 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChenglin Xu
KS-Net: Multi-band joint speech restoration and enhancement network for 2024 ICASSP SSI Challenge
Feb 02, 2024
This paper presents the speech restoration and enhancement system created by the 1024K team for the ICASSP 2024 Speech Signal Improvement (SSI) Challenge. Our system consists of a generative adversarial network (GAN) in complex-domain for speech restoration and a fine-grained multi-band fusion module for speech enhancement. In the blind test set of SSI, the proposed system achieves an overall mean opinion score (MOS) of 3.49 based on ITU-T P.804 and a Word Accuracy Rate (WAcc) of 0.78 for the real-time track, as well as an overall P.804 MOS of 3.43 and a WAcc of 0.78 for the non-real-time track, ranking 1st in both tracks.
Typing to Listen at the Cocktail Party: Text-Guided Target Speaker Extraction
Oct 15, 2023
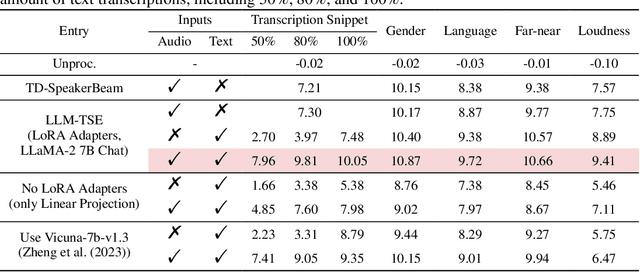

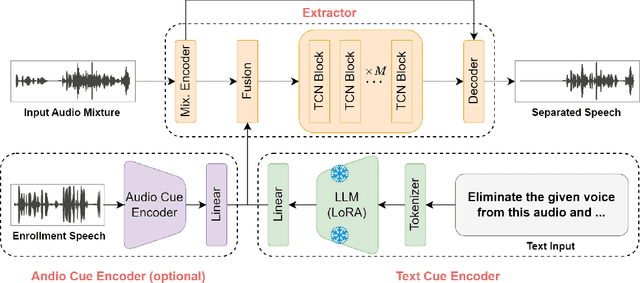
Humans possess an extraordinary ability to selectively focus on the sound source of interest amidst complex acoustic environments, commonly referred to as cocktail party scenarios. In an attempt to replicate this remarkable auditory attention capability in machines, target speaker extraction (TSE) models have been developed. These models leverage the pre-registered cues of the target speaker to extract the sound source of interest. However, the effectiveness of these models is hindered in real-world scenarios due to the unreliable or even absence of pre-registered cues. To address this limitation, this study investigates the integration of natural language description to enhance the feasibility, controllability, and performance of existing TSE models. Specifically, we propose a model named LLM-TSE, wherein a large language model (LLM) extracts useful semantic cues from the user's typed text input. These cues can serve as independent extraction cues, task selectors to control the TSE process or complement the pre-registered cues. Our experimental results demonstrate competitive performance when only text-based cues are presented, the effectiveness of using input text as a task selector, and a new state-of-the-art when combining text-based cues with pre-registered cues. To our knowledge, this is the first study to successfully incorporate LLMs to guide target speaker extraction, which can be a cornerstone for cocktail party problem research.
L-SpEx: Localized Target Speaker Extraction
Feb 21, 2022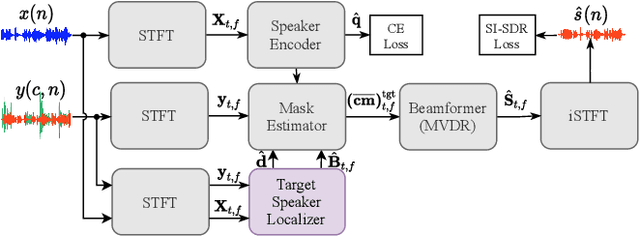
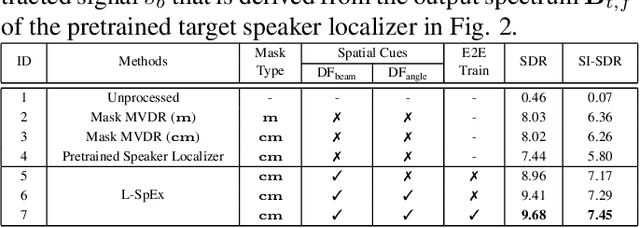

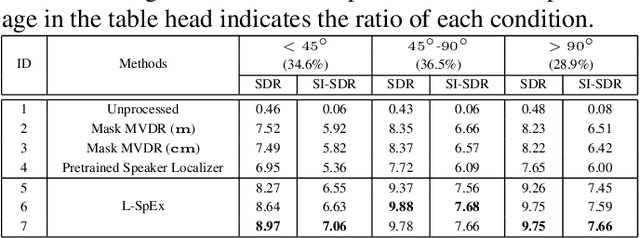
Speaker extraction aims to extract the target speaker's voice from a multi-talker speech mixture given an auxiliary reference utterance. Recent studies show that speaker extraction benefits from the location or direction of the target speaker. However, these studies assume that the target speaker's location is known in advance or detected by an extra visual cue, e.g., face image or video. In this paper, we propose an end-to-end localized target speaker extraction on pure speech cues, that is called L-SpEx. Specifically, we design a speaker localizer driven by the target speaker's embedding to extract the spatial features, including direction-of-arrival (DOA) of the target speaker and beamforming output. Then, the spatial cues and target speaker's embedding are both used to form a top-down auditory attention to the target speaker. Experiments on the multi-channel reverberant dataset called MC-Libri2Mix show that our L-SpEx approach significantly outperforms the baseline system.
Selective Hearing through Lip-reading
Jun 14, 2021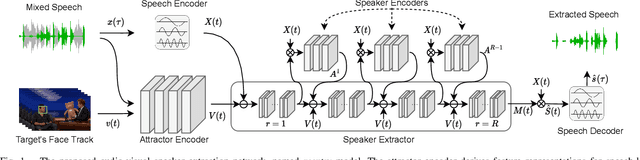
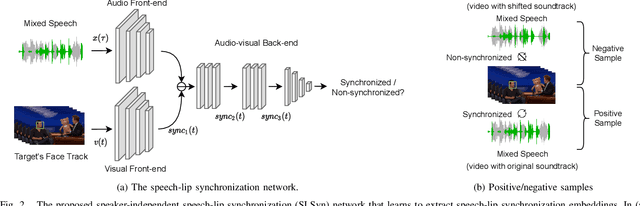
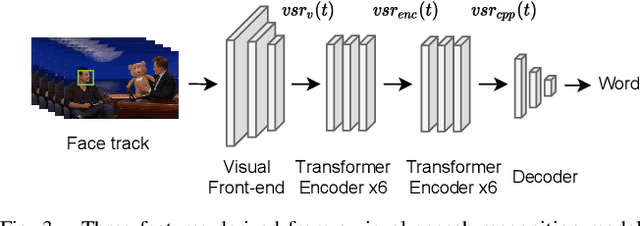
Speaker extraction algorithm emulates human's ability of selective attention to extract the target speaker's speech from a multi-talker scenario. It requires an auxiliary stimulus to form the top-down attention towards the target speaker. It has been well studied to use a reference speech as the auxiliary stimulus. Visual cues also serve as an informative reference for human listening. They are particularly useful in the presence of acoustic noise and interference speakers. We believe that the temporal synchronization between speech and its accompanying lip motion is a direct and dominant audio-visual cue. In this work, we aim to emulate human's ability of visual attention for speaker extraction based on speech-lip synchronization. We propose a self-supervised pre-training strategy, to exploit the speech-lip synchronization in a multi-talker scenario. We transfer the knowledge from the pre-trained model to a speaker extraction network. We show that the proposed speaker extraction network outperforms various competitive baselines in terms of signal quality and perceptual evaluation, achieving state-of-the-art performance.
Target Speaker Verification with Selective Auditory Attention for Single and Multi-talker Speech
Apr 02, 2021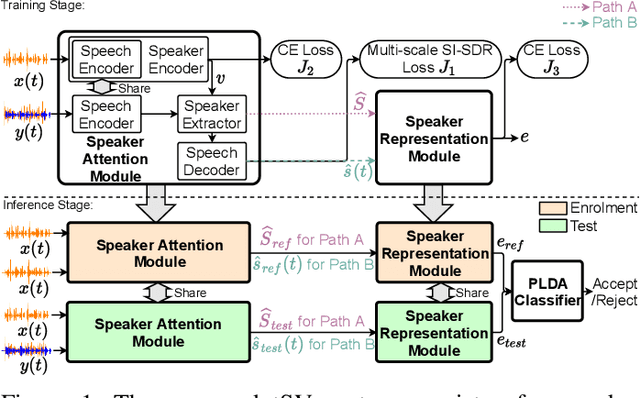
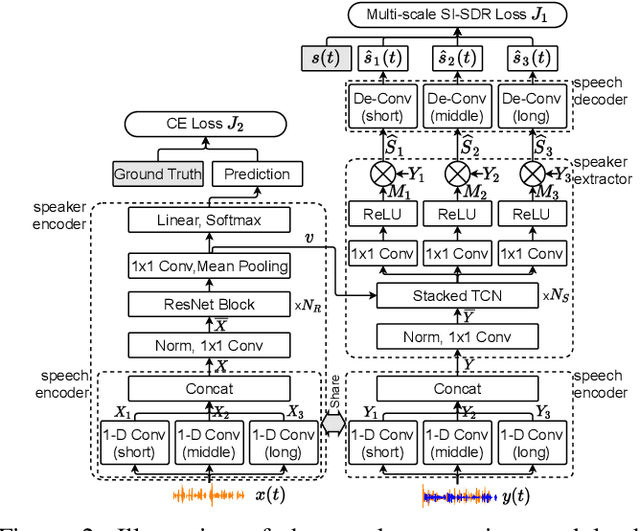
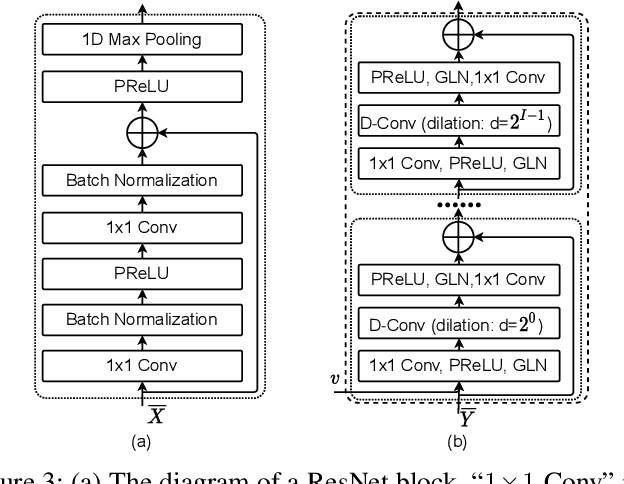

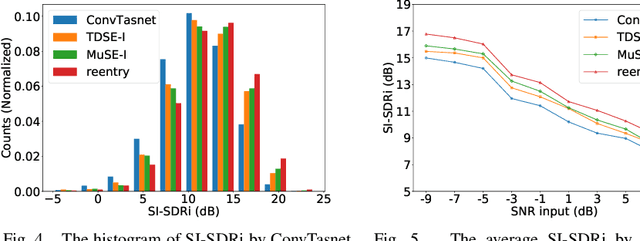
Speaker verification has been studied mostly under the single-talker condition. It is adversely affected in the presence of interference speakers. Inspired by the study on target speaker extraction, e.g., SpEx, we propose a unified speaker verification framework for both single- and multi-talker speech, that is able to pay selective auditory attention to the target speaker. This target speaker verification (tSV) framework jointly optimizes a speaker attention module and a speaker representation module via multi-task learning. We study four different target speaker embedding schemes under the tSV framework. The experimental results show that all four target speaker embedding schemes significantly outperform other competitive solutions for multi-talker speech. Notably, the best tSV speaker embedding scheme achieves 76.0% and 55.3% relative improvements over the baseline system on the WSJ0-2mix-extr and Libri2Mix corpora in terms of equal-error-rate for 2-talker speech, while the performance of tSV for single-talker speech is on par with that of traditional speaker verification system, that is trained and evaluated under the same single-talker condition.
Multi-stage Speaker Extraction with Utterance and Frame-Level Reference Signals
Nov 19, 2020
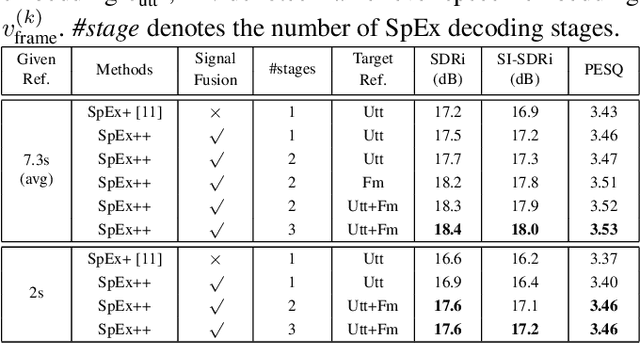
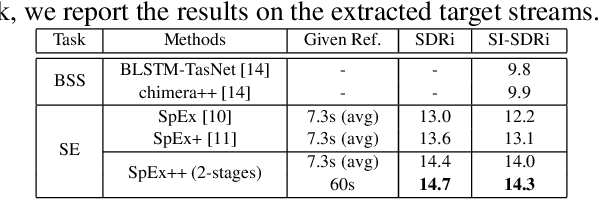
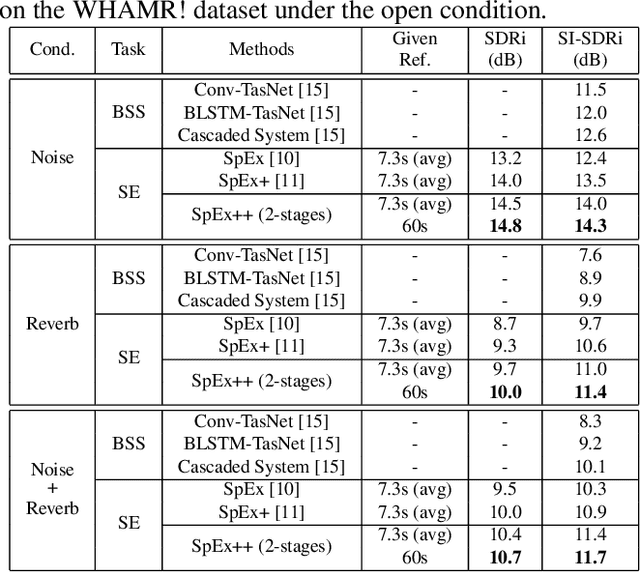
Speaker extraction uses a pre-recorded reference speech as the reference signal for target speaker extraction. In real-world applications, enrolling a speaker with a long speech is not practical. We propose a speaker extraction technique, that performs in multiple stages to take full advantage of short reference speech sample. The extracted speech in early stages is used as the reference speech for late stages. Furthermore, for the first time, we use frame-level sequential speech embedding as the reference for target speaker. This is a departure from the traditional utterance-based speaker embedding reference. In addition, a signal fusion scheme is proposed to combine the decoded signals in multiple scales with automatically learned weights. Experiments on WSJ0-2mix and its noisy versions (WHAM! and WHAMR!) show that SpEx++ consistently outperforms other state-of-the-art baselines.
Progressive Tandem Learning for Pattern Recognition with Deep Spiking Neural Networks
Jul 02, 2020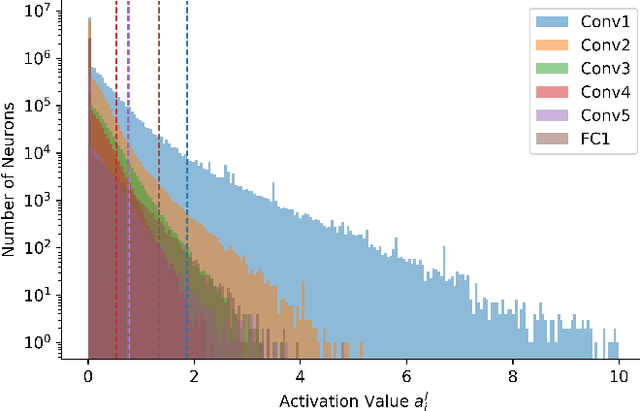
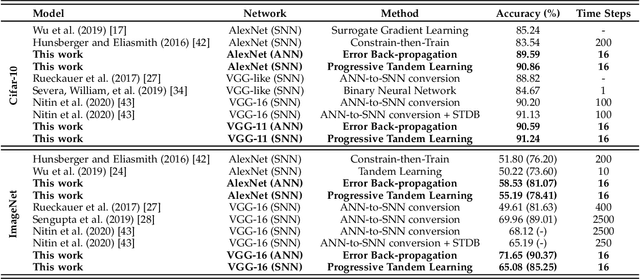
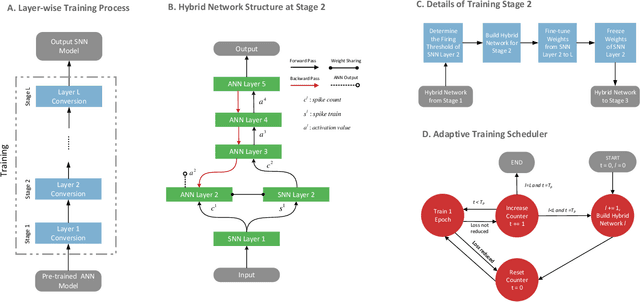
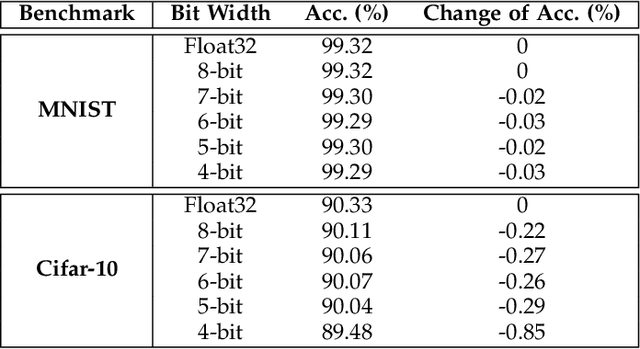
Spiking neural networks (SNNs) have shown clear advantages over traditional artificial neural networks (ANNs) for low latency and high computational efficiency, due to their event-driven nature and sparse communication. However, the training of deep SNNs is not straightforward. In this paper, we propose a novel ANN-to-SNN conversion and layer-wise learning framework for rapid and efficient pattern recognition, which is referred to as progressive tandem learning of deep SNNs. By studying the equivalence between ANNs and SNNs in the discrete representation space, a primitive network conversion method is introduced that takes full advantage of spike count to approximate the activation value of analog neurons. To compensate for the approximation errors arising from the primitive network conversion, we further introduce a layer-wise learning method with an adaptive training scheduler to fine-tune the network weights. The progressive tandem learning framework also allows hardware constraints, such as limited weight precision and fan-in connections, to be progressively imposed during training. The SNNs thus trained have demonstrated remarkable classification and regression capabilities on large-scale object recognition, image reconstruction, and speech separation tasks, while requiring at least an order of magnitude reduced inference time and synaptic operations than other state-of-the-art SNN implementations. It, therefore, opens up a myriad of opportunities for pervasive mobile and embedded devices with a limited power budget.
SpEx: Multi-Scale Time Domain Speaker Extraction Network
Apr 17, 2020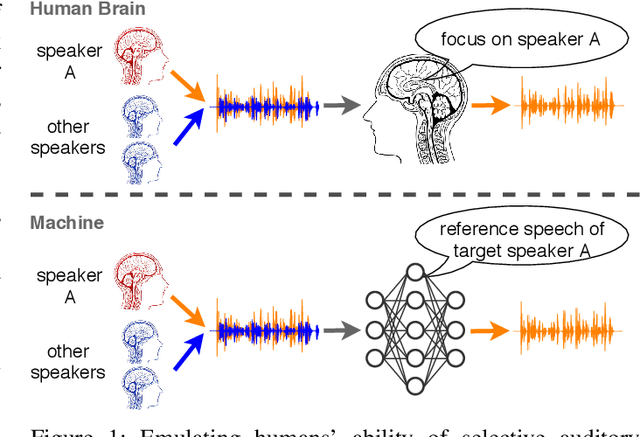
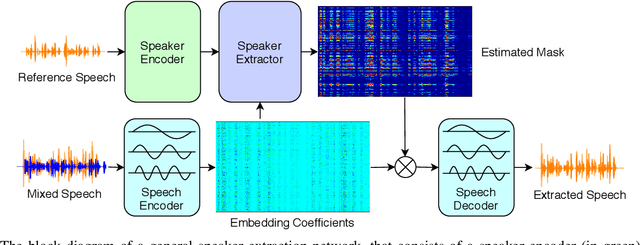
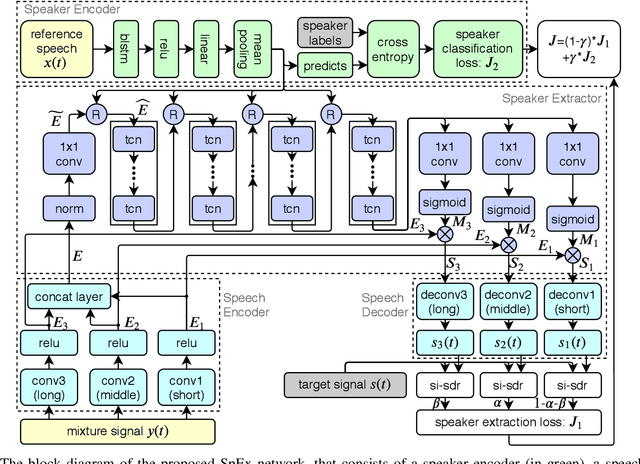

Speaker extraction aims to mimic humans' selective auditory attention by extracting a target speaker's voice from a multi-talker environment. It is common to perform the extraction in frequency-domain, and reconstruct the time-domain signal from the extracted magnitude and estimated phase spectra. However, such an approach is adversely affected by the inherent difficulty of phase estimation. Inspired by Conv-TasNet, we propose a time-domain speaker extraction network (SpEx) that converts the mixture speech into multi-scale embedding coefficients instead of decomposing the speech signal into magnitude and phase spectra. In this way, we avoid phase estimation. The SpEx network consists of four network components, namely speaker encoder, speech encoder, speaker extractor, and speech decoder. Specifically, the speech encoder converts the mixture speech into multi-scale embedding coefficients, the speaker encoder learns to represent the target speaker with a speaker embedding. The speaker extractor takes the multi-scale embedding coefficients and target speaker embedding as input and estimates a receptive mask. Finally, the speech decoder reconstructs the target speaker's speech from the masked embedding coefficients. We also propose a multi-task learning framework and a multi-scale embedding implementation. Experimental results show that the proposed SpEx achieves 37.3%, 37.7% and 15.0% relative improvements over the best baseline in terms of signal-to-distortion ratio (SDR), scale-invariant SDR (SI-SDR), and perceptual evaluation of speech quality (PESQ) under an open evaluation condition.
* ACCEPTED in IEEE/ACM Transactions on Audio, Speech, and Language Processing (TASLP)
I4U Submission to NIST SRE 2018: Leveraging from a Decade of Shared Experiences
Apr 16, 2019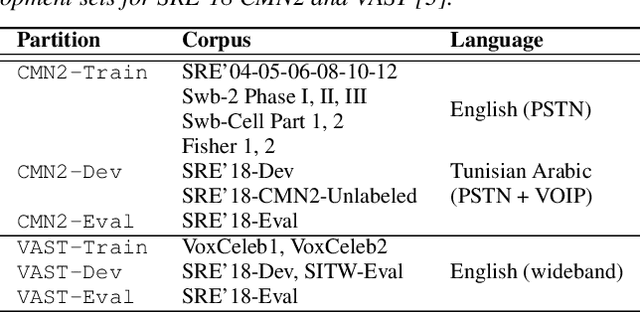
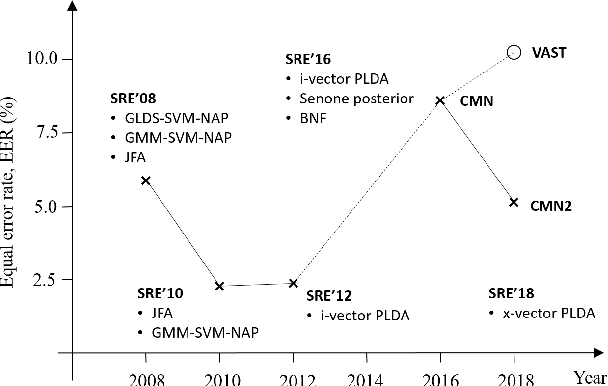
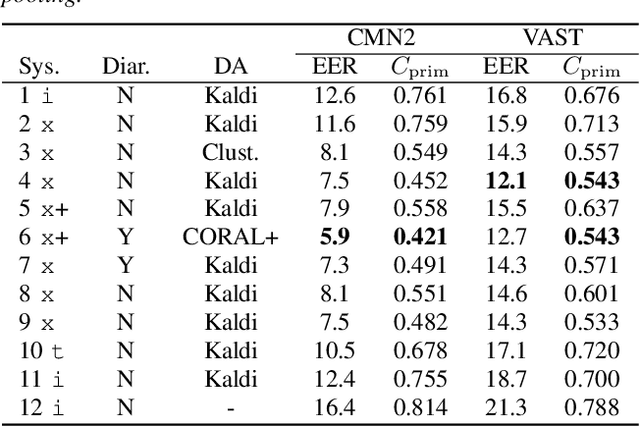
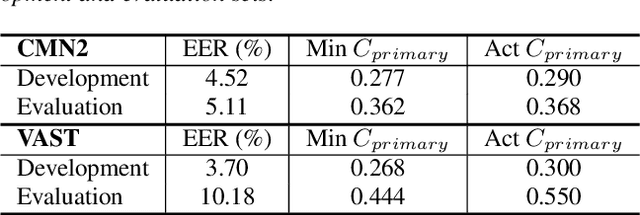
The I4U consortium was established to facilitate a joint entry to NIST speaker recognition evaluations (SRE). The latest edition of such joint submission was in SRE 2018, in which the I4U submission was among the best-performing systems. SRE'18 also marks the 10-year anniversary of I4U consortium into NIST SRE series of evaluation. The primary objective of the current paper is to summarize the results and lessons learned based on the twelve sub-systems and their fusion submitted to SRE'18. It is also our intention to present a shared view on the advancements, progresses, and major paradigm shifts that we have witnessed as an SRE participant in the past decade from SRE'08 to SRE'18. In this regard, we have seen, among others, a paradigm shift from supervector representation to deep speaker embedding, and a switch of research challenge from channel compensation to domain adaptation.
Optimization of Speaker Extraction Neural Network with Magnitude and Temporal Spectrum Approximation Loss
Mar 24, 2019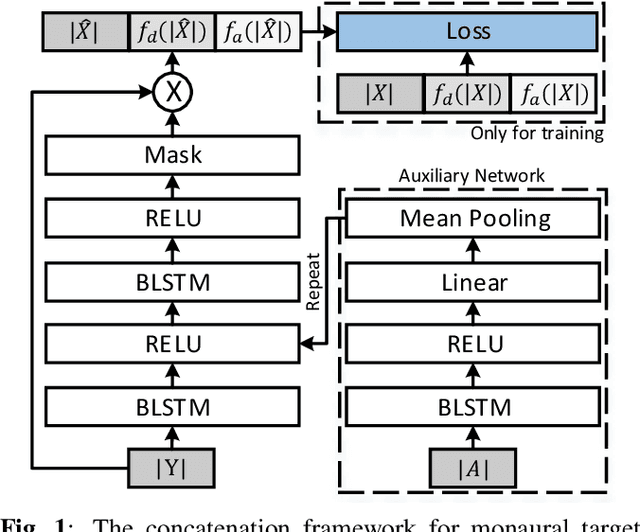
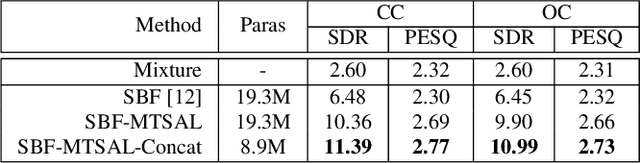

The SpeakerBeam-FE (SBF) method is proposed for speaker extraction. It attempts to overcome the problem of unknown number of speakers in an audio recording during source separation. The mask approximation loss of SBF is sub-optimal, which doesn't calculate direct signal reconstruction error and consider the speech context. To address these problems, this paper proposes a magnitude and temporal spectrum approximation loss to estimate a phase sensitive mask for the target speaker with the speaker characteristics. Moreover, this paper explores a concatenation framework instead of the context adaptive deep neural network in the SBF method to encode a speaker embedding into the mask estimation network. Experimental results under open evaluation condition show that the proposed method achieves 70.4% and 17.7% relative improvement over the SBF baseline on signal-to-distortion ratio (SDR) and perceptual evaluation of speech quality (PESQ), respectively. A further analysis demonstrates 69.1% and 72.3% relative SDR improvements obtained by the proposed method for different and same gender mixtures.