 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuhao Cheng
TheaterGen: Character Management with LLM for Consistent Multi-turn Image Generation
Apr 29, 2024
Recent advances in diffusion models can generate high-quality and stunning images from text. However, multi-turn image generation, which is of high demand in real-world scenarios, still faces challenges in maintaining semantic consistency between images and texts, as well as contextual consistency of the same subject across multiple interactive turns. To address this issue, we introduce TheaterGen, a training-free framework that integrates large language models (LLMs) and text-to-image (T2I) models to provide the capability of multi-turn image generation. Within this framework, LLMs, acting as a "Screenwriter", engage in multi-turn interaction, generating and managing a standardized prompt book that encompasses prompts and layout designs for each character in the target image. Based on these, Theatergen generate a list of character images and extract guidance information, akin to the "Rehearsal". Subsequently, through incorporating the prompt book and guidance information into the reverse denoising process of T2I diffusion models, Theatergen generate the final image, as conducting the "Final Performance". With the effective management of prompt books and character images, TheaterGen significantly improves semantic and contextual consistency in synthesized images. Furthermore, we introduce a dedicated benchmark, CMIGBench (Consistent Multi-turn Image Generation Benchmark) with 8000 multi-turn instructions. Different from previous multi-turn benchmarks, CMIGBench does not define characters in advance. Both the tasks of story generation and multi-turn editing are included on CMIGBench for comprehensive evaluation. Extensive experimental results show that TheaterGen outperforms state-of-the-art methods significantly. It raises the performance bar of the cutting-edge Mini DALLE 3 model by 21% in average character-character similarity and 19% in average text-image similarity.
ConsistentID: Portrait Generation with Multimodal Fine-Grained Identity Preserving
Apr 25, 2024Diffusion-based technologies have made significant strides, particularly in personalized and customized facialgeneration. However, existing methods face challenges in achieving high-fidelity and detailed identity (ID)consistency, primarily due to insufficient fine-grained control over facial areas and the lack of a comprehensive strategy for ID preservation by fully considering intricate facial details and the overall face. To address these limitations, we introduce ConsistentID, an innovative method crafted for diverseidentity-preserving portrait generation under fine-grained multimodal facial prompts, utilizing only a single reference image. ConsistentID comprises two key components: a multimodal facial prompt generator that combines facial features, corresponding facial descriptions and the overall facial context to enhance precision in facial details, and an ID-preservation network optimized through the facial attention localization strategy, aimed at preserving ID consistency in facial regions. Together, these components significantly enhance the accuracy of ID preservation by introducing fine-grained multimodal ID information from facial regions. To facilitate training of ConsistentID, we present a fine-grained portrait dataset, FGID, with over 500,000 facial images, offering greater diversity and comprehensiveness than existing public facial datasets. % such as LAION-Face, CelebA, FFHQ, and SFHQ. Experimental results substantiate that our ConsistentID achieves exceptional precision and diversity in personalized facial generation, surpassing existing methods in the MyStyle dataset. Furthermore, while ConsistentID introduces more multimodal ID information, it maintains a fast inference speed during generation.
Monocular Identity-Conditioned Facial Reflectance Reconstruction
Mar 30, 2024Recent 3D face reconstruction methods have made remarkable advancements, yet there remain huge challenges in monocular high-quality facial reflectance reconstruction. Existing methods rely on a large amount of light-stage captured data to learn facial reflectance models. However, the lack of subject diversity poses challenges in achieving good generalization and widespread applicability. In this paper, we learn the reflectance prior in image space rather than UV space and present a framework named ID2Reflectance. Our framework can directly estimate the reflectance maps of a single image while using limited reflectance data for training. Our key insight is that reflectance data shares facial structures with RGB faces, which enables obtaining expressive facial prior from inexpensive RGB data thus reducing the dependency on reflectance data. We first learn a high-quality prior for facial reflectance. Specifically, we pretrain multi-domain facial feature codebooks and design a codebook fusion method to align the reflectance and RGB domains. Then, we propose an identity-conditioned swapping module that injects facial identity from the target image into the pre-trained autoencoder to modify the identity of the source reflectance image. Finally, we stitch multi-view swapped reflectance images to obtain renderable assets. Extensive experiments demonstrate that our method exhibits excellent generalization capability and achieves state-of-the-art facial reflectance reconstruction results for in-the-wild faces. Our project page is https://xingyuren.github.io/id2reflectance/.
LSCD: A Large-Scale Screen Content Dataset for Video Compression
Aug 18, 2023

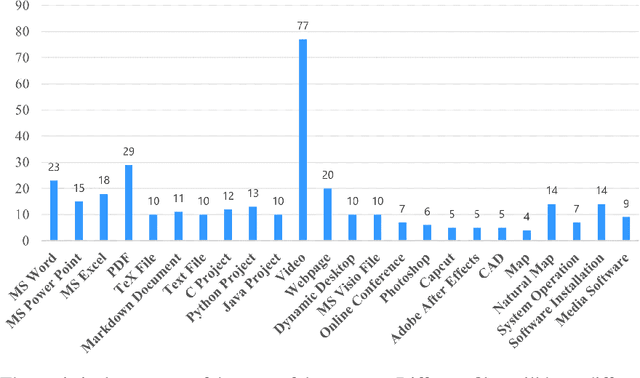
Multimedia compression allows us to watch videos, see pictures and hear sounds within a limited bandwidth, which helps the flourish of the internet. During the past decades, multimedia compression has achieved great success using hand-craft features and systems. With the development of artificial intelligence and video compression, there emerges a lot of research work related to using the neural network on the video compression task to get rid of the complicated system. Not only producing the advanced algorithms, but researchers also spread the compression to different content, such as User Generated Content(UGC). With the rapid development of mobile devices, screen content videos become an important part of multimedia data. In contrast, we find community lacks a large-scale dataset for screen content video compression, which impedes the fast development of the corresponding learning-based algorithms. In order to fulfill this blank and accelerate the research of this special type of videos, we propose the Large-scale Screen Content Dataset(LSCD), which contains 714 source sequences. Meanwhile, we provide the analysis of the proposed dataset to show some features of screen content videos, which will help researchers have a better understanding of how to explore new algorithms. Besides collecting and post-processing the data to organize the dataset, we also provide a benchmark containing the performance of both traditional codec and learning-based methods.
GANHead: Towards Generative Animatable Neural Head Avatars
Apr 08, 2023
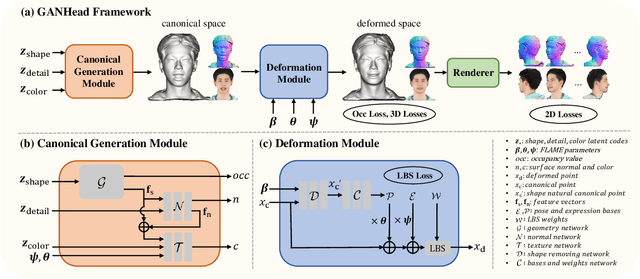
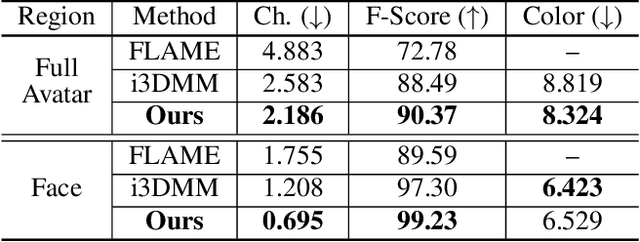

To bring digital avatars into people's lives, it is highly demanded to efficiently generate complete, realistic, and animatable head avatars. This task is challenging, and it is difficult for existing methods to satisfy all the requirements at once. To achieve these goals, we propose GANHead (Generative Animatable Neural Head Avatar), a novel generative head model that takes advantages of both the fine-grained control over the explicit expression parameters and the realistic rendering results of implicit representations. Specifically, GANHead represents coarse geometry, fine-gained details and texture via three networks in canonical space to obtain the ability to generate complete and realistic head avatars. To achieve flexible animation, we define the deformation filed by standard linear blend skinning (LBS), with the learned continuous pose and expression bases and LBS weights. This allows the avatars to be directly animated by FLAME parameters and generalize well to unseen poses and expressions. Compared to state-of-the-art (SOTA) methods, GANHead achieves superior performance on head avatar generation and raw scan fitting.
Head3D: Complete 3D Head Generation via Tri-plane Feature Distillation
Mar 28, 2023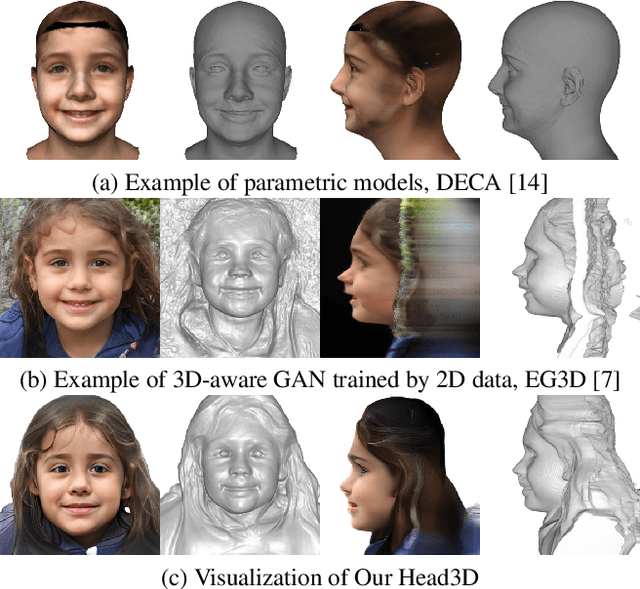

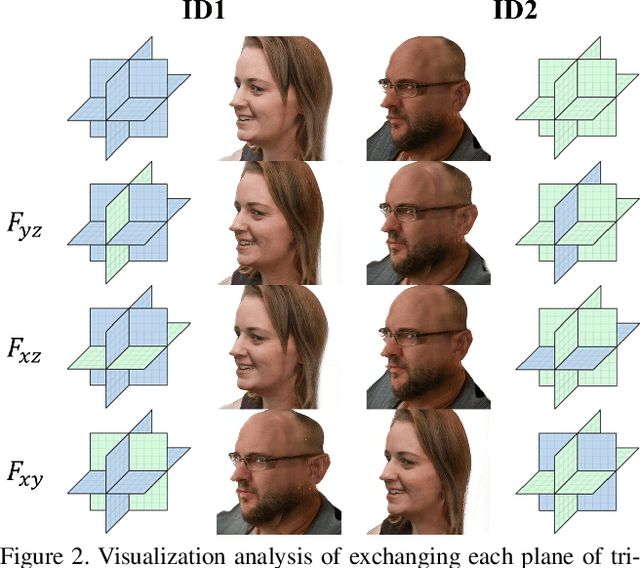

Head generation with diverse identities is an important task in computer vision and computer graphics, widely used in multimedia applications. However, current full head generation methods require a large number of 3D scans or multi-view images to train the model, resulting in expensive data acquisition cost. To address this issue, we propose Head3D, a method to generate full 3D heads with limited multi-view images. Specifically, our approach first extracts facial priors represented by tri-planes learned in EG3D, a 3D-aware generative model, and then proposes feature distillation to deliver the 3D frontal faces into complete heads without compromising head integrity. To mitigate the domain gap between the face and head models, we present dual-discriminators to guide the frontal and back head generation, respectively. Our model achieves cost-efficient and diverse complete head generation with photo-realistic renderings and high-quality geometry representations. Extensive experiments demonstrate the effectiveness of our proposed Head3D, both qualitatively and quantitatively.
Simple and Robust Loss Design for Multi-Label Learning with Missing Labels
Dec 27, 2021
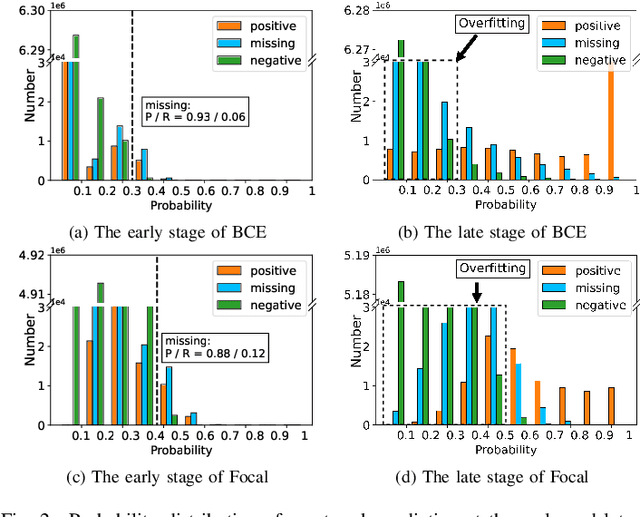
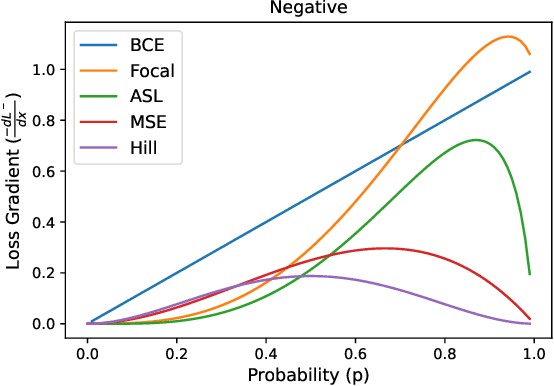
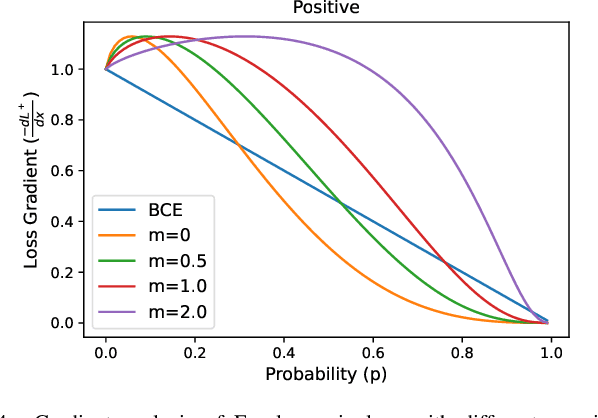
Multi-label learning in the presence of missing labels (MLML) is a challenging problem. Existing methods mainly focus on the design of network structures or training schemes, which increase the complexity of implementation. This work seeks to fulfill the potential of loss function in MLML without increasing the procedure and complexity. Toward this end, we propose two simple yet effective methods via robust loss design based on an observation that a model can identify missing labels during training with a high precision. The first is a novel robust loss for negatives, namely the Hill loss, which re-weights negatives in the shape of a hill to alleviate the effect of false negatives. The second is a self-paced loss correction (SPLC) method, which uses a loss derived from the maximum likelihood criterion under an approximate distribution of missing labels. Comprehensive experiments on a vast range of multi-label image classification datasets demonstrate that our methods can remarkably boost the performance of MLML and achieve new state-of-the-art loss functions in MLML.
Semantic Role Labeling with Associated Memory Network
Aug 05, 2019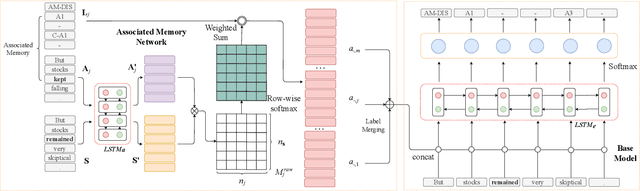
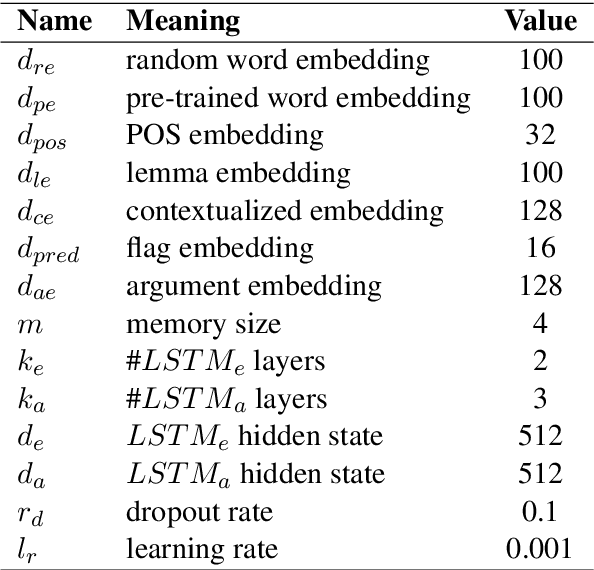
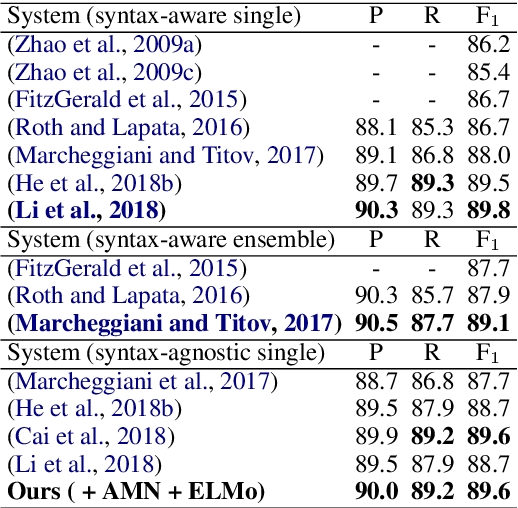
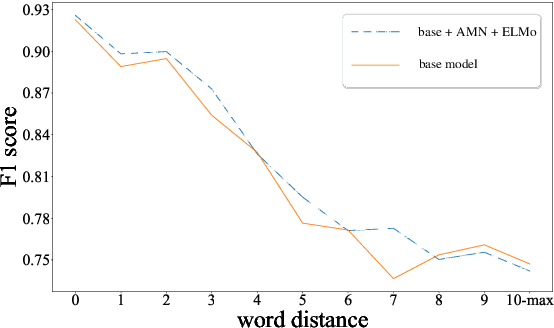
Semantic role labeling (SRL) is a task to recognize all the predicate-argument pairs of a sentence, which has been in a performance improvement bottleneck after a series of latest works were presented. This paper proposes a novel syntax-agnostic SRL model enhanced by the proposed associated memory network (AMN), which makes use of inter-sentence attention of label-known associated sentences as a kind of memory to further enhance dependency-based SRL. In detail, we use sentences and their labels from train dataset as an associated memory cue to help label the target sentence. Furthermore, we compare several associated sentences selecting strategies and label merging methods in AMN to find and utilize the label of associated sentences while attending them. By leveraging the attentive memory from known training data, Our full model reaches state-of-the-art on CoNLL-2009 benchmark datasets for syntax-agnostic setting, showing a new effective research line of SRL enhancement other than exploiting external resources such as well pre-trained language models.