 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYichao Yan
IPAD: Industrial Process Anomaly Detection Dataset
Apr 23, 2024
Video anomaly detection (VAD) is a challenging task aiming to recognize anomalies in video frames, and existing large-scale VAD researches primarily focus on road traffic and human activity scenes. In industrial scenes, there are often a variety of unpredictable anomalies, and the VAD method can play a significant role in these scenarios. However, there is a lack of applicable datasets and methods specifically tailored for industrial production scenarios due to concerns regarding privacy and security. To bridge this gap, we propose a new dataset, IPAD, specifically designed for VAD in industrial scenarios. The industrial processes in our dataset are chosen through on-site factory research and discussions with engineers. This dataset covers 16 different industrial devices and contains over 6 hours of both synthetic and real-world video footage. Moreover, we annotate the key feature of the industrial process, ie, periodicity. Based on the proposed dataset, we introduce a period memory module and a sliding window inspection mechanism to effectively investigate the periodic information in a basic reconstruction model. Our framework leverages LoRA adapter to explore the effective migration of pretrained models, which are initially trained using synthetic data, into real-world scenarios. Our proposed dataset and method will fill the gap in the field of industrial video anomaly detection and drive the process of video understanding tasks as well as smart factory deployment.
Infusion: Preventing Customized Text-to-Image Diffusion from Overfitting
Apr 22, 2024Text-to-image (T2I) customization aims to create images that embody specific visual concepts delineated in textual descriptions. However, existing works still face a main challenge, concept overfitting. To tackle this challenge, we first analyze overfitting, categorizing it into concept-agnostic overfitting, which undermines non-customized concept knowledge, and concept-specific overfitting, which is confined to customize on limited modalities, i.e, backgrounds, layouts, styles. To evaluate the overfitting degree, we further introduce two metrics, i.e, Latent Fisher divergence and Wasserstein metric to measure the distribution changes of non-customized and customized concept respectively. Drawing from the analysis, we propose Infusion, a T2I customization method that enables the learning of target concepts to avoid being constrained by limited training modalities, while preserving non-customized knowledge. Remarkably, Infusion achieves this feat with remarkable efficiency, requiring a mere 11KB of trained parameters. Extensive experiments also demonstrate that our approach outperforms state-of-the-art methods in both single and multi-concept customized generation.
Rethinking Clothes Changing Person ReID: Conflicts, Synthesis, and Optimization
Apr 19, 2024Clothes-changing person re-identification (CC-ReID) aims to retrieve images of the same person wearing different outfits. Mainstream researches focus on designing advanced model structures and strategies to capture identity information independent of clothing. However, the same-clothes discrimination as the standard ReID learning objective in CC-ReID is persistently ignored in previous researches. In this study, we dive into the relationship between standard and clothes-changing~(CC) learning objectives, and bring the inner conflicts between these two objectives to the fore. We try to magnify the proportion of CC training pairs by supplementing high-fidelity clothes-varying synthesis, produced by our proposed Clothes-Changing Diffusion model. By incorporating the synthetic images into CC-ReID model training, we observe a significant improvement under CC protocol. However, such improvement sacrifices the performance under the standard protocol, caused by the inner conflict between standard and CC. For conflict mitigation, we decouple these objectives and re-formulate CC-ReID learning as a multi-objective optimization (MOO) problem. By effectively regularizing the gradient curvature across multiple objectives and introducing preference restrictions, our MOO solution surpasses the single-task training paradigm. Our framework is model-agnostic, and demonstrates superior performance under both CC and standard ReID protocols.
Monocular Identity-Conditioned Facial Reflectance Reconstruction
Mar 30, 2024Recent 3D face reconstruction methods have made remarkable advancements, yet there remain huge challenges in monocular high-quality facial reflectance reconstruction. Existing methods rely on a large amount of light-stage captured data to learn facial reflectance models. However, the lack of subject diversity poses challenges in achieving good generalization and widespread applicability. In this paper, we learn the reflectance prior in image space rather than UV space and present a framework named ID2Reflectance. Our framework can directly estimate the reflectance maps of a single image while using limited reflectance data for training. Our key insight is that reflectance data shares facial structures with RGB faces, which enables obtaining expressive facial prior from inexpensive RGB data thus reducing the dependency on reflectance data. We first learn a high-quality prior for facial reflectance. Specifically, we pretrain multi-domain facial feature codebooks and design a codebook fusion method to align the reflectance and RGB domains. Then, we propose an identity-conditioned swapping module that injects facial identity from the target image into the pre-trained autoencoder to modify the identity of the source reflectance image. Finally, we stitch multi-view swapped reflectance images to obtain renderable assets. Extensive experiments demonstrate that our method exhibits excellent generalization capability and achieves state-of-the-art facial reflectance reconstruction results for in-the-wild faces. Our project page is https://xingyuren.github.io/id2reflectance/.
ReGenNet: Towards Human Action-Reaction Synthesis
Mar 18, 2024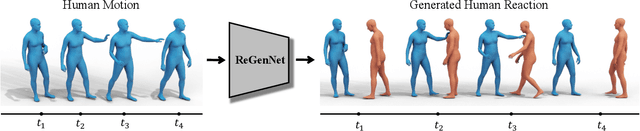
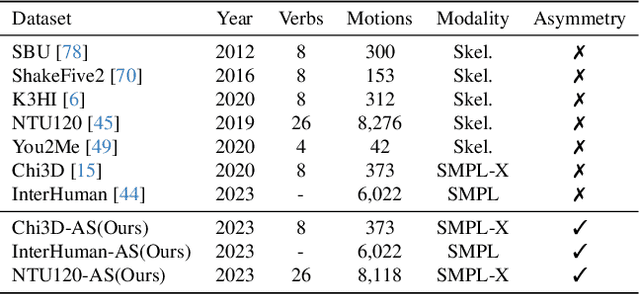

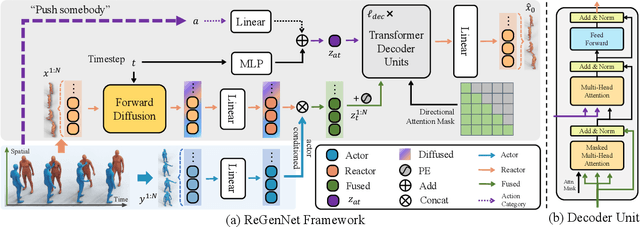
Humans constantly interact with their surrounding environments. Current human-centric generative models mainly focus on synthesizing humans plausibly interacting with static scenes and objects, while the dynamic human action-reaction synthesis for ubiquitous causal human-human interactions is less explored. Human-human interactions can be regarded as asymmetric with actors and reactors in atomic interaction periods. In this paper, we comprehensively analyze the asymmetric, dynamic, synchronous, and detailed nature of human-human interactions and propose the first multi-setting human action-reaction synthesis benchmark to generate human reactions conditioned on given human actions. To begin with, we propose to annotate the actor-reactor order of the interaction sequences for the NTU120, InterHuman, and Chi3D datasets. Based on them, a diffusion-based generative model with a Transformer decoder architecture called ReGenNet together with an explicit distance-based interaction loss is proposed to predict human reactions in an online manner, where the future states of actors are unavailable to reactors. Quantitative and qualitative results show that our method can generate instant and plausible human reactions compared to the baselines, and can generalize to unseen actor motions and viewpoint changes.
A Comparative Study of Perceptual Quality Metrics for Audio-driven Talking Head Videos
Mar 11, 2024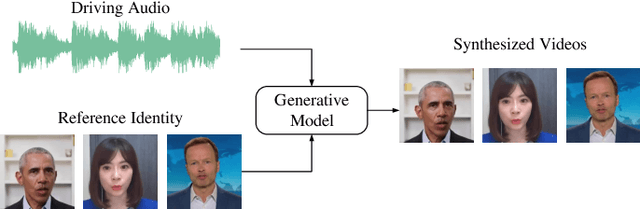
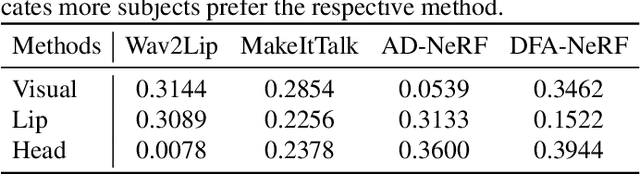

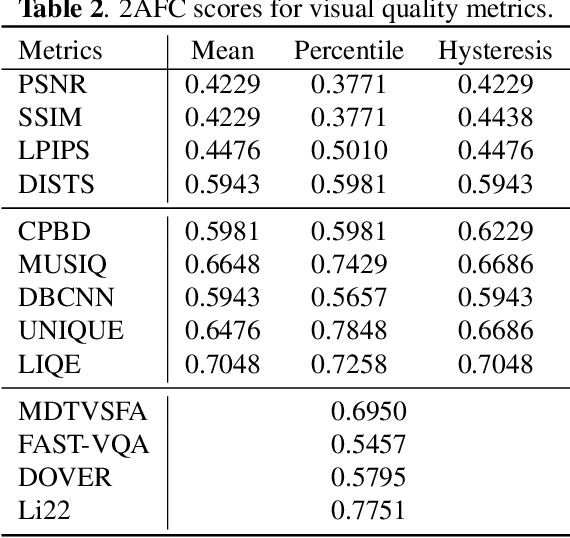
The rapid advancement of Artificial Intelligence Generated Content (AIGC) technology has propelled audio-driven talking head generation, gaining considerable research attention for practical applications. However, performance evaluation research lags behind the development of talking head generation techniques. Existing literature relies on heuristic quantitative metrics without human validation, hindering accurate progress assessment. To address this gap, we collect talking head videos generated from four generative methods and conduct controlled psychophysical experiments on visual quality, lip-audio synchronization, and head movement naturalness. Our experiments validate consistency between model predictions and human annotations, identifying metrics that align better with human opinions than widely-used measures. We believe our work will facilitate performance evaluation and model development, providing insights into AIGC in a broader context. Code and data will be made available at https://github.com/zwx8981/ADTH-QA.
Inter-X: Towards Versatile Human-Human Interaction Analysis
Dec 26, 2023The analysis of the ubiquitous human-human interactions is pivotal for understanding humans as social beings. Existing human-human interaction datasets typically suffer from inaccurate body motions, lack of hand gestures and fine-grained textual descriptions. To better perceive and generate human-human interactions, we propose Inter-X, a currently largest human-human interaction dataset with accurate body movements and diverse interaction patterns, together with detailed hand gestures. The dataset includes ~11K interaction sequences and more than 8.1M frames. We also equip Inter-X with versatile annotations of more than 34K fine-grained human part-level textual descriptions, semantic interaction categories, interaction order, and the relationship and personality of the subjects. Based on the elaborate annotations, we propose a unified benchmark composed of 4 categories of downstream tasks from both the perceptual and generative directions. Extensive experiments and comprehensive analysis show that Inter-X serves as a testbed for promoting the development of versatile human-human interaction analysis. Our dataset and benchmark will be publicly available for research purposes.
SingingHead: A Large-scale 4D Dataset for Singing Head Animation
Dec 08, 2023Singing, as a common facial movement second only to talking, can be regarded as a universal language across ethnicities and cultures, plays an important role in emotional communication, art, and entertainment. However, it is often overlooked in the field of audio-driven facial animation due to the lack of singing head datasets and the domain gap between singing and talking in rhythm and amplitude. To this end, we collect a high-quality large-scale singing head dataset, SingingHead, which consists of more than 27 hours of synchronized singing video, 3D facial motion, singing audio, and background music from 76 individuals and 8 types of music. Along with the SingingHead dataset, we argue that 3D and 2D facial animation tasks can be solved together, and propose a unified singing facial animation framework named UniSinger to achieve both singing audio-driven 3D singing head animation and 2D singing portrait video synthesis. Extensive comparative experiments with both SOTA 3D facial animation and 2D portrait animation methods demonstrate the necessity of singing-specific datasets in singing head animation tasks and the promising performance of our unified facial animation framework.
EvaSurf: Efficient View-Aware Implicit Textured Surface Reconstruction on Mobile Devices
Nov 18, 2023Reconstructing real-world 3D objects has numerous applications in computer vision, such as virtual reality, video games, and animations. Ideally, 3D reconstruction methods should generate high-fidelity results with 3D consistency in real-time. Traditional methods match pixels between images using photo-consistency constraints or learned features, while differentiable rendering methods like Neural Radiance Fields (NeRF) use differentiable volume rendering or surface-based representation to generate high-fidelity scenes. However, these methods require excessive runtime for rendering, making them impractical for daily applications. To address these challenges, we present $\textbf{EvaSurf}$, an $\textbf{E}$fficient $\textbf{V}$iew-$\textbf{A}$ware implicit textured $\textbf{Surf}$ace reconstruction method on mobile devices. In our method, we first employ an efficient surface-based model with a multi-view supervision module to ensure accurate mesh reconstruction. To enable high-fidelity rendering, we learn an implicit texture embedded with a set of Gaussian lobes to capture view-dependent information. Furthermore, with the explicit geometry and the implicit texture, we can employ a lightweight neural shader to reduce the expense of computation and further support real-time rendering on common mobile devices. Extensive experiments demonstrate that our method can reconstruct high-quality appearance and accurate mesh on both synthetic and real-world datasets. Moreover, our method can be trained in just 1-2 hours using a single GPU and run on mobile devices at over 40 FPS (Frames Per Second), with a final package required for rendering taking up only 40-50 MB.
Generalizable Person Search on Open-world User-Generated Video Content
Oct 16, 2023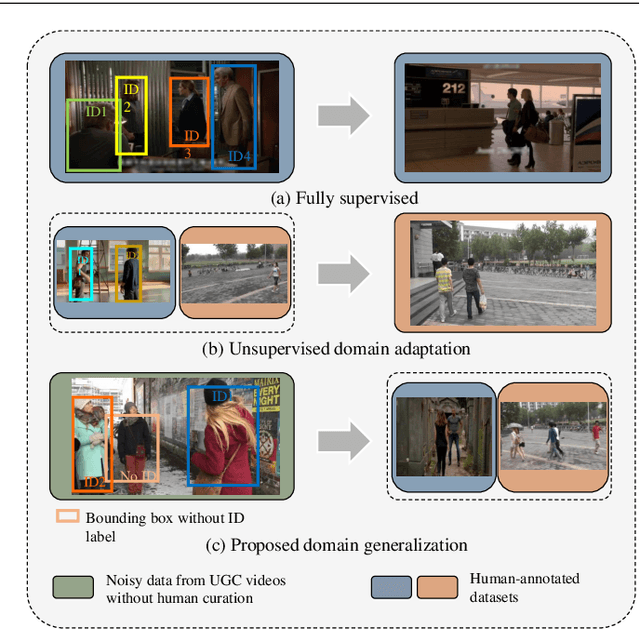
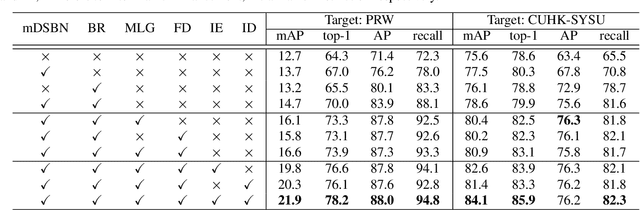
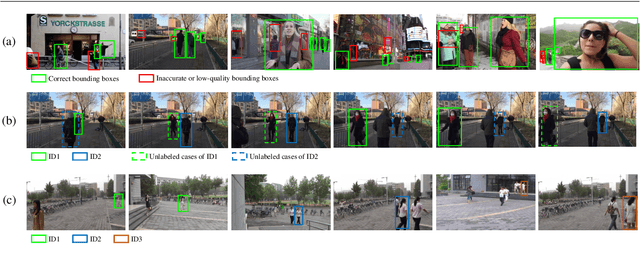
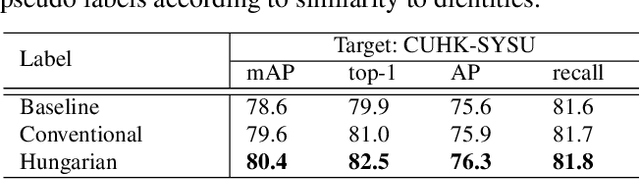
Person search is a challenging task that involves detecting and retrieving individuals from a large set of un-cropped scene images. Existing person search applications are mostly trained and deployed in the same-origin scenarios. However, collecting and annotating training samples for each scene is often difficult due to the limitation of resources and the labor cost. Moreover, large-scale intra-domain data for training are generally not legally available for common developers, due to the regulation of privacy and public security. Leveraging easily accessible large-scale User Generated Video Contents (\emph{i.e.} UGC videos) to train person search models can fit the open-world distribution, but still suffering a performance gap from the domain difference to surveillance scenes. In this work, we explore enhancing the out-of-domain generalization capabilities of person search models, and propose a generalizable framework on both feature-level and data-level generalization to facilitate downstream tasks in arbitrary scenarios. Specifically, we focus on learning domain-invariant representations for both detection and ReID by introducing a multi-task prototype-based domain-specific batch normalization, and a channel-wise ID-relevant feature decorrelation strategy. We also identify and address typical sources of noise in open-world training frames, including inaccurate bounding boxes, the omission of identity labels, and the absence of cross-camera data. Our framework achieves promising performance on two challenging person search benchmarks without using any human annotation or samples from the target domain.