 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHui Bu
ICMC-ASR: The ICASSP 2024 In-Car Multi-Channel Automatic Speech Recognition Challenge
Jan 07, 2024
To promote speech processing and recognition research in driving scenarios, we build on the success of the Intelligent Cockpit Speech Recognition Challenge (ICSRC) held at ISCSLP 2022 and launch the ICASSP 2024 In-Car Multi-Channel Automatic Speech Recognition (ICMC-ASR) Challenge. This challenge collects over 100 hours of multi-channel speech data recorded inside a new energy vehicle and 40 hours of noise for data augmentation. Two tracks, including automatic speech recognition (ASR) and automatic speech diarization and recognition (ASDR) are set up, using character error rate (CER) and concatenated minimum permutation character error rate (cpCER) as evaluation metrics, respectively. Overall, the ICMC-ASR Challenge attracts 98 participating teams and receives 53 valid results in both tracks. In the end, first-place team USTCiflytek achieves a CER of 13.16% in the ASR track and a cpCER of 21.48% in the ASDR track, showing an absolute improvement of 13.08% and 51.4% compared to our challenge baseline, respectively.
The second multi-channel multi-party meeting transcription challenge (M2MeT) 2.0): A benchmark for speaker-attributed ASR
Sep 24, 2023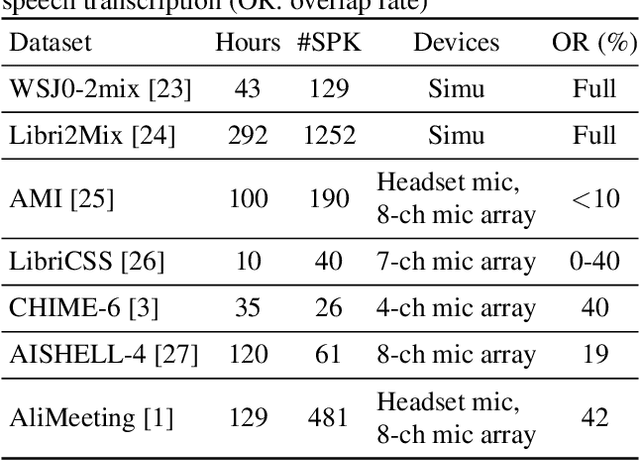
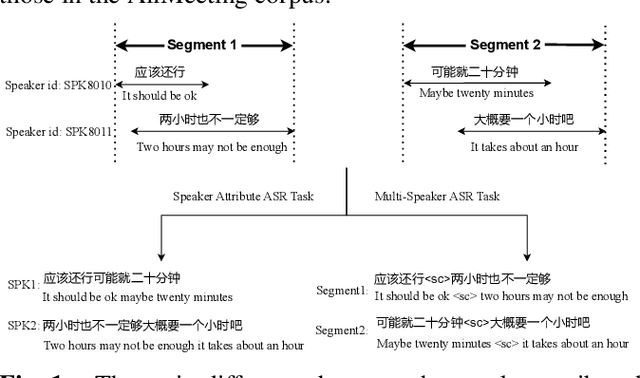
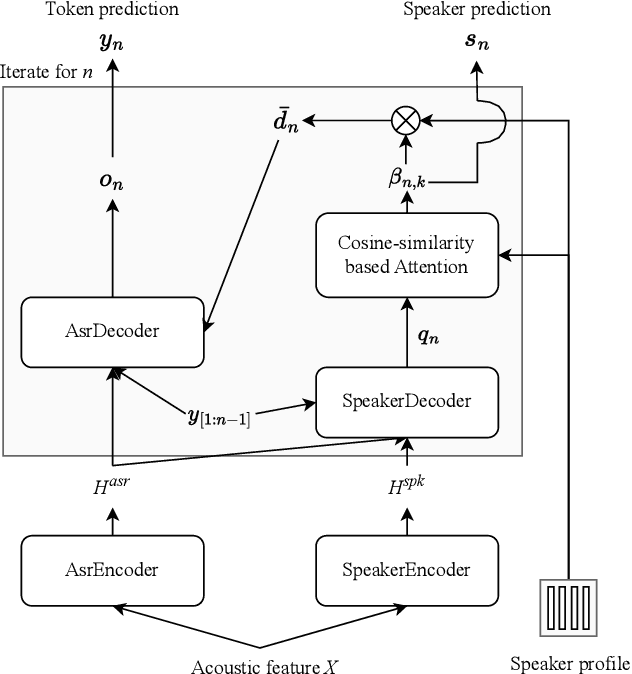

With the success of the first Multi-channel Multi-party Meeting Transcription challenge (M2MeT), the second M2MeT challenge (M2MeT 2.0) held in ASRU2023 particularly aims to tackle the complex task of speaker-attributed ASR (SA-ASR), which directly addresses the practical and challenging problem of "who spoke what at when" at typical meeting scenario. We particularly established two sub-tracks. 1) The fixed training condition sub-track, where the training data is constrained to predetermined datasets, but participants can use any open-source pre-trained model. 2) The open training condition sub-track, which allows for the use of all available data and models. In addition, we release a new 10-hour test set for challenge ranking. This paper provides an overview of the dataset, track settings, results, and analysis of submitted systems, as a benchmark to show the current state of speaker-attributed ASR.
The ISCSLP 2022 Intelligent Cockpit Speech Recognition Challenge (ICSRC): Dataset, Tracks, Baseline and Results
Nov 03, 2022



This paper summarizes the outcomes from the ISCSLP 2022 Intelligent Cockpit Speech Recognition Challenge (ICSRC). We first address the necessity of the challenge and then introduce the associated dataset collected from a new-energy vehicle (NEV) covering a variety of cockpit acoustic conditions and linguistic contents. We then describe the track arrangement and the baseline system. Specifically, we set up two tracks in terms of allowed model/system size to investigate resource-constrained and -unconstrained setups, targeting to vehicle embedded as well as cloud ASR systems respectively. Finally we summarize the challenge results and provide the major observations from the submitted systems.
The 2022 Far-field Speaker Verification Challenge: Exploring domain mismatch and semi-supervised learning under the far-field scenario
Sep 16, 2022



FFSVC2022 is the second challenge of far-field speaker verification. FFSVC2022 provides the fully-supervised far-field speaker verification to further explore the far-field scenario and proposes semi-supervised far-field speaker verification. In contrast to FFSVC2020, FFSVC2022 focus on the single-channel scenario. In addition, a supplementary set for the FFSVC2020 dataset is released this year. The supplementary set consists of more recording devices and has the same data distribution as the FFSVC2022 evaluation set. This paper summarizes the FFSVC 2022, including tasks description, trial designing details, a baseline system and a summary of challenge results. The challenge results indicate substantial progress made in the field but also present that there are still difficulties with the far-field scenario.
Summary On The ICASSP 2022 Multi-Channel Multi-Party Meeting Transcription Grand Challenge
Feb 08, 2022



The ICASSP 2022 Multi-channel Multi-party Meeting Transcription Grand Challenge (M2MeT) focuses on one of the most valuable and the most challenging scenarios of speech technologies. The M2MeT challenge has particularly set up two tracks, speaker diarization (track 1) and multi-speaker automatic speech recognition (ASR) (track 2). Along with the challenge, we released 120 hours of real-recorded Mandarin meeting speech data with manual annotation, including far-field data collected by 8-channel microphone array as well as near-field data collected by each participants' headset microphone. We briefly describe the released dataset, track setups, baselines and summarize the challenge results and major techniques used in the submissions.
WenetSpeech: A 10000+ Hours Multi-domain Mandarin Corpus for Speech Recognition
Oct 18, 2021



In this paper, we present WenetSpeech, a multi-domain Mandarin corpus consisting of 10000+ hours high-quality labeled speech, 2400+ hours weakly labeled speech, and about 10000 hours unlabeled speech, with 22400+ hours in total. We collect the data from YouTube and Podcast, which covers a variety of speaking styles, scenarios, domains, topics, and noisy conditions. An optical character recognition (OCR) based method is introduced to generate the audio/text segmentation candidates for the YouTube data on its corresponding video captions, while a high-quality ASR transcription system is used to generate audio/text pair candidates for the Podcast data. Then we propose a novel end-to-end label error detection approach to further validate and filter the candidates. We also provide three manually labelled high-quality test sets along with WenetSpeech for evaluation -- Dev for cross-validation purpose in training, Test_Net, collected from Internet for matched test, and Test\_Meeting, recorded from real meetings for more challenging mismatched test. Baseline systems trained with WenetSpeech are provided for three popular speech recognition toolkits, namely Kaldi, ESPnet, and WeNet, and recognition results on the three test sets are also provided as benchmarks. To the best of our knowledge, WenetSpeech is the current largest open-sourced Mandarin speech corpus with transcriptions, which benefits research on production-level speech recognition.
M2MeT: The ICASSP 2022 Multi-Channel Multi-Party Meeting Transcription Challenge
Oct 14, 2021



Recent development of speech signal processing, such as speech recognition, speaker diarization, etc., has inspired numerous applications of speech technologies. The meeting scenario is one of the most valuable and, at the same time, most challenging scenarios for speech technologies. Speaker diarization and multi-speaker automatic speech recognition in meeting scenarios have attracted increasing attention. However, the lack of large public real meeting data has been a major obstacle for advancement of the field. Therefore, we release the \emph{AliMeeting} corpus, which consists of 120 hours of real recorded Mandarin meeting data, including far-field data collected by 8-channel microphone array as well as near-field data collected by each participants' headset microphone. Moreover, we will launch the Multi-channel Multi-party Meeting Transcription Challenge (M2MeT), as an ICASSP2022 Signal Processing Grand Challenge. The challenge consists of two tracks, namely speaker diarization and multi-speaker ASR. In this paper we provide a detailed introduction of the dateset, rules, evaluation methods and baseline systems, aiming to further promote reproducible research in this field.
AISHELL-4: An Open Source Dataset for Speech Enhancement, Separation, Recognition and Speaker Diarization in Conference Scenario
Apr 08, 2021



In this paper, we present AISHELL-4, a sizable real-recorded Mandarin speech dataset collected by 8-channel circular microphone array for speech processing in conference scenario. The dataset consists of 211 recorded meeting sessions, each containing 4 to 8 speakers, with a total length of 118 hours. This dataset aims to bride the advanced research on multi-speaker processing and the practical application scenario in three aspects. With real recorded meetings, AISHELL-4 provides realistic acoustics and rich natural speech characteristics in conversation such as short pause, speech overlap, quick speaker turn, noise, etc. Meanwhile, the accurate transcription and speaker voice activity are provided for each meeting in AISHELL-4. This allows the researchers to explore different aspects in meeting processing, ranging from individual tasks such as speech front-end processing, speech recognition and speaker diarization, to multi-modality modeling and joint optimization of relevant tasks. Given most open source dataset for multi-speaker tasks are in English, AISHELL-4 is the only Mandarin dataset for conversation speech, providing additional value for data diversity in speech community.
The Multi-speaker Multi-style Voice Cloning Challenge 2021
Apr 05, 2021

The Multi-speaker Multi-style Voice Cloning Challenge (M2VoC) aims to provide a common sizable dataset as well as a fair testbed for the benchmarking of the popular voice cloning task. Specifically, we formulate the challenge to adapt an average TTS model to the stylistic target voice with limited data from target speaker, evaluated by speaker identity and style similarity. The challenge consists of two tracks, namely few-shot track and one-shot track, where the participants are required to clone multiple target voices with 100 and 5 samples respectively. There are also two sub-tracks in each track. For sub-track a, to fairly compare different strategies, the participants are allowed to use only the training data provided by the organizer strictly. For sub-track b, the participants are allowed to use any data publicly available. In this paper, we present a detailed explanation on the tasks and data used in the challenge, followed by a summary of submitted systems and evaluation results.
INTERSPEECH 2021 ConferencingSpeech Challenge: Towards Far-field Multi-Channel Speech Enhancement for Video Conferencing
Apr 02, 2021


The ConferencingSpeech 2021 challenge is proposed to stimulate research on far-field multi-channel speech enhancement for video conferencing. The challenge consists of two separate tasks: 1) Task 1 is multi-channel speech enhancement with single microphone array and focusing on practical application with real-time requirement and 2) Task 2 is multi-channel speech enhancement with multiple distributed microphone arrays, which is a non-real-time track and does not have any constraints so that participants could explore any algorithms to obtain high speech quality. Targeting the real video conferencing room application, the challenge database was recorded from real speakers and all recording facilities were located by following the real setup of conferencing room. In this challenge, we open-sourced the list of open source clean speech and noise datasets, simulation scripts, and a baseline system for participants to develop their own system. The final ranking of the challenge will be decided by the subjective evaluation which is performed using Absolute Category Ratings (ACR) to estimate Mean Opinion Score (MOS), speech MOS (S-MOS), and noise MOS (N-MOS). This paper describes the challenge, tasks, datasets, and subjective evaluation. The baseline system which is a complex ratio mask based neural network and its experimental results are also presented.