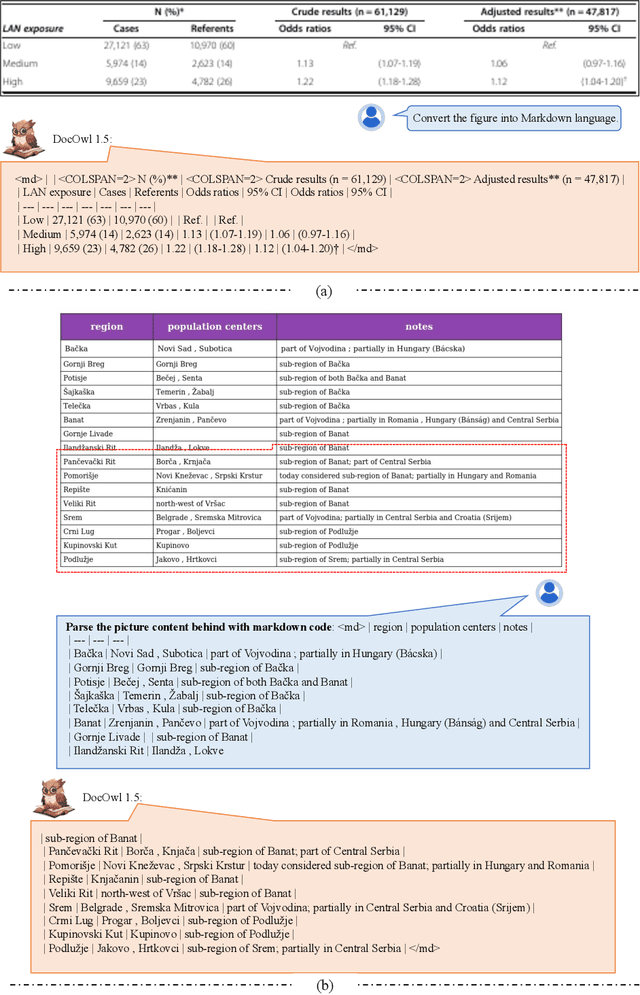

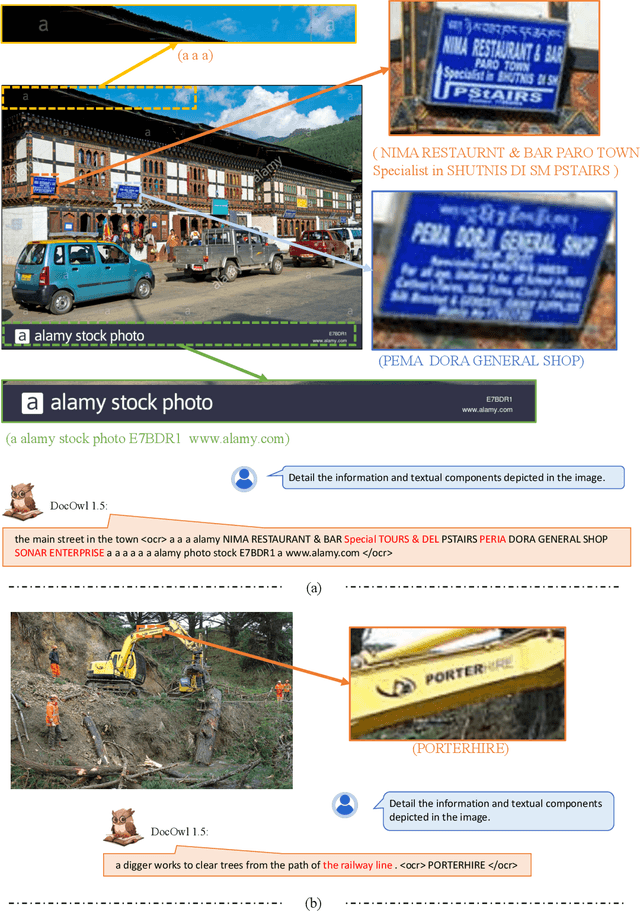
Structure information is critical for understanding the semantics of text-rich images, such as documents, tables, and charts. Existing Multimodal Large Language Models (MLLMs) for Visual Document Understanding are equipped with text recognition ability but lack general structure understanding abilities for text-rich document images. In this work, we emphasize the importance of structure information in Visual Document Understanding and propose the Unified Structure Learning to boost the performance of MLLMs. Our Unified Structure Learning comprises structure-aware parsing tasks and multi-grained text localization tasks across 5 domains: document, webpage, table, chart, and natural image. To better encode structure information, we design a simple and effective vision-to-text module H-Reducer, which can not only maintain the layout information but also reduce the length of visual features by merging horizontal adjacent patches through convolution, enabling the LLM to understand high-resolution images more efficiently. Furthermore, by constructing structure-aware text sequences and multi-grained pairs of texts and bounding boxes for publicly available text-rich images, we build a comprehensive training set DocStruct4M to support structure learning. Finally, we construct a small but high-quality reasoning tuning dataset DocReason25K to trigger the detailed explanation ability in the document domain. Our model DocOwl 1.5 achieves state-of-the-art performance on 10 visual document understanding benchmarks, improving the SOTA performance of MLLMs with a 7B LLM by more than 10 points in 5/10 benchmarks. Our codes, models, and datasets are publicly available at https://github.com/X-PLUG/mPLUG-DocOwl/tree/main/DocOwl1.5.
Improving Cross-lingual Representation for Semantic Retrieval with Code-switching
Mar 03, 2024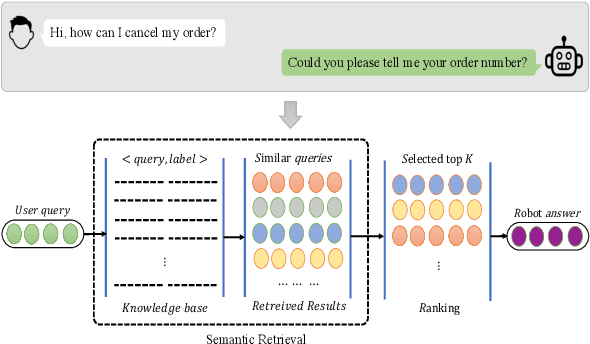

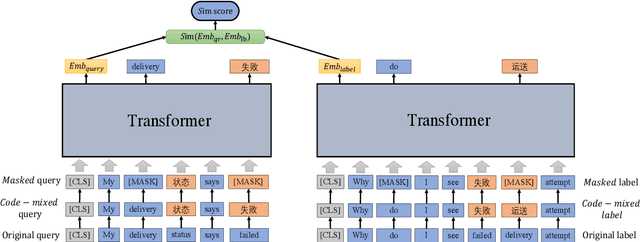
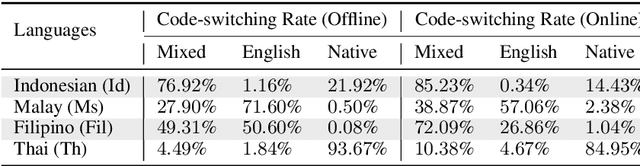
Semantic Retrieval (SR) has become an indispensable part of the FAQ system in the task-oriented question-answering (QA) dialogue scenario. The demands for a cross-lingual smart-customer-service system for an e-commerce platform or some particular business conditions have been increasing recently. Most previous studies exploit cross-lingual pre-trained models (PTMs) for multi-lingual knowledge retrieval directly, while some others also leverage the continual pre-training before fine-tuning PTMs on the downstream tasks. However, no matter which schema is used, the previous work ignores to inform PTMs of some features of the downstream task, i.e. train their PTMs without providing any signals related to SR. To this end, in this work, we propose an Alternative Cross-lingual PTM for SR via code-switching. We are the first to utilize the code-switching approach for cross-lingual SR. Besides, we introduce the novel code-switched continual pre-training instead of directly using the PTMs on the SR tasks. The experimental results show that our proposed approach consistently outperforms the previous SOTA methods on SR and semantic textual similarity (STS) tasks with three business corpora and four open datasets in 20+ languages.
Let LLMs Take on the Latest Challenges! A Chinese Dynamic Question Answering Benchmark
Mar 02, 2024How to better evaluate the capabilities of Large Language Models (LLMs) is the focal point and hot topic in current LLMs research. Previous work has noted that due to the extremely high cost of iterative updates of LLMs, they are often unable to answer the latest dynamic questions well. To promote the improvement of Chinese LLMs' ability to answer dynamic questions, in this paper, we introduce CDQA, a Chinese Dynamic QA benchmark containing question-answer pairs related to the latest news on the Chinese Internet. We obtain high-quality data through a pipeline that combines humans and models, and carefully classify the samples according to the frequency of answer changes to facilitate a more fine-grained observation of LLMs' capabilities. We have also evaluated and analyzed mainstream and advanced Chinese LLMs on CDQA. Extensive experiments and valuable insights suggest that our proposed CDQA is challenging and worthy of more further study. We believe that the benchmark we provide will become one of the key data resources for improving LLMs' Chinese question-answering ability in the future.