 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKong Aik Lee
Cosine Scoring with Uncertainty for Neural Speaker Embedding
Mar 11, 2024
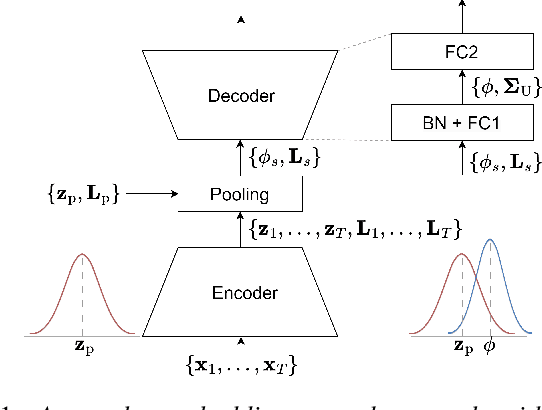
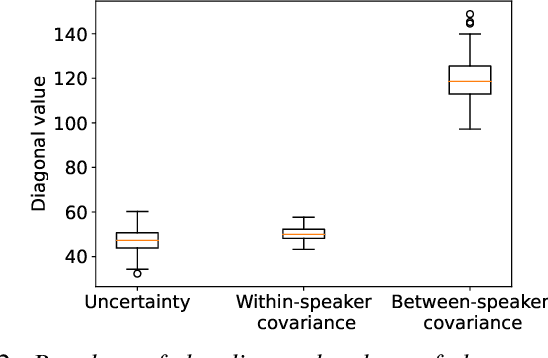
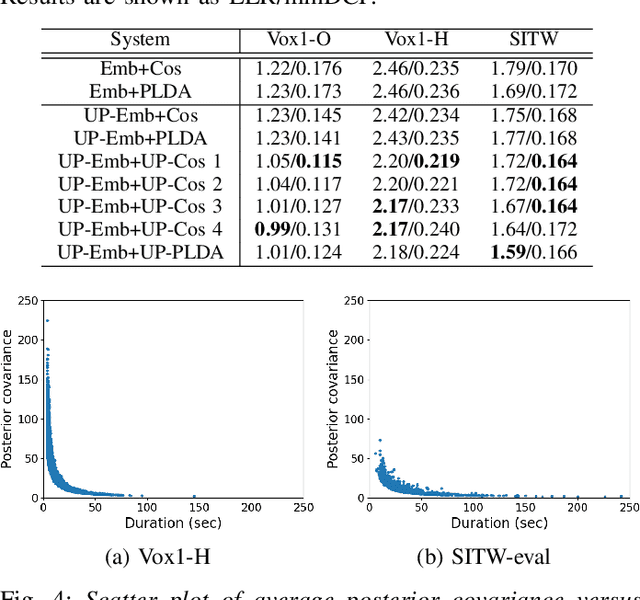

Uncertainty modeling in speaker representation aims to learn the variability present in speech utterances. While the conventional cosine-scoring is computationally efficient and prevalent in speaker recognition, it lacks the capability to handle uncertainty. To address this challenge, this paper proposes an approach for estimating uncertainty at the speaker embedding front-end and propagating it to the cosine scoring back-end. Experiments conducted on the VoxCeleb and SITW datasets confirmed the efficacy of the proposed method in handling uncertainty arising from embedding estimation. It achieved improvement with 8.5% and 9.8% average reductions in EER and minDCF compared to the conventional cosine similarity. It is also computationally efficient in practice.
* 5 pages, 4 figures
VoxGenesis: Unsupervised Discovery of Latent Speaker Manifold for Speech Synthesis
Mar 01, 2024
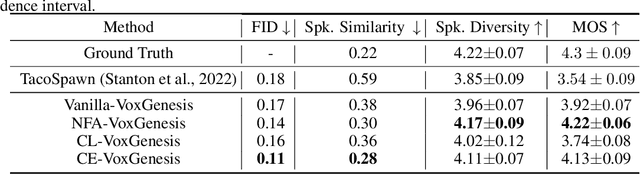
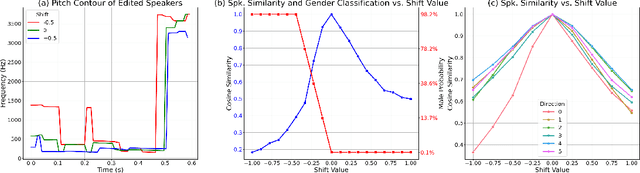

Achieving nuanced and accurate emulation of human voice has been a longstanding goal in artificial intelligence. Although significant progress has been made in recent years, the mainstream of speech synthesis models still relies on supervised speaker modeling and explicit reference utterances. However, there are many aspects of human voice, such as emotion, intonation, and speaking style, for which it is hard to obtain accurate labels. In this paper, we propose VoxGenesis, a novel unsupervised speech synthesis framework that can discover a latent speaker manifold and meaningful voice editing directions without supervision. VoxGenesis is conceptually simple. Instead of mapping speech features to waveforms deterministically, VoxGenesis transforms a Gaussian distribution into speech distributions conditioned and aligned by semantic tokens. This forces the model to learn a speaker distribution disentangled from the semantic content. During the inference, sampling from the Gaussian distribution enables the creation of novel speakers with distinct characteristics. More importantly, the exploration of latent space uncovers human-interpretable directions associated with specific speaker characteristics such as gender attributes, pitch, tone, and emotion, allowing for voice editing by manipulating the latent codes along these identified directions. We conduct extensive experiments to evaluate the proposed VoxGenesis using both subjective and objective metrics, finding that it produces significantly more diverse and realistic speakers with distinct characteristics than the previous approaches. We also show that latent space manipulation produces consistent and human-identifiable effects that are not detrimental to the speech quality, which was not possible with previous approaches. Audio samples of VoxGenesis can be found at: \url{https://bit.ly/VoxGenesis}.
Generalizing Speaker Verification for Spoof Awareness in the Embedding Space
Jan 28, 2024It is now well-known that automatic speaker verification (ASV) systems can be spoofed using various types of adversaries. The usual approach to counteract ASV systems against such attacks is to develop a separate spoofing countermeasure (CM) module to classify speech input either as a bonafide, or a spoofed utterance. Nevertheless, such a design requires additional computation and utilization efforts at the authentication stage. An alternative strategy involves a single monolithic ASV system designed to handle both zero-effort imposter (non-targets) and spoofing attacks. Such spoof-aware ASV systems have the potential to provide stronger protections and more economic computations. To this end, we propose to generalize the standalone ASV (G-SASV) against spoofing attacks, where we leverage limited training data from CM to enhance a simple backend in the embedding space, without the involvement of a separate CM module during the test (authentication) phase. We propose a novel yet simple backend classifier based on deep neural networks and conduct the study via domain adaptation and multi-task integration of spoof embeddings at the training stage. Experiments are conducted on the ASVspoof 2019 logical access dataset, where we improve the performance of statistical ASV backends on the joint (bonafide and spoofed) and spoofed conditions by a maximum of 36.2% and 49.8% in terms of equal error rates, respectively.
Gradient weighting for speaker verification in extremely low Signal-to-Noise Ratio
Jan 05, 2024Speaker verification is hampered by background noise, particularly at extremely low Signal-to-Noise Ratio (SNR) under 0 dB. It is difficult to suppress noise without introducing unwanted artifacts, which adversely affects speaker verification. We proposed the mechanism called Gradient Weighting (Grad-W), which dynamically identifies and reduces artifact noise during prediction. The mechanism is based on the property that the gradient indicates which parts of the input the model is paying attention to. Specifically, when the speaker network focuses on a region in the denoised utterance but not on the clean counterpart, we consider it artifact noise and assign higher weights for this region during optimization of enhancement. We validate it by training an enhancement model and testing the enhanced utterance on speaker verification. The experimental results show that our approach effectively reduces artifact noise, improving speaker verification across various SNR levels.
Golden Gemini is All You Need: Finding the Sweet Spots for Speaker Verification
Dec 06, 2023Previous studies demonstrate the impressive performance of residual neural networks (ResNet) in speaker verification. The ResNet models treat the time and frequency dimensions equally. They follow the default stride configuration designed for image recognition, where the horizontal and vertical axes exhibit similarities. This approach ignores the fact that time and frequency are asymmetric in speech representation. In this paper, we address this issue and look for optimal stride configurations specifically tailored for speaker verification. We represent the stride space on a trellis diagram, and conduct a systematic study on the impact of temporal and frequency resolutions on the performance and further identify two optimal points, namely Golden Gemini, which serves as a guiding principle for designing 2D ResNet-based speaker verification models. By following the principle, a state-of-the-art ResNet baseline model gains a significant performance improvement on VoxCeleb, SITW, and CNCeleb datasets with 7.70%/11.76% average EER/minDCF reductions, respectively, across different network depths (ResNet18, 34, 50, and 101), while reducing the number of parameters by 16.5% and FLOPs by 4.1%. We refer to it as Gemini ResNet. Further investigation reveals the efficacy of the proposed Golden Gemini operating points across various training conditions and architectures. Furthermore, we present a new benchmark, namely the Gemini DF-ResNet, using a cutting-edge model.
Partially Randomizing Transformer Weights for Dialogue Response Diversity
Nov 18, 2023Despite recent progress in generative open-domain dialogue, the issue of low response diversity persists. Prior works have addressed this issue via either novel objective functions, alternative learning approaches such as variational frameworks, or architectural extensions such as the Randomized Link (RL) Transformer. However, these approaches typically entail either additional difficulties during training/inference, or a significant increase in model size and complexity. Hence, we propose the \underline{Pa}rtially \underline{Ra}ndomized trans\underline{Former} (PaRaFormer), a simple extension of the transformer which involves freezing the weights of selected layers after random initialization. Experimental results reveal that the performance of the PaRaformer is comparable to that of the aforementioned approaches, despite not entailing any additional training difficulty or increase in model complexity.
An Empirical Bayes Framework for Open-Domain Dialogue Generation
Nov 18, 2023To engage human users in meaningful conversation, open-domain dialogue agents are required to generate diverse and contextually coherent dialogue. Despite recent advancements, which can be attributed to the usage of pretrained language models, the generation of diverse and coherent dialogue remains an open research problem. A popular approach to address this issue involves the adaptation of variational frameworks. However, while these approaches successfully improve diversity, they tend to compromise on contextual coherence. Hence, we propose the Bayesian Open-domain Dialogue with Empirical Bayes (BODEB) framework, an empirical bayes framework for constructing an Bayesian open-domain dialogue agent by leveraging pretrained parameters to inform the prior and posterior parameter distributions. Empirical results show that BODEB achieves better results in terms of both diversity and coherence compared to variational frameworks.
Disentangling Voice and Content with Self-Supervision for Speaker Recognition
Oct 02, 2023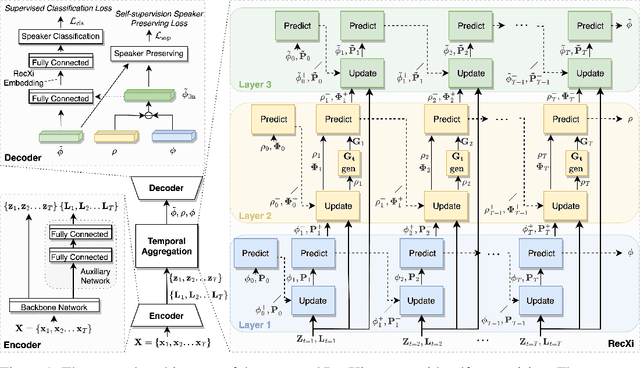


For speaker recognition, it is difficult to extract an accurate speaker representation from speech because of its mixture of speaker traits and content. This paper proposes a disentanglement framework that simultaneously models speaker traits and content variability in speech. It is realized with the use of three Gaussian inference layers, each consisting of a learnable transition model that extracts distinct speech components. Notably, a strengthened transition model is specifically designed to model complex speech dynamics. We also propose a self-supervision method to dynamically disentangle content without the use of labels other than speaker identities. The efficacy of the proposed framework is validated via experiments conducted on the VoxCeleb and SITW datasets with 9.56% and 8.24% average reductions in EER and minDCF, respectively. Since neither additional model training nor data is specifically needed, it is easily applicable in practical use.
Emphasized Non-Target Speaker Knowledge in Knowledge Distillation for Automatic Speaker Verification
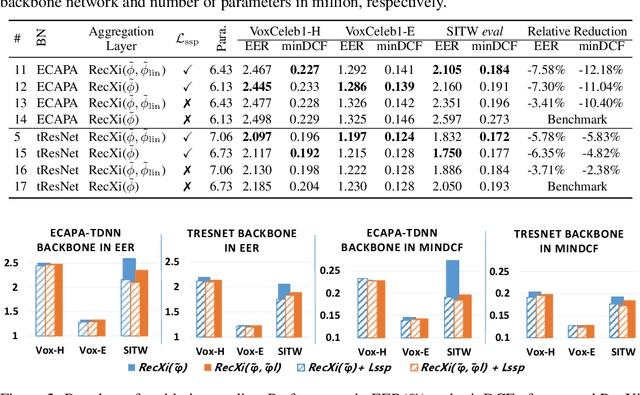
Sep 26, 2023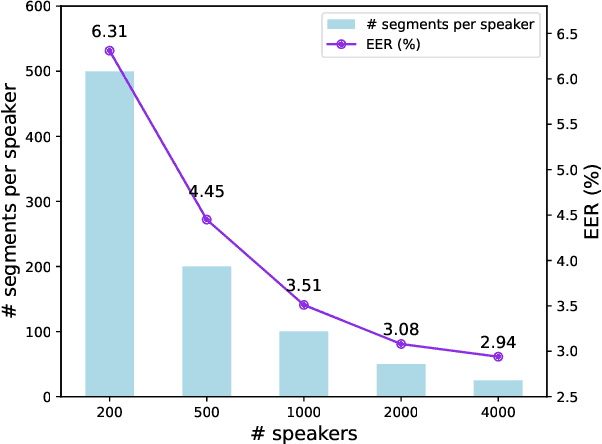
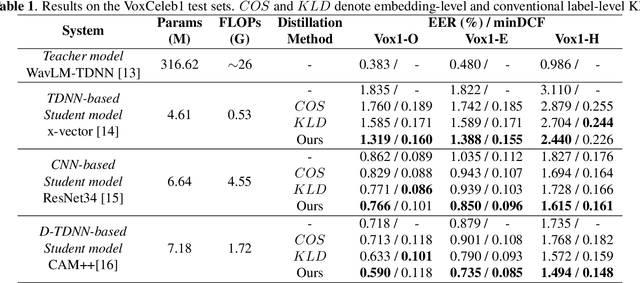


Knowledge distillation (KD) is used to enhance automatic speaker verification performance by ensuring consistency between large teacher networks and lightweight student networks at the embedding level or label level. However, the conventional label-level KD overlooks the significant knowledge from non-target speakers, particularly their classification probabilities, which can be crucial for automatic speaker verification. In this paper, we first demonstrate that leveraging a larger number of training non-target speakers improves the performance of automatic speaker verification models. Inspired by this finding about the importance of non-target speakers' knowledge, we modified the conventional label-level KD by disentangling and emphasizing the classification probabilities of non-target speakers during knowledge distillation. The proposed method is applied to three different student model architectures and achieves an average of 13.67% improvement in EER on the VoxCeleb dataset compared to embedding-level and conventional label-level KD methods.
The second multi-channel multi-party meeting transcription challenge (M2MeT) 2.0): A benchmark for speaker-attributed ASR
Sep 24, 2023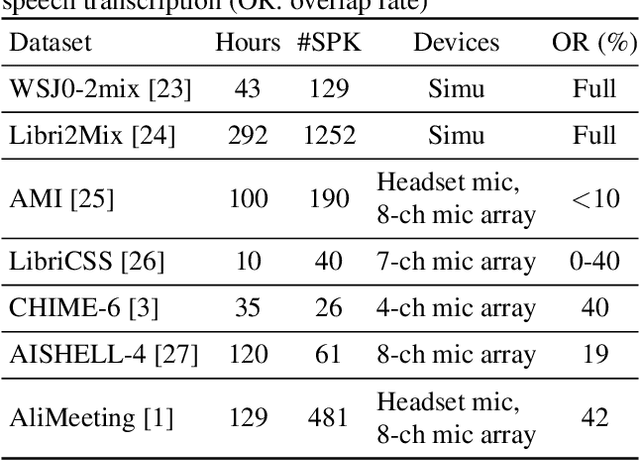
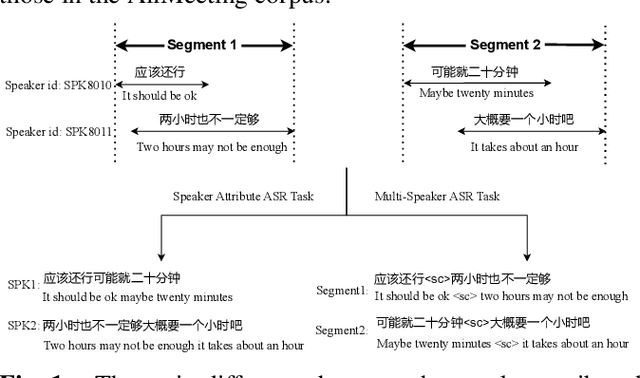
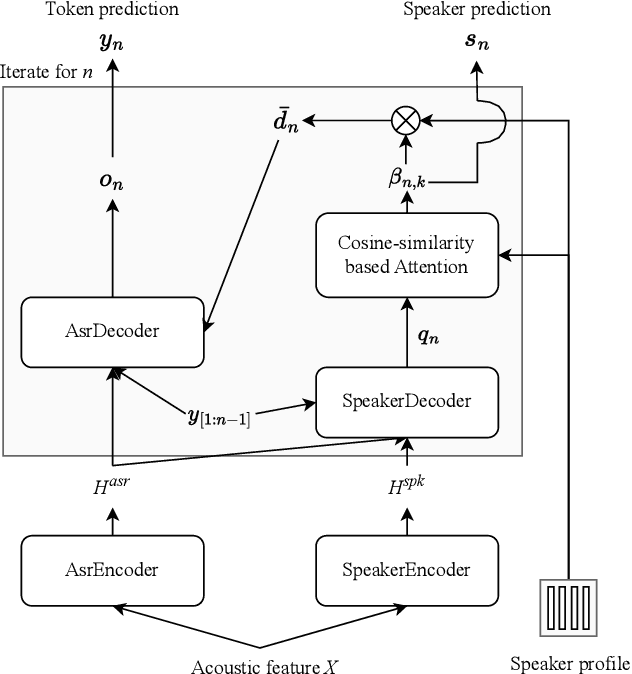

With the success of the first Multi-channel Multi-party Meeting Transcription challenge (M2MeT), the second M2MeT challenge (M2MeT 2.0) held in ASRU2023 particularly aims to tackle the complex task of speaker-attributed ASR (SA-ASR), which directly addresses the practical and challenging problem of "who spoke what at when" at typical meeting scenario. We particularly established two sub-tracks. 1) The fixed training condition sub-track, where the training data is constrained to predetermined datasets, but participants can use any open-source pre-trained model. 2) The open training condition sub-track, which allows for the use of all available data and models. In addition, we release a new 10-hour test set for challenge ranking. This paper provides an overview of the dataset, track settings, results, and analysis of submitted systems, as a benchmark to show the current state of speaker-attributed ASR.