 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNan Li
CSST Strong Lensing Preparation: a Framework for Detecting Strong Lenses in the Multi-color Imaging Survey by the China Survey Space Telescope (CSST)
Apr 02, 2024
Strong gravitational lensing is a powerful tool for investigating dark matter and dark energy properties. With the advent of large-scale sky surveys, we can discover strong lensing systems on an unprecedented scale, which requires efficient tools to extract them from billions of astronomical objects. The existing mainstream lens-finding tools are based on machine learning algorithms and applied to cut-out-centered galaxies. However, according to the design and survey strategy of optical surveys by CSST, preparing cutouts with multiple bands requires considerable efforts. To overcome these challenges, we have developed a framework based on a hierarchical visual Transformer with a sliding window technique to search for strong lensing systems within entire images. Moreover, given that multi-color images of strong lensing systems can provide insights into their physical characteristics, our framework is specifically crafted to identify strong lensing systems in images with any number of channels. As evaluated using CSST mock data based on an Semi-Analytic Model named CosmoDC2, our framework achieves precision and recall rates of 0.98 and 0.90, respectively. To evaluate the effectiveness of our method in real observations, we have applied it to a subset of images from the DESI Legacy Imaging Surveys and media images from Euclid Early Release Observations. 61 new strong lensing system candidates are discovered by our method. However, we also identified false positives arising primarily from the simplified galaxy morphology assumptions within the simulation. This underscores the practical limitations of our approach while simultaneously highlighting potential avenues for future improvements.
Competition-Aware Decision-Making Approach for Mobile Robots in Racing Scenarios
Mar 31, 2024This paper presents a game-theoretic strategy for racing, where the autonomous ego agent seeks to block a racing opponent that aims to overtake the ego agent. After a library of trajectory candidates and an associated reward matrix are constructed, the optimal trajectory in terms of maximizing the cumulative reward over the planning horizon is determined based on the level-K reasoning framework. In particular, the level of the opponent is estimated online according to its behavior over a past window and is then used to determine the trajectory for the ego agent. Taking into account that the opponent may change its level and strategy during the decision process of the ego agent, we introduce a trajectory mixing strategy that blends the level-K optimal trajectory with a fail-safe trajectory. The overall algorithm was tested and evaluated in various simulated racing scenarios, which also includes human-in-the-loop experiments. Comparative analysis against the conventional level-K framework demonstrates the superiority of our proposed approach in terms of overtake-blocking success rates.
sVAD: A Robust, Low-Power, and Light-Weight Voice Activity Detection with Spiking Neural Networks
Mar 09, 2024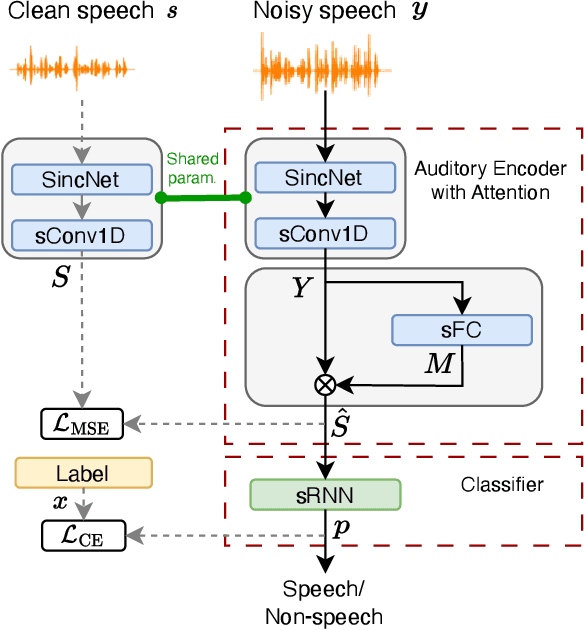
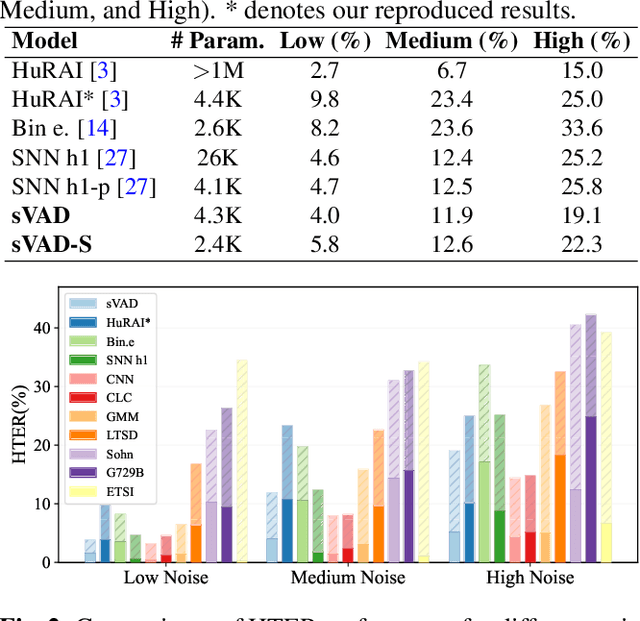
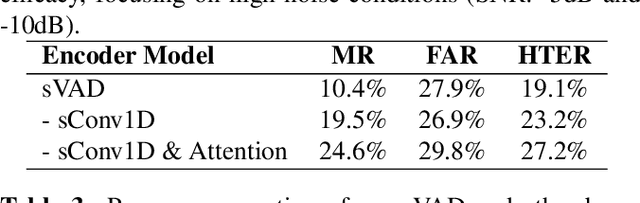
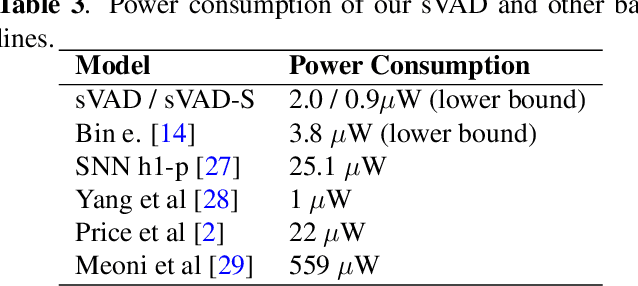
Speech applications are expected to be low-power and robust under noisy conditions. An effective Voice Activity Detection (VAD) front-end lowers the computational need. Spiking Neural Networks (SNNs) are known to be biologically plausible and power-efficient. However, SNN-based VADs have yet to achieve noise robustness and often require large models for high performance. This paper introduces a novel SNN-based VAD model, referred to as sVAD, which features an auditory encoder with an SNN-based attention mechanism. Particularly, it provides effective auditory feature representation through SincNet and 1D convolution, and improves noise robustness with attention mechanisms. The classifier utilizes Spiking Recurrent Neural Networks (sRNN) to exploit temporal speech information. Experimental results demonstrate that our sVAD achieves remarkable noise robustness and meanwhile maintains low power consumption and a small footprint, making it a promising solution for real-world VAD applications.
KS-Net: Multi-band joint speech restoration and enhancement network for 2024 ICASSP SSI Challenge
Feb 02, 2024This paper presents the speech restoration and enhancement system created by the 1024K team for the ICASSP 2024 Speech Signal Improvement (SSI) Challenge. Our system consists of a generative adversarial network (GAN) in complex-domain for speech restoration and a fine-grained multi-band fusion module for speech enhancement. In the blind test set of SSI, the proposed system achieves an overall mean opinion score (MOS) of 3.49 based on ITU-T P.804 and a Word Accuracy Rate (WAcc) of 0.78 for the real-time track, as well as an overall P.804 MOS of 3.43 and a WAcc of 0.78 for the non-real-time track, ranking 1st in both tracks.
Dynamic Semantic Compression for CNN Inference in Multi-access Edge Computing: A Graph Reinforcement Learning-based Autoencoder
Jan 19, 2024This paper studies the computational offloading of CNN inference in dynamic multi-access edge computing (MEC) networks. To address the uncertainties in communication time and computation resource availability, we propose a novel semantic compression method, autoencoder-based CNN architecture (AECNN), for effective semantic extraction and compression in partial offloading. In the semantic encoder, we introduce a feature compression module based on the channel attention mechanism in CNNs, to compress intermediate data by selecting the most informative features. In the semantic decoder, we design a lightweight decoder to reconstruct the intermediate data through learning from the received compressed data to improve accuracy. To effectively trade-off communication, computation, and inference accuracy, we design a reward function and formulate the offloading problem of CNN inference as a maximization problem with the goal of maximizing the average inference accuracy and throughput over the long term. To address this maximization problem, we propose a graph reinforcement learning-based AECNN (GRL-AECNN) method, which outperforms existing works DROO-AECNN, GRL-BottleNet++ and GRL-DeepJSCC under different dynamic scenarios. This highlights the advantages of GRL-AECNN in offloading decision-making in dynamic MEC.
Advanced Unstructured Data Processing for ESG Reports: A Methodology for Structured Transformation and Enhanced Analysis
Jan 04, 2024In the evolving field of corporate sustainability, analyzing unstructured Environmental, Social, and Governance (ESG) reports is a complex challenge due to their varied formats and intricate content. This study introduces an innovative methodology utilizing the "Unstructured Core Library", specifically tailored to address these challenges by transforming ESG reports into structured, analyzable formats. Our approach significantly advances the existing research by offering high-precision text cleaning, adept identification and extraction of text from images, and standardization of tables within these reports. Emphasizing its capability to handle diverse data types, including text, images, and tables, the method adeptly manages the nuances of differing page layouts and report styles across industries. This research marks a substantial contribution to the fields of industrial ecology and corporate sustainability assessment, paving the way for the application of advanced NLP technologies and large language models in the analysis of corporate governance and sustainability. Our code is available at https://github.com/linancn/TianGong-AI-Unstructure.git.
Empowering Working Memory for Large Language Model Agents
Dec 22, 2023Large language models (LLMs) have achieved impressive linguistic capabilities. However, a key limitation persists in their lack of human-like memory faculties. LLMs exhibit constrained memory retention across sequential interactions, hindering complex reasoning. This paper explores the potential of applying cognitive psychology's working memory frameworks, to enhance LLM architecture. The limitations of traditional LLM memory designs are analyzed, including their isolation of distinct dialog episodes and lack of persistent memory links. To address this, an innovative model is proposed incorporating a centralized Working Memory Hub and Episodic Buffer access to retain memories across episodes. This architecture aims to provide greater continuity for nuanced contextual reasoning during intricate tasks and collaborative scenarios. While promising, further research is required into optimizing episodic memory encoding, storage, prioritization, retrieval, and security. Overall, this paper provides a strategic blueprint for developing LLM agents with more sophisticated, human-like memory capabilities, highlighting memory mechanisms as a vital frontier in artificial general intelligence.
BAE-Net: A Low complexity and high fidelity Bandwidth-Adaptive neural network for speech super-resolution
Dec 21, 2023Speech bandwidth extension (BWE) has demonstrated promising performance in enhancing the perceptual speech quality in real communication systems. Most existing BWE researches primarily focus on fixed upsampling ratios, disregarding the fact that the effective bandwidth of captured audio may fluctuate frequently due to various capturing devices and transmission conditions. In this paper, we propose a novel streaming adaptive bandwidth extension solution dubbed BAE-Net, which is suitable to handle the low-resolution speech with unknown and varying effective bandwidth. To address the challenges of recovering both the high-frequency magnitude and phase speech content blindly, we devise a dual-stream architecture that incorporates the magnitude inpainting and phase refinement. For potential applications on edge devices, this paper also introduces BAE-NET-lite, which is a lightweight, streaming and efficient framework. Quantitative results demonstrate the superiority of BAE-Net in terms of both performance and computational efficiency when compared with existing state-of-the-art BWE methods.
OCGEC: One-class Graph Embedding Classification for DNN Backdoor Detection
Dec 04, 2023Deep neural networks (DNNs) have been found vulnerable to backdoor attacks, raising security concerns about their deployment in mission-critical applications. There are various approaches to detect backdoor attacks, however they all make certain assumptions about the target attack to be detected and require equal and huge numbers of clean and backdoor samples for training, which renders these detection methods quite limiting in real-world circumstances. This study proposes a novel one-class classification framework called One-class Graph Embedding Classification (OCGEC) that uses GNNs for model-level backdoor detection with only a little amount of clean data. First, we train thousands of tiny models as raw datasets from a small number of clean datasets. Following that, we design a ingenious model-to-graph method for converting the model's structural details and weight features into graph data. We then pre-train a generative self-supervised graph autoencoder (GAE) to better learn the features of benign models in order to detect backdoor models without knowing the attack strategy. After that, we dynamically combine the GAE and one-class classifier optimization goals to form classification boundaries that distinguish backdoor models from benign models. Our OCGEC combines the powerful representation capabilities of graph neural networks with the utility of one-class classification techniques in the field of anomaly detection. In comparison to other baselines, it achieves AUC scores of more than 98% on a number of tasks, which far exceeds existing methods for detection even when they rely on a huge number of positive and negative samples. Our pioneering application of graphic scenarios for generic backdoor detection can provide new insights that can be used to improve other backdoor defense tasks. Code is available at https://github.com/jhy549/OCGEC.
Modeling User Viewing Flow using Large Language Models for Article Recommendation
Nov 12, 2023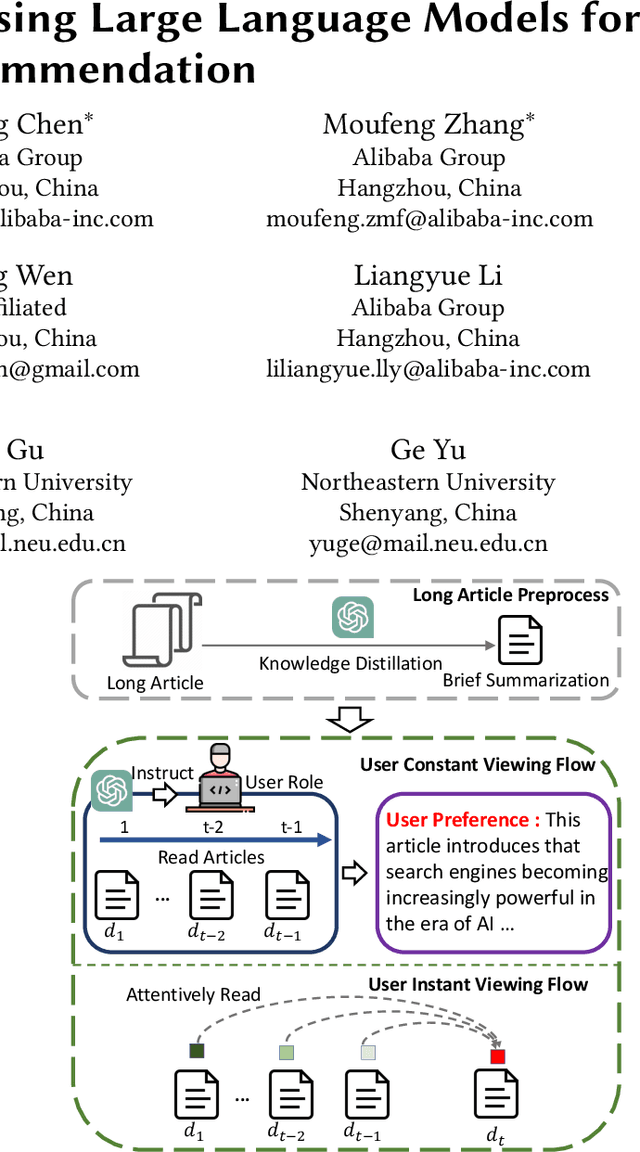

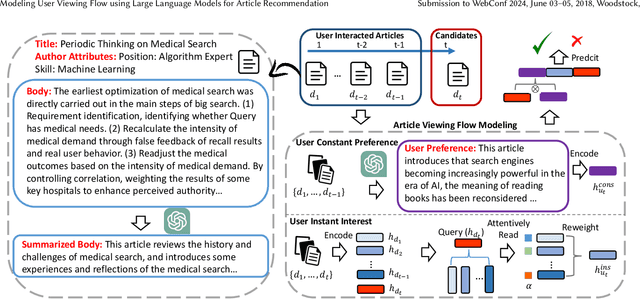
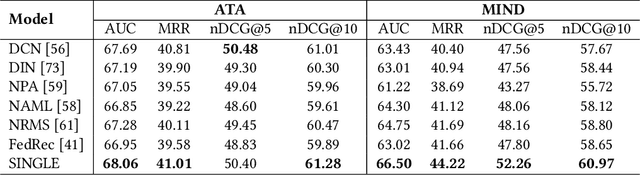
This paper proposes the User Viewing Flow Modeling (SINGLE) method for the article recommendation task, which models the user constant preference and instant interest from user-clicked articles. Specifically, we employ a user constant viewing flow modeling method to summarize the user's general interest to recommend articles. We utilize Large Language Models (LLMs) to capture constant user preferences from previously clicked articles, such as skills and positions. Then we design the user instant viewing flow modeling method to build interactions between user-clicked article history and candidate articles. It attentively reads the representations of user-clicked articles and aims to learn the user's different interest views to match the candidate article. Our experimental results on the Alibaba Technology Association (ATA) website show the advantage of SINGLE, which achieves 2.4% improvements over previous baseline models in the online A/B test. Our further analyses illustrate that SINGLE has the ability to build a more tailored recommendation system by mimicking different article viewing behaviors of users and recommending more appropriate and diverse articles to match user interests.