 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYue Li
GAD-Generative Learning for HD Map-Free Autonomous Driving
May 01, 2024
Deep-learning-based techniques have been widely adopted for autonomous driving software stacks for mass production in recent years, focusing primarily on perception modules, with some work extending this method to prediction modules. However, the downstream planning and control modules are still designed with hefty handcrafted rules, dominated by optimization-based methods such as quadratic programming or model predictive control. This results in a performance bottleneck for autonomous driving systems in that corner cases simply cannot be solved by enumerating hand-crafted rules. We present a deep-learning-based approach that brings prediction, decision, and planning modules together with the attempt to overcome the rule-based methods' deficiency in real-world applications of autonomous driving, especially for urban scenes. The DNN model we proposed is solely trained with 10 hours of human driver data, and it supports all mass-production ADAS features available on the market to date. This method is deployed onto a Jiyue test car with no modification to its factory-ready sensor set and compute platform. the feasibility, usability, and commercial potential are demonstrated in this article.
SemiPL: A Semi-supervised Method for Event Sound Source Localization
Apr 30, 2024In recent years, Event Sound Source Localization has been widely applied in various fields. Recent works typically relying on the contrastive learning framework show impressive performance. However, all work is based on large relatively simple datasets. It's also crucial to understand and analyze human behaviors (actions and interactions of people), voices, and sounds in chaotic events in many applications, e.g., crowd management, and emergency response services. In this paper, we apply the existing model to a more complex dataset, explore the influence of parameters on the model, and propose a semi-supervised improvement method SemiPL. With the increase in data quantity and the influence of label quality, self-supervised learning will be an unstoppable trend. The experiment shows that the parameter adjustment will positively affect the existing model. In particular, SSPL achieved an improvement of 12.2% cIoU and 0.56% AUC in Chaotic World compared to the results provided. The code is available at: https://github.com/ly245422/SSPL
TheaterGen: Character Management with LLM for Consistent Multi-turn Image Generation
Apr 29, 2024Recent advances in diffusion models can generate high-quality and stunning images from text. However, multi-turn image generation, which is of high demand in real-world scenarios, still faces challenges in maintaining semantic consistency between images and texts, as well as contextual consistency of the same subject across multiple interactive turns. To address this issue, we introduce TheaterGen, a training-free framework that integrates large language models (LLMs) and text-to-image (T2I) models to provide the capability of multi-turn image generation. Within this framework, LLMs, acting as a "Screenwriter", engage in multi-turn interaction, generating and managing a standardized prompt book that encompasses prompts and layout designs for each character in the target image. Based on these, Theatergen generate a list of character images and extract guidance information, akin to the "Rehearsal". Subsequently, through incorporating the prompt book and guidance information into the reverse denoising process of T2I diffusion models, Theatergen generate the final image, as conducting the "Final Performance". With the effective management of prompt books and character images, TheaterGen significantly improves semantic and contextual consistency in synthesized images. Furthermore, we introduce a dedicated benchmark, CMIGBench (Consistent Multi-turn Image Generation Benchmark) with 8000 multi-turn instructions. Different from previous multi-turn benchmarks, CMIGBench does not define characters in advance. Both the tasks of story generation and multi-turn editing are included on CMIGBench for comprehensive evaluation. Extensive experimental results show that TheaterGen outperforms state-of-the-art methods significantly. It raises the performance bar of the cutting-edge Mini DALLE 3 model by 21% in average character-character similarity and 19% in average text-image similarity.
HDBN: A Novel Hybrid Dual-branch Network for Robust Skeleton-based Action Recognition
Apr 25, 2024Skeleton-based action recognition has gained considerable traction thanks to its utilization of succinct and robust skeletal representations. Nonetheless, current methodologies often lean towards utilizing a solitary backbone to model skeleton modality, which can be limited by inherent flaws in the network backbone. To address this and fully leverage the complementary characteristics of various network architectures, we propose a novel Hybrid Dual-Branch Network (HDBN) for robust skeleton-based action recognition, which benefits from the graph convolutional network's proficiency in handling graph-structured data and the powerful modeling capabilities of Transformers for global information. In detail, our proposed HDBN is divided into two trunk branches: MixGCN and MixFormer. The two branches utilize GCNs and Transformers to model both 2D and 3D skeletal modalities respectively. Our proposed HDBN emerged as one of the top solutions in the Multi-Modal Video Reasoning and Analyzing Competition (MMVRAC) of 2024 ICME Grand Challenge, achieving accuracies of 47.95% and 75.36% on two benchmarks of the UAV-Human dataset by outperforming most existing methods. Our code will be publicly available at: https://github.com/liujf69/ICMEW2024-Track10.
SFMViT: SlowFast Meet ViT in Chaotic World
Apr 25, 2024The task of spatiotemporal action localization in chaotic scenes is a challenging task toward advanced video understanding. Paving the way with high-quality video feature extraction and enhancing the precision of detector-predicted anchors can effectively improve model performance. To this end, we propose a high-performance dual-stream spatiotemporal feature extraction network SFMViT with an anchor pruning strategy. The backbone of our SFMViT is composed of ViT and SlowFast with prior knowledge of spatiotemporal action localization, which fully utilizes ViT's excellent global feature extraction capabilities and SlowFast's spatiotemporal sequence modeling capabilities. Secondly, we introduce the confidence maximum heap to prune the anchors detected in each frame of the picture to filter out the effective anchors. These designs enable our SFMViT to achieve a mAP of 26.62% in the Chaotic World dataset, far exceeding existing models. Code is available at https://github.com/jfightyr/SlowFast-Meet-ViT.
LLM-Enhanced Causal Discovery in Temporal Domain from Interventional Data
Apr 23, 2024In the field of Artificial Intelligence for Information Technology Operations, causal discovery is pivotal for operation and maintenance of graph construction, facilitating downstream industrial tasks such as root cause analysis. Temporal causal discovery, as an emerging method, aims to identify temporal causal relationships between variables directly from observations by utilizing interventional data. However, existing methods mainly focus on synthetic datasets with heavy reliance on intervention targets and ignore the textual information hidden in real-world systems, failing to conduct causal discovery for real industrial scenarios. To tackle this problem, in this paper we propose to investigate temporal causal discovery in industrial scenarios, which faces two critical challenges: 1) how to discover causal relationships without the interventional targets that are costly to obtain in practice, and 2) how to discover causal relations via leveraging the textual information in systems which can be complex yet abundant in industrial contexts. To address these challenges, we propose the RealTCD framework, which is able to leverage domain knowledge to discover temporal causal relationships without interventional targets. Specifically, we first develop a score-based temporal causal discovery method capable of discovering causal relations for root cause analysis without relying on interventional targets through strategic masking and regularization. Furthermore, by employing Large Language Models (LLMs) to handle texts and integrate domain knowledge, we introduce LLM-guided meta-initialization to extract the meta-knowledge from textual information hidden in systems to boost the quality of discovery. We conduct extensive experiments on simulation and real-world datasets to show the superiority of our proposed RealTCD framework over existing baselines in discovering temporal causal structures.
CyberSecEval 2: A Wide-Ranging Cybersecurity Evaluation Suite for Large Language Models
Apr 19, 2024Large language models (LLMs) introduce new security risks, but there are few comprehensive evaluation suites to measure and reduce these risks. We present BenchmarkName, a novel benchmark to quantify LLM security risks and capabilities. We introduce two new areas for testing: prompt injection and code interpreter abuse. We evaluated multiple state-of-the-art (SOTA) LLMs, including GPT-4, Mistral, Meta Llama 3 70B-Instruct, and Code Llama. Our results show that conditioning away risk of attack remains an unsolved problem; for example, all tested models showed between 26% and 41% successful prompt injection tests. We further introduce the safety-utility tradeoff: conditioning an LLM to reject unsafe prompts can cause the LLM to falsely reject answering benign prompts, which lowers utility. We propose quantifying this tradeoff using False Refusal Rate (FRR). As an illustration, we introduce a novel test set to quantify FRR for cyberattack helpfulness risk. We find many LLMs able to successfully comply with "borderline" benign requests while still rejecting most unsafe requests. Finally, we quantify the utility of LLMs for automating a core cybersecurity task, that of exploiting software vulnerabilities. This is important because the offensive capabilities of LLMs are of intense interest; we quantify this by creating novel test sets for four representative problems. We find that models with coding capabilities perform better than those without, but that further work is needed for LLMs to become proficient at exploit generation. Our code is open source and can be used to evaluate other LLMs.
Event-assisted Low-Light Video Object Segmentation
Apr 02, 2024In the realm of video object segmentation (VOS), the challenge of operating under low-light conditions persists, resulting in notably degraded image quality and compromised accuracy when comparing query and memory frames for similarity computation. Event cameras, characterized by their high dynamic range and ability to capture motion information of objects, offer promise in enhancing object visibility and aiding VOS methods under such low-light conditions. This paper introduces a pioneering framework tailored for low-light VOS, leveraging event camera data to elevate segmentation accuracy. Our approach hinges on two pivotal components: the Adaptive Cross-Modal Fusion (ACMF) module, aimed at extracting pertinent features while fusing image and event modalities to mitigate noise interference, and the Event-Guided Memory Matching (EGMM) module, designed to rectify the issue of inaccurate matching prevalent in low-light settings. Additionally, we present the creation of a synthetic LLE-DAVIS dataset and the curation of a real-world LLE-VOS dataset, encompassing frames and events. Experimental evaluations corroborate the efficacy of our method across both datasets, affirming its effectiveness in low-light scenarios.
Single-Channel Robot Ego-Speech Filtering during Human-Robot Interaction
Mar 05, 2024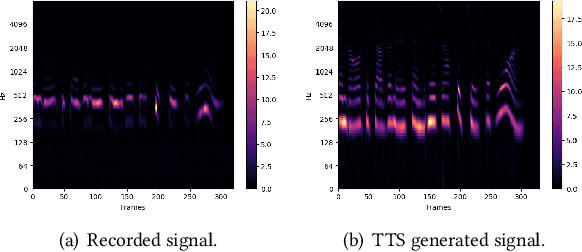
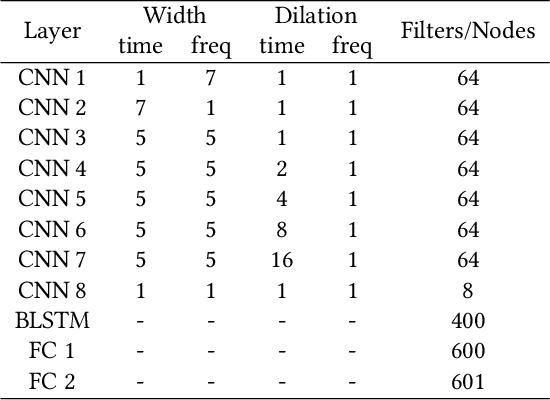
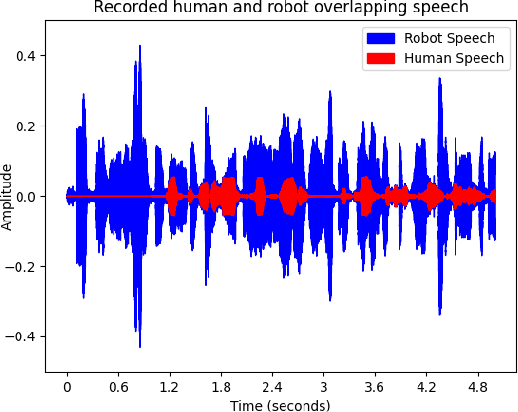

In this paper, we study how well human speech can automatically be filtered when this overlaps with the voice and fan noise of a social robot, Pepper. We ultimately aim for an HRI scenario where the microphone can remain open when the robot is speaking, enabling a more natural turn-taking scheme where the human can interrupt the robot. To respond appropriately, the robot would need to understand what the interlocutor said in the overlapping part of the speech, which can be accomplished by target speech extraction (TSE). To investigate how well TSE can be accomplished in the context of the popular social robot Pepper, we set out to manufacture a datase composed of a mixture of recorded speech of Pepper itself, its fan noise (which is close to the microphones), and human speech as recorded by the Pepper microphone, in a room with low reverberation and high reverberation. Comparing a signal processing approach, with and without post-filtering, and a convolutional recurrent neural network (CRNN) approach to a state-of-the-art speaker identification-based TSE model, we found that the signal processing approach without post-filtering yielded the best performance in terms of Word Error Rate on the overlapping speech signals with low reverberation, while the CRNN approach is more robust for reverberation. These results show that estimating the human voice in overlapping speech with a robot is possible in real-life application, provided that the room reverberation is low and the human speech has a high volume or high pitch.
A Neural-network Enhanced Video Coding Framework beyond ECM
Feb 21, 2024In this paper, a hybrid video compression framework is proposed that serves as a demonstrative showcase of deep learning-based approaches extending beyond the confines of traditional coding methodologies. The proposed hybrid framework is founded upon the Enhanced Compression Model (ECM), which is a further enhancement of the Versatile Video Coding (VVC) standard. We have augmented the latest ECM reference software with well-designed coding techniques, including block partitioning, deep learning-based loop filter, and the activation of block importance mapping (BIM) which was integrated but previously inactive within ECM, further enhancing coding performance. Compared with ECM-10.0, our method achieves 6.26, 13.33, and 12.33 BD-rate savings for the Y, U, and V components under random access (RA) configuration, respectively.