 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQi Zhu
Parameter-Efficient Tuning Large Language Models for Graph Representation Learning
Apr 28, 2024
Text-rich graphs, which exhibit rich textual information on nodes and edges, are prevalent across a wide range of real-world business applications. Large Language Models (LLMs) have demonstrated remarkable abilities in understanding text, which also introduced the potential for more expressive modeling in text-rich graphs. Despite these capabilities, efficiently applying LLMs to representation learning on graphs presents significant challenges. Recently, parameter-efficient fine-tuning methods for LLMs have enabled efficient new task generalization with minimal time and memory consumption. Inspired by this, we introduce Graph-aware Parameter-Efficient Fine-Tuning - GPEFT, a novel approach for efficient graph representation learning with LLMs on text-rich graphs. Specifically, we utilize a graph neural network (GNN) to encode structural information from neighboring nodes into a graph prompt. This prompt is then inserted at the beginning of the text sequence. To improve the quality of graph prompts, we pre-trained the GNN to assist the frozen LLM in predicting the next token in the node text. Compared with existing joint GNN and LMs, our method directly generate the node embeddings from large language models with an affordable fine-tuning cost. We validate our approach through comprehensive experiments conducted on 8 different text-rich graphs, observing an average improvement of 2% in hit@1 and Mean Reciprocal Rank (MRR) in link prediction evaluations. Our results demonstrate the efficacy and efficiency of our model, showing that it can be smoothly integrated with various large language models, including OPT, LLaMA and Falcon.
Infusion: Preventing Customized Text-to-Image Diffusion from Overfitting
Apr 22, 2024Text-to-image (T2I) customization aims to create images that embody specific visual concepts delineated in textual descriptions. However, existing works still face a main challenge, concept overfitting. To tackle this challenge, we first analyze overfitting, categorizing it into concept-agnostic overfitting, which undermines non-customized concept knowledge, and concept-specific overfitting, which is confined to customize on limited modalities, i.e, backgrounds, layouts, styles. To evaluate the overfitting degree, we further introduce two metrics, i.e, Latent Fisher divergence and Wasserstein metric to measure the distribution changes of non-customized and customized concept respectively. Drawing from the analysis, we propose Infusion, a T2I customization method that enables the learning of target concepts to avoid being constrained by limited training modalities, while preserving non-customized knowledge. Remarkably, Infusion achieves this feat with remarkable efficiency, requiring a mere 11KB of trained parameters. Extensive experiments also demonstrate that our approach outperforms state-of-the-art methods in both single and multi-concept customized generation.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
Graph Neural Network-based Multi-agent Reinforcement Learning for Resilient Distributed Coordination of Multi-Robot Systems
Mar 19, 2024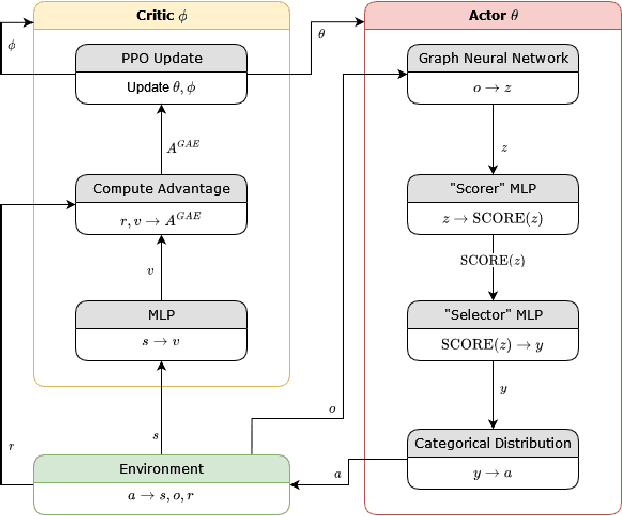

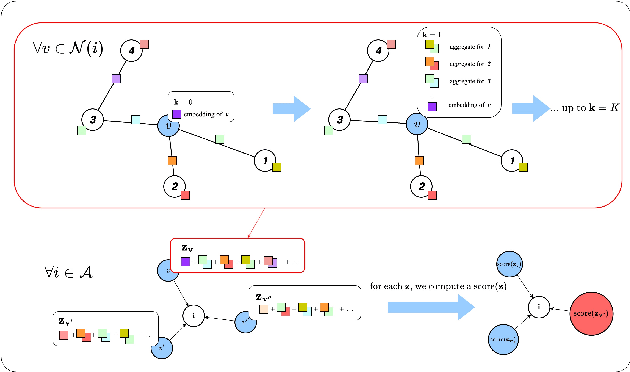
Existing multi-agent coordination techniques are often fragile and vulnerable to anomalies such as agent attrition and communication disturbances, which are quite common in the real-world deployment of systems like field robotics. To better prepare these systems for the real world, we present a graph neural network (GNN)-based multi-agent reinforcement learning (MARL) method for resilient distributed coordination of a multi-robot system. Our method, Multi-Agent Graph Embedding-based Coordination (MAGEC), is trained using multi-agent proximal policy optimization (PPO) and enables distributed coordination around global objectives under agent attrition, partial observability, and limited or disturbed communications. We use a multi-robot patrolling scenario to demonstrate our MAGEC method in a ROS 2-based simulator and then compare its performance with prior coordination approaches. Results demonstrate that MAGEC outperforms existing methods in several experiments involving agent attrition and communication disturbance, and provides competitive results in scenarios without such anomalies.
Semantic Feature Learning for Universal Unsupervised Cross-Domain Retrieval
Mar 08, 2024


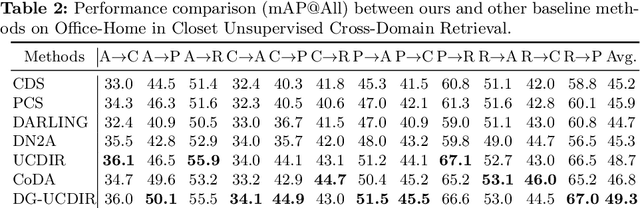
Cross-domain retrieval (CDR), as a crucial tool for numerous technologies, is finding increasingly broad applications. However, existing efforts face several major issues, with the most critical being the need for accurate supervision, which often demands costly resources and efforts. Cutting-edge studies focus on achieving unsupervised CDR but typically assume that the category spaces across domains are identical, an assumption that is often unrealistic in real-world scenarios. This is because only through dedicated and comprehensive analysis can the category spaces of different domains be confirmed as identical, which contradicts the premise of unsupervised scenarios. Therefore, in this work, we introduce the problem of Universal Unsupervised Cross-Domain Retrieval (U^2CDR) for the first time and design a two-stage semantic feature learning framework to address it. In the first stage, a cross-domain unified prototypical structure is established under the guidance of an instance-prototype-mixed contrastive loss and a semantic-enhanced loss, to counteract category space differences. In the second stage, through a modified adversarial training mechanism, we ensure minimal changes for the established prototypical structure during domain alignment, enabling more accurate nearest-neighbor searching. Extensive experiments across multiple datasets and scenarios, including closet, partial, and open-set CDR, demonstrate that our approach significantly outperforms existing state-of-the-art CDR works and some potentially effective studies from other topics in solving U^2CDR challenges.
Role Prompting Guided Domain Adaptation with General Capability Preserve for Large Language Models
Mar 05, 2024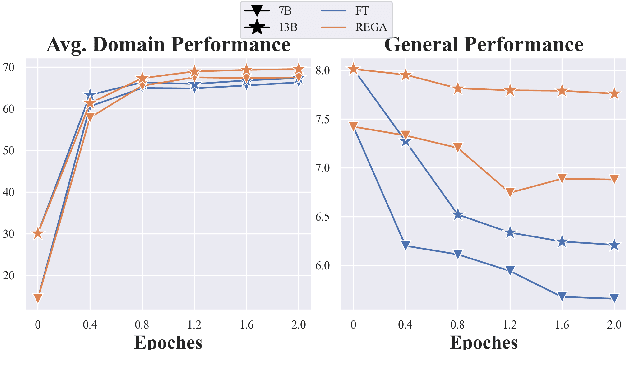

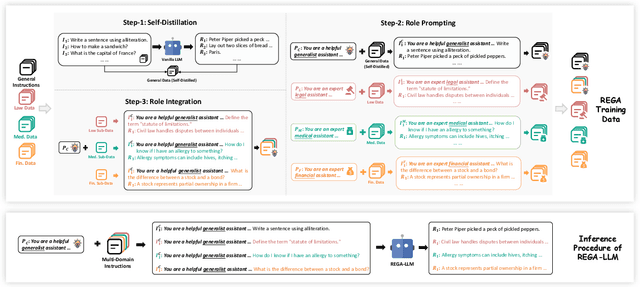
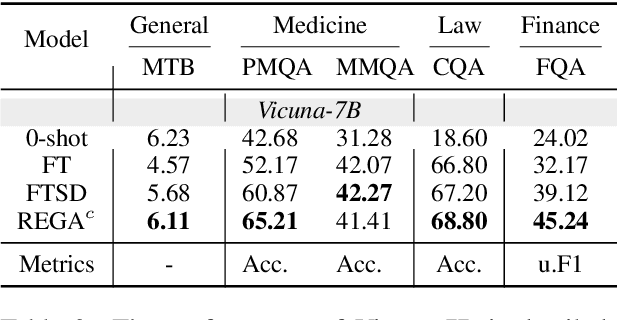
The growing interest in Large Language Models (LLMs) for specialized applications has revealed a significant challenge: when tailored to specific domains, LLMs tend to experience catastrophic forgetting, compromising their general capabilities and leading to a suboptimal user experience. Additionally, crafting a versatile model for multiple domains simultaneously often results in a decline in overall performance due to confusion between domains. In response to these issues, we present the RolE Prompting Guided Multi-Domain Adaptation (REGA) strategy. This novel approach effectively manages multi-domain LLM adaptation through three key components: 1) Self-Distillation constructs and replays general-domain exemplars to alleviate catastrophic forgetting. 2) Role Prompting assigns a central prompt to the general domain and a unique role prompt to each specific domain to minimize inter-domain confusion during training. 3) Role Integration reuses and integrates a small portion of domain-specific data to the general-domain data, which are trained under the guidance of the central prompt. The central prompt is used for a streamlined inference process, removing the necessity to switch prompts for different domains. Empirical results demonstrate that REGA effectively alleviates catastrophic forgetting and inter-domain confusion. This leads to improved domain-specific performance compared to standard fine-tuned models, while still preserving robust general capabilities.
Towards a Digital Twin Framework in Additive Manufacturing: Machine Learning and Bayesian Optimization for Time Series Process Optimization
Feb 27, 2024Laser-directed-energy deposition (DED) offers advantages in additive manufacturing (AM) for creating intricate geometries and material grading. Yet, challenges like material inconsistency and part variability remain, mainly due to its layer-wise fabrication. A key issue is heat accumulation during DED, which affects the material microstructure and properties. While closed-loop control methods for heat management are common in DED research, few integrate real-time monitoring, physics-based modeling, and control in a unified framework. Our work presents a digital twin (DT) framework for real-time predictive control of DED process parameters to meet specific design objectives. We develop a surrogate model using Long Short-Term Memory (LSTM)-based machine learning with Bayesian Inference to predict temperatures in DED parts. This model predicts future temperature states in real time. We also introduce Bayesian Optimization (BO) for Time Series Process Optimization (BOTSPO), based on traditional BO but featuring a unique time series process profile generator with reduced dimensions. BOTSPO dynamically optimizes processes, identifying optimal laser power profiles to attain desired mechanical properties. The established process trajectory guides online optimizations, aiming to enhance performance. This paper outlines the digital twin framework's components, promoting its integration into a comprehensive system for AM.
Can GNN be Good Adapter for LLMs?
Feb 20, 2024Recently, large language models (LLMs) have demonstrated superior capabilities in understanding and zero-shot learning on textual data, promising significant advances for many text-related domains. In the graph domain, various real-world scenarios also involve textual data, where tasks and node features can be described by text. These text-attributed graphs (TAGs) have broad applications in social media, recommendation systems, etc. Thus, this paper explores how to utilize LLMs to model TAGs. Previous methods for TAG modeling are based on million-scale LMs. When scaled up to billion-scale LLMs, they face huge challenges in computational costs. Additionally, they also ignore the zero-shot inference capabilities of LLMs. Therefore, we propose GraphAdapter, which uses a graph neural network (GNN) as an efficient adapter in collaboration with LLMs to tackle TAGs. In terms of efficiency, the GNN adapter introduces only a few trainable parameters and can be trained with low computation costs. The entire framework is trained using auto-regression on node text (next token prediction). Once trained, GraphAdapter can be seamlessly fine-tuned with task-specific prompts for various downstream tasks. Through extensive experiments across multiple real-world TAGs, GraphAdapter based on Llama 2 gains an average improvement of approximately 5\% in terms of node classification. Furthermore, GraphAdapter can also adapt to other language models, including RoBERTa, GPT-2. The promising results demonstrate that GNNs can serve as effective adapters for LLMs in TAG modeling.
Phase-driven Domain Generalizable Learning for Nonstationary Time Series
Feb 05, 2024Monitoring and recognizing patterns in continuous sensing data is crucial for many practical applications. These real-world time-series data are often nonstationary, characterized by varying statistical and spectral properties over time. This poses a significant challenge in developing learning models that can effectively generalize across different distributions. In this work, based on our observation that nonstationary statistics are intrinsically linked to the phase information, we propose a time-series learning framework, PhASER. It consists of three novel elements: 1) phase augmentation that diversifies non-stationarity while preserving discriminatory semantics, 2) separate feature encoding by viewing time-varying magnitude and phase as independent modalities, and 3) feature broadcasting by incorporating phase with a novel residual connection for inherent regularization to enhance distribution invariant learning. Upon extensive evaluation on 5 datasets from human activity recognition, sleep-stage classification, and gesture recognition against 10 state-of-the-art baseline methods, we demonstrate that PhASER consistently outperforms the best baselines by an average of 5% and up to 13% in some cases. Moreover, PhASER's principles can be applied broadly to boost the generalization ability of existing time series classification models.
Boosting Long-Delayed Reinforcement Learning with Auxiliary Short-Delayed Task
Feb 05, 2024Reinforcement learning is challenging in delayed scenarios, a common real-world situation where observations and interactions occur with delays. State-of-the-art (SOTA) state-augmentation techniques either suffer from the state-space explosion along with the delayed steps, or performance degeneration in stochastic environments. To address these challenges, our novel Auxiliary-Delayed Reinforcement Learning (AD-RL) leverages an auxiliary short-delayed task to accelerate the learning on a long-delayed task without compromising the performance in stochastic environments. Specifically, AD-RL learns the value function in the short-delayed task and then employs it with the bootstrapping and policy improvement techniques in the long-delayed task. We theoretically show that this can greatly reduce the sample complexity compared to directly learning on the original long-delayed task. On deterministic and stochastic benchmarks, our method remarkably outperforms the SOTAs in both sample efficiency and policy performance.