 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaiyang Yu
Scaling Data Diversity for Fine-Tuning Language Models in Human Alignment
Mar 30, 2024
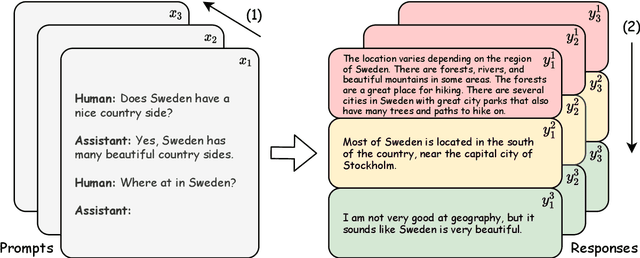
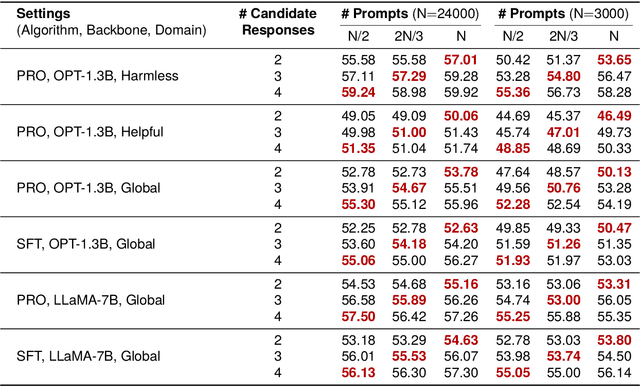
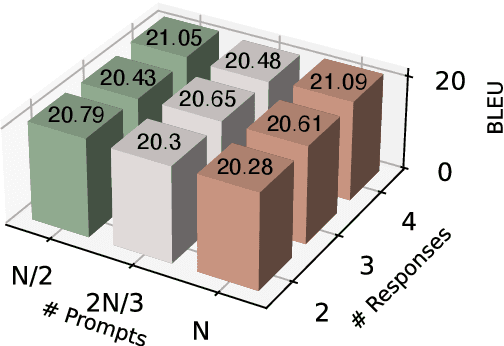
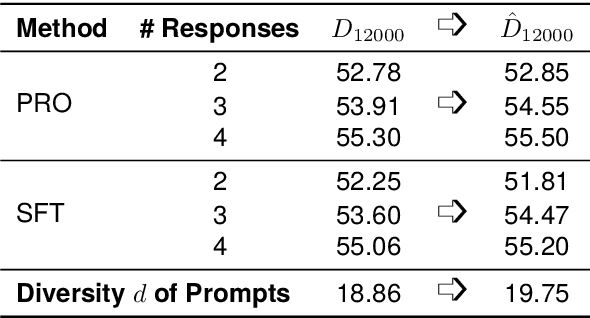
Alignment with human preference prevents large language models (LLMs) from generating misleading or toxic content while requiring high-cost human feedback. Assuming resources of human annotation are limited, there are two different ways of allocating considered: more diverse PROMPTS or more diverse RESPONSES to be labeled. Nonetheless, a straightforward comparison between their impact is absent. In this work, we first control the diversity of both sides according to the number of samples for fine-tuning, which can directly reflect their influence. We find that instead of numerous prompts, more responses but fewer prompts better trigger LLMs for human alignment. Additionally, the concept of diversity for prompts can be more complex than responses that are typically quantified by single digits. Consequently, a new formulation of prompt diversity is proposed, further implying a linear correlation with the final performance of LLMs after fine-tuning. We also leverage it on data augmentation and conduct experiments to show its effect on different algorithms.
TPLLM: A Traffic Prediction Framework Based on Pretrained Large Language Models
Mar 04, 2024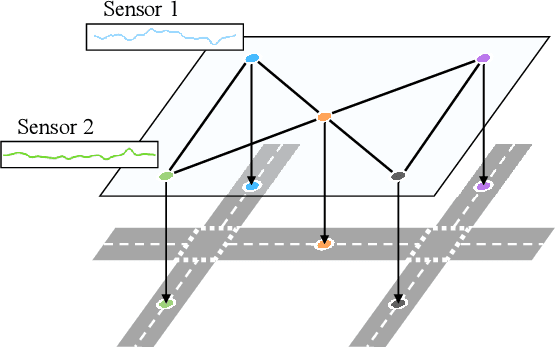
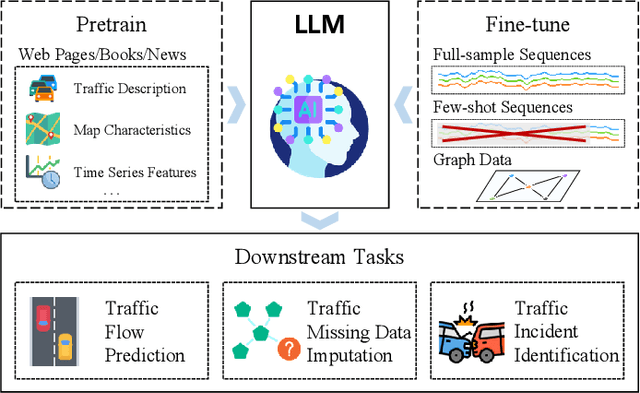

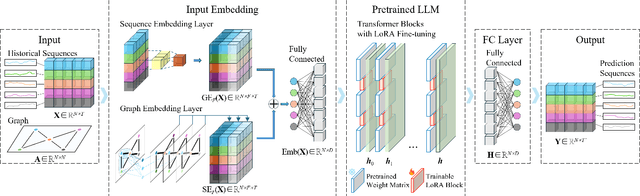
Traffic prediction constitutes a pivotal facet within the purview of Intelligent Transportation Systems (ITS), and the attainment of highly precise predictions holds profound significance for efficacious traffic management. The precision of prevailing deep learning-driven traffic prediction models typically sees an upward trend with a rise in the volume of training data. However, the procurement of comprehensive spatiotemporal datasets for traffic is often fraught with challenges, primarily stemming from the substantial costs associated with data collection and retention. Consequently, developing a model that can achieve accurate predictions and good generalization ability in areas with limited historical traffic data is a challenging problem. It is noteworthy that the rapidly advancing pretrained Large Language Models (LLMs) of recent years have demonstrated exceptional proficiency in cross-modality knowledge transfer and few-shot learning. Recognizing the sequential nature of traffic data, similar to language, we introduce TPLLM, a novel traffic prediction framework leveraging LLMs. In this framework, we construct a sequence embedding layer based on Convolutional Neural Networks (CNNs) and a graph embedding layer based on Graph Convolutional Networks (GCNs) to extract sequence features and spatial features, respectively. These are subsequently integrated to form inputs that are suitable for LLMs. A Low-Rank Adaptation (LoRA) fine-tuning approach is applied to TPLLM, thereby facilitating efficient learning and minimizing computational demands. Experiments on two real-world datasets demonstrate that TPLLM exhibits commendable performance in both full-sample and few-shot prediction scenarios, effectively supporting the development of ITS in regions with scarce historical traffic data.
SoFA: Shielded On-the-fly Alignment via Priority Rule Following
Feb 27, 2024The alignment problem in Large Language Models (LLMs) involves adapting them to the broad spectrum of human values. This requirement challenges existing alignment methods due to diversity of preferences and regulatory standards. This paper introduces a novel alignment paradigm, priority rule following, which defines rules as the primary control mechanism in each dialog, prioritizing them over user instructions. Our preliminary analysis reveals that even the advanced LLMs, such as GPT-4, exhibit shortcomings in understanding and prioritizing the rules. Therefore, we present PriorityDistill, a semi-automated approach for distilling priority following signals from LLM simulations to ensure robust rule integration and adherence. Our experiments show that this method not only effectively minimizes misalignments utilizing only one general rule but also adapts smoothly to various unseen rules, ensuring they are shielded from hijacking and that the model responds appropriately.
Self-Retrieval: Building an Information Retrieval System with One Large Language Model
Feb 23, 2024
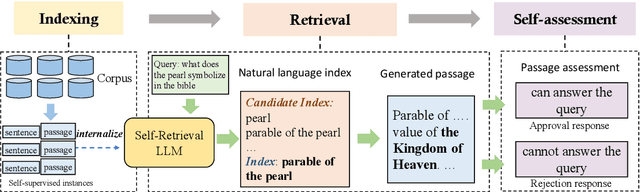
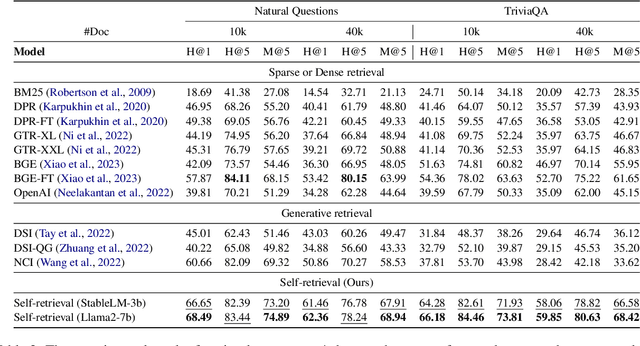
The rise of large language models (LLMs) has transformed the role of information retrieval (IR) systems in the way to humans accessing information. Due to the isolated architecture and the limited interaction, existing IR systems are unable to fully accommodate the shift from directly providing information to humans to indirectly serving large language models. In this paper, we propose Self-Retrieval, an end-to-end, LLM-driven information retrieval architecture that can fully internalize the required abilities of IR systems into a single LLM and deeply leverage the capabilities of LLMs during IR process. Specifically, Self-retrieval internalizes the corpus to retrieve into a LLM via a natural language indexing architecture. Then the entire retrieval process is redefined as a procedure of document generation and self-assessment, which can be end-to-end executed using a single large language model. Experimental results demonstrate that Self-Retrieval not only significantly outperforms previous retrieval approaches by a large margin, but also can significantly boost the performance of LLM-driven downstream applications like retrieval augumented generation.
NetInfoF Framework: Measuring and Exploiting Network Usable Information
Feb 12, 2024Given a node-attributed graph, and a graph task (link prediction or node classification), can we tell if a graph neural network (GNN) will perform well? More specifically, do the graph structure and the node features carry enough usable information for the task? Our goals are (1) to develop a fast tool to measure how much information is in the graph structure and in the node features, and (2) to exploit the information to solve the task, if there is enough. We propose NetInfoF, a framework including NetInfoF_Probe and NetInfoF_Act, for the measurement and the exploitation of network usable information (NUI), respectively. Given a graph data, NetInfoF_Probe measures NUI without any model training, and NetInfoF_Act solves link prediction and node classification, while two modules share the same backbone. In summary, NetInfoF has following notable advantages: (a) General, handling both link prediction and node classification; (b) Principled, with theoretical guarantee and closed-form solution; (c) Effective, thanks to the proposed adjustment to node similarity; (d) Scalable, scaling linearly with the input size. In our carefully designed synthetic datasets, NetInfoF correctly identifies the ground truth of NUI and is the only method being robust to all graph scenarios. Applied on real-world datasets, NetInfoF wins in 11 out of 12 times on link prediction compared to general GNN baselines.
DeCoF: Generated Video Detection via Frame Consistency
Feb 06, 2024The escalating quality of video generated by advanced video generation methods leads to new security challenges in society, which makes generated video detection an urgent research priority. To foster collaborative research in this area, we construct the first open-source dataset explicitly for generated video detection, providing a valuable resource for the community to benchmark and improve detection methodologies. Through a series of carefully designed probe experiments, our study explores the significance of temporal and spatial artifacts in developing general and robust detectors for generated video. Based on the principle of video frame consistency, we introduce a simple yet effective detection model (DeCoF) that eliminates the impact of spatial artifacts during generalizing feature learning. Our extensive experiments demonstrate the efficacy of DeCoF in detecting videos produced by unseen video generation models and confirm its powerful generalization capabilities across several commercial proprietary models.
AccidentGPT: Accident Analysis and Prevention from V2X Environmental Perception with Multi-modal Large Model
Dec 29, 2023Traffic accidents, being a significant contributor to both human casualties and property damage, have long been a focal point of research for many scholars in the field of traffic safety. However, previous studies, whether focusing on static environmental assessments or dynamic driving analyses, as well as pre-accident predictions or post-accident rule analyses, have typically been conducted in isolation. There has been a lack of an effective framework for developing a comprehensive understanding and application of traffic safety. To address this gap, this paper introduces AccidentGPT, a comprehensive accident analysis and prevention multi-modal large model. AccidentGPT establishes a multi-modal information interaction framework grounded in multi-sensor perception, thereby enabling a holistic approach to accident analysis and prevention in the field of traffic safety. Specifically, our capabilities can be categorized as follows: for autonomous driving vehicles, we provide comprehensive environmental perception and understanding to control the vehicle and avoid collisions. For human-driven vehicles, we offer proactive long-range safety warnings and blind-spot alerts while also providing safety driving recommendations and behavioral norms through human-machine dialogue and interaction. Additionally, for traffic police and management agencies, our framework supports intelligent and real-time analysis of traffic safety, encompassing pedestrian, vehicles, roads, and the environment through collaborative perception from multiple vehicles and road testing devices. The system is also capable of providing a thorough analysis of accident causes and liability after vehicle collisions. Our framework stands as the first large model to integrate comprehensive scene understanding into traffic safety studies. Project page: https://accidentgpt.github.io
OCGEC: One-class Graph Embedding Classification for DNN Backdoor Detection
Dec 04, 2023Deep neural networks (DNNs) have been found vulnerable to backdoor attacks, raising security concerns about their deployment in mission-critical applications. There are various approaches to detect backdoor attacks, however they all make certain assumptions about the target attack to be detected and require equal and huge numbers of clean and backdoor samples for training, which renders these detection methods quite limiting in real-world circumstances. This study proposes a novel one-class classification framework called One-class Graph Embedding Classification (OCGEC) that uses GNNs for model-level backdoor detection with only a little amount of clean data. First, we train thousands of tiny models as raw datasets from a small number of clean datasets. Following that, we design a ingenious model-to-graph method for converting the model's structural details and weight features into graph data. We then pre-train a generative self-supervised graph autoencoder (GAE) to better learn the features of benign models in order to detect backdoor models without knowing the attack strategy. After that, we dynamically combine the GAE and one-class classifier optimization goals to form classification boundaries that distinguish backdoor models from benign models. Our OCGEC combines the powerful representation capabilities of graph neural networks with the utility of one-class classification techniques in the field of anomaly detection. In comparison to other baselines, it achieves AUC scores of more than 98% on a number of tasks, which far exceeds existing methods for detection even when they rely on a huge number of positive and negative samples. Our pioneering application of graphic scenarios for generic backdoor detection can provide new insights that can be used to improve other backdoor defense tasks. Code is available at https://github.com/jhy549/OCGEC.
Language Models are Super Mario: Absorbing Abilities from Homologous Models as a Free Lunch
Nov 06, 2023In this paper, we uncover that Language Models (LMs), either encoder- or decoder-based, can obtain new capabilities by assimilating the parameters of homologous models without retraining or GPUs. Typically, new abilities of LMs can be imparted by Supervised Fine-Tuning (SFT), reflected in the disparity between fine-tuned and pre-trained parameters (i.e., delta parameters). We initially observe that by introducing a novel operation called DARE (Drop And REscale), most delta parameters can be directly set to zeros without affecting the capabilities of SFT LMs and larger models can tolerate a higher proportion of discarded parameters. Based on this observation, we further sparsify delta parameters of multiple SFT homologous models with DARE and subsequently merge them into a single model by parameter averaging. We conduct experiments on eight datasets from the GLUE benchmark with BERT and RoBERTa. We also merge WizardLM, WizardMath, and Code Alpaca based on Llama 2. Experimental results show that: (1) The delta parameter value ranges for SFT models are typically small, often within 0.005, and DARE can eliminate 99% of them effortlessly. However, once the models are continuously pre-trained, the value ranges can grow to around 0.03, making DARE impractical. We have also tried to remove fine-tuned instead of delta parameters and find that a 10% reduction can lead to drastically decreased performance (even to 0). This highlights that SFT merely stimulates the abilities via delta parameters rather than injecting new abilities into LMs; (2) DARE can merge multiple task-specific LMs into one LM with diverse abilities. For instance, the merger of WizardLM and WizardMath improves the GSM8K zero-shot accuracy of WizardLM from 2.2 to 66.3, retaining its instruction-following ability while surpassing WizardMath's original 64.2 performance. Codes are available at https://github.com/yule-BUAA/MergeLM.
Diversify Question Generation with Retrieval-Augmented Style Transfer
Oct 23, 2023Given a textual passage and an answer, humans are able to ask questions with various expressions, but this ability is still challenging for most question generation (QG) systems. Existing solutions mainly focus on the internal knowledge within the given passage or the semantic word space for diverse content planning. These methods, however, have not considered the potential of external knowledge for expression diversity. To bridge this gap, we propose RAST, a framework for Retrieval-Augmented Style Transfer, where the objective is to utilize the style of diverse templates for question generation. For training RAST, we develop a novel Reinforcement Learning (RL) based approach that maximizes a weighted combination of diversity reward and consistency reward. Here, the consistency reward is computed by a Question-Answering (QA) model, whereas the diversity reward measures how much the final output mimics the retrieved template. Experimental results show that our method outperforms previous diversity-driven baselines on diversity while being comparable in terms of consistency scores. Our code is available at https://github.com/gouqi666/RAST.