 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQing Wang
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024
This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
Local Vertex Colouring Graph Neural Networks
Mar 10, 2024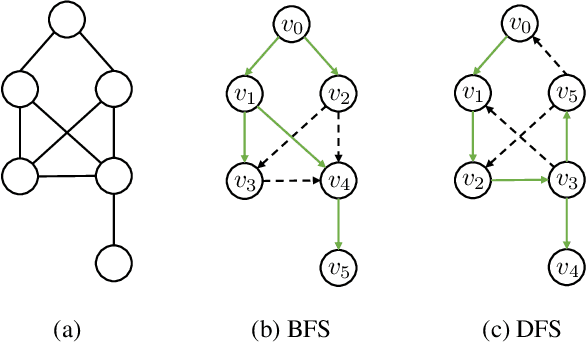

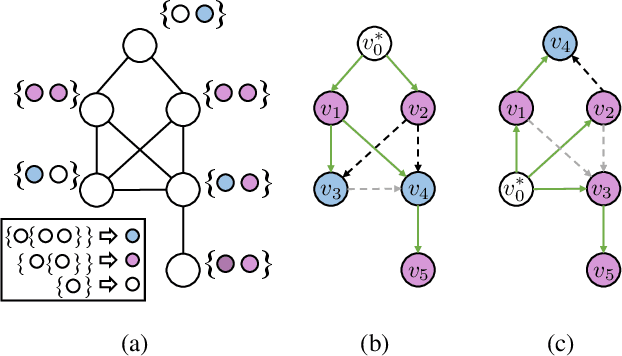
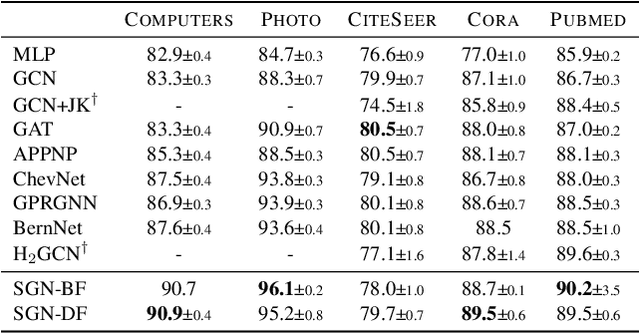
In recent years, there has been a significant amount of research focused on expanding the expressivity of Graph Neural Networks (GNNs) beyond the Weisfeiler-Lehman (1-WL) framework. While many of these studies have yielded advancements in expressivity, they have frequently come at the expense of decreased efficiency or have been restricted to specific types of graphs. In this study, we investigate the expressivity of GNNs from the perspective of graph search. Specifically, we propose a new vertex colouring scheme and demonstrate that classical search algorithms can efficiently compute graph representations that extend beyond the 1-WL. We show the colouring scheme inherits useful properties from graph search that can help solve problems like graph biconnectivity. Furthermore, we show that under certain conditions, the expressivity of GNNs increases hierarchically with the radius of the search neighbourhood. To further investigate the proposed scheme, we develop a new type of GNN based on two search strategies, breadth-first search and depth-first search, highlighting the graph properties they can capture on top of 1-WL. Our code is available at https://github.com/seanli3/lvc.
* 22 pages, 8 figures
Generalization of Graph Neural Networks through the Lens of Homomorphism
Mar 10, 2024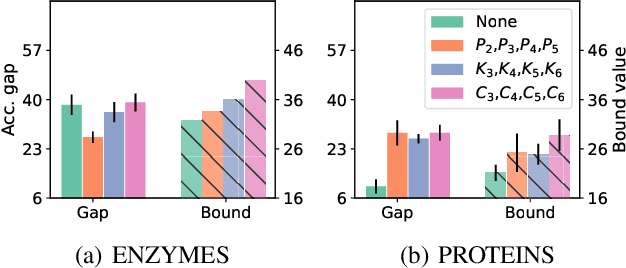
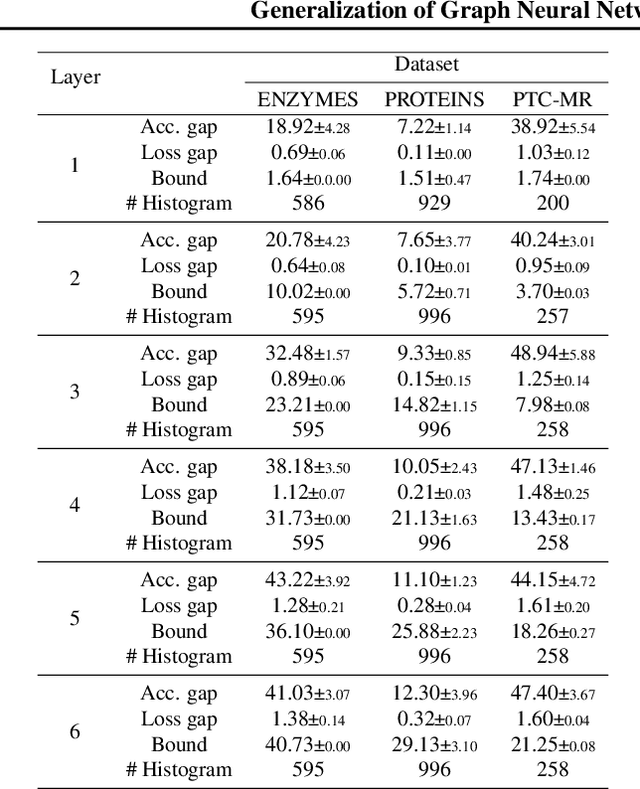
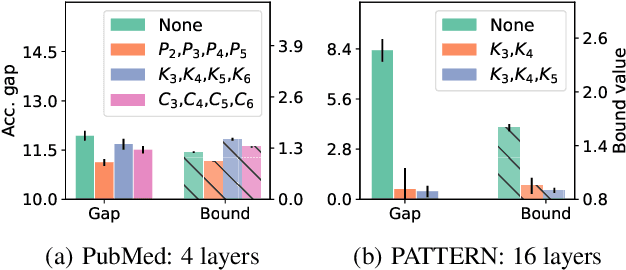
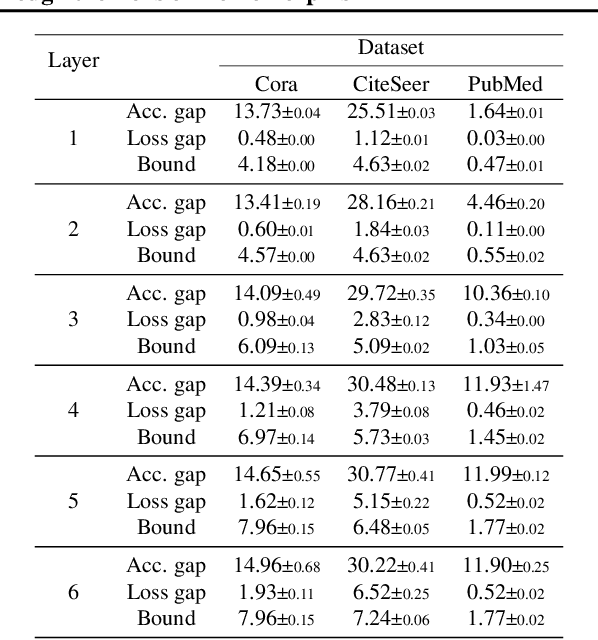
Despite the celebrated popularity of Graph Neural Networks (GNNs) across numerous applications, the ability of GNNs to generalize remains less explored. In this work, we propose to study the generalization of GNNs through a novel perspective - analyzing the entropy of graph homomorphism. By linking graph homomorphism with information-theoretic measures, we derive generalization bounds for both graph and node classifications. These bounds are capable of capturing subtleties inherent in various graph structures, including but not limited to paths, cycles and cliques. This enables a data-dependent generalization analysis with robust theoretical guarantees. To shed light on the generality of of our proposed bounds, we present a unifying framework that can characterize a broad spectrum of GNN models through the lens of graph homomorphism. We validate the practical applicability of our theoretical findings by showing the alignment between the proposed bounds and the empirically observed generalization gaps over both real-world and synthetic datasets.
VEglue: Testing Visual Entailment Systems via Object-Aligned Joint Erasing
Mar 05, 2024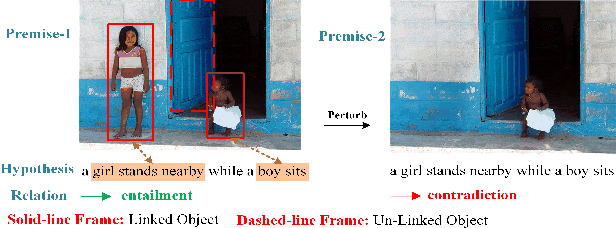

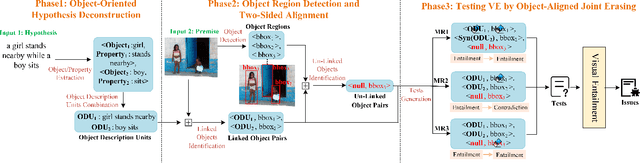
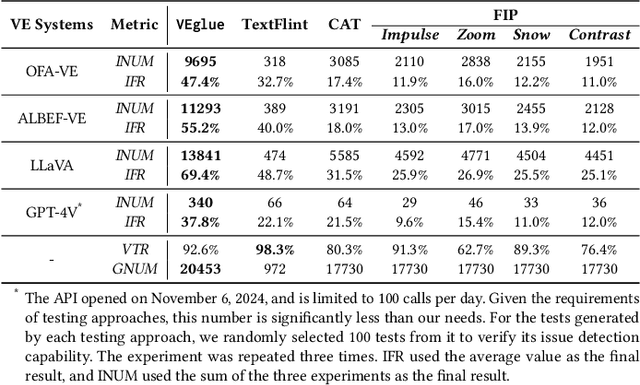
Visual entailment (VE) is a multimodal reasoning task consisting of image-sentence pairs whereby a promise is defined by an image, and a hypothesis is described by a sentence. The goal is to predict whether the image semantically entails the sentence. VE systems have been widely adopted in many downstream tasks. Metamorphic testing is the commonest technique for AI algorithms, but it poses a significant challenge for VE testing. They either only consider perturbations on single modality which would result in ineffective tests due to the destruction of the relationship of image-text pair, or just conduct shallow perturbations on the inputs which can hardly detect the decision error made by VE systems. Motivated by the fact that objects in the image are the fundamental element for reasoning, we propose VEglue, an object-aligned joint erasing approach for VE systems testing. It first aligns the object regions in the premise and object descriptions in the hypothesis to identify linked and un-linked objects. Then, based on the alignment information, three Metamorphic Relations are designed to jointly erase the objects of the two modalities. We evaluate VEglue on four widely-used VE systems involving two public datasets. Results show that VEglue could detect 11,609 issues on average, which is 194%-2,846% more than the baselines. In addition, VEglue could reach 52.5% Issue Finding Rate (IFR) on average, and significantly outperform the baselines by 17.1%-38.2%. Furthermore, we leverage the tests generated by VEglue to retrain the VE systems, which largely improves model performance (50.8% increase in accuracy) on newly generated tests without sacrificing the accuracy on the original test set.
Adversarial Testing for Visual Grounding via Image-Aware Property Reduction
Mar 02, 2024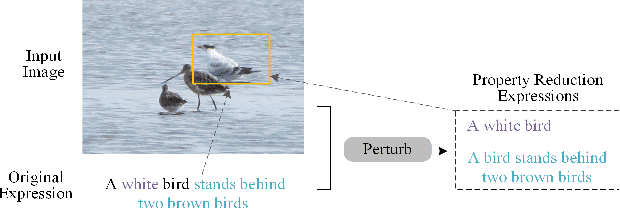

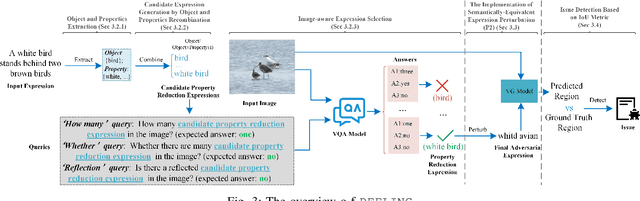

Due to the advantages of fusing information from various modalities, multimodal learning is gaining increasing attention. Being a fundamental task of multimodal learning, Visual Grounding (VG), aims to locate objects in images through natural language expressions. Ensuring the quality of VG models presents significant challenges due to the complex nature of the task. In the black box scenario, existing adversarial testing techniques often fail to fully exploit the potential of both modalities of information. They typically apply perturbations based solely on either the image or text information, disregarding the crucial correlation between the two modalities, which would lead to failures in test oracles or an inability to effectively challenge VG models. To this end, we propose PEELING, a text perturbation approach via image-aware property reduction for adversarial testing of the VG model. The core idea is to reduce the property-related information in the original expression meanwhile ensuring the reduced expression can still uniquely describe the original object in the image. To achieve this, PEELING first conducts the object and properties extraction and recombination to generate candidate property reduction expressions. It then selects the satisfied expressions that accurately describe the original object while ensuring no other objects in the image fulfill the expression, through querying the image with a visual understanding technique. We evaluate PEELING on the state-of-the-art VG model, i.e. OFA-VG, involving three commonly used datasets. Results show that the adversarial tests generated by PEELING achieves 21.4% in MultiModal Impact score (MMI), and outperforms state-of-the-art baselines for images and texts by 8.2%--15.1%.
Re-Examine Distantly Supervised NER: A New Benchmark and a Simple Approach
Feb 26, 2024This paper delves into Named Entity Recognition (NER) under the framework of Distant Supervision (DS-NER), where the main challenge lies in the compromised quality of labels due to inherent errors such as false positives, false negatives, and positive type errors. We critically assess the efficacy of current DS-NER methodologies using a real-world benchmark dataset named QTL, revealing that their performance often does not meet expectations. To tackle the prevalent issue of label noise, we introduce a simple yet effective approach, Curriculum-based Positive-Unlabeled Learning CuPUL, which strategically starts on "easy" and cleaner samples during the training process to enhance model resilience to noisy samples. Our empirical results highlight the capability of CuPUL to significantly reduce the impact of noisy labels and outperform existing methods. QTL dataset and our code is available on GitHub.
Play Guessing Game with LLM: Indirect Jailbreak Attack with Implicit Clues
Feb 16, 2024With the development of LLMs, the security threats of LLMs are getting more and more attention. Numerous jailbreak attacks have been proposed to assess the security defense of LLMs. Current jailbreak attacks primarily utilize scenario camouflage techniques. However their explicitly mention of malicious intent will be easily recognized and defended by LLMs. In this paper, we propose an indirect jailbreak attack approach, Puzzler, which can bypass the LLM's defense strategy and obtain malicious response by implicitly providing LLMs with some clues about the original malicious query. In addition, inspired by the wisdom of "When unable to attack, defend" from Sun Tzu's Art of War, we adopt a defensive stance to gather clues about the original malicious query through LLMs. Extensive experimental results show that Puzzler achieves a query success rate of 96.6% on closed-source LLMs, which is 57.9%-82.7% higher than baselines. Furthermore, when tested against the state-of-the-art jailbreak detection approaches, Puzzler proves to be more effective at evading detection compared to baselines.
SNP-S3: Shared Network Pre-training and Significant Semantic Strengthening for Various Video-Text Tasks
Jan 31, 2024We present a framework for learning cross-modal video representations by directly pre-training on raw data to facilitate various downstream video-text tasks. Our main contributions lie in the pre-training framework and proxy tasks. First, based on the shortcomings of two mainstream pixel-level pre-training architectures (limited applications or less efficient), we propose Shared Network Pre-training (SNP). By employing one shared BERT-type network to refine textual and cross-modal features simultaneously, SNP is lightweight and could support various downstream applications. Second, based on the intuition that people always pay attention to several "significant words" when understanding a sentence, we propose the Significant Semantic Strengthening (S3) strategy, which includes a novel masking and matching proxy task to promote the pre-training performance. Experiments conducted on three downstream video-text tasks and six datasets demonstrate that, we establish a new state-of-the-art in pixel-level video-text pre-training; we also achieve a satisfactory balance between the pre-training efficiency and the fine-tuning performance. The codebase are available at https://github.com/alipay/Ant-Multi-Modal-Framework/tree/main/prj/snps3_vtp.
Dual-View Data Hallucination with Semantic Relation Guidance for Few-Shot Image Recognition
Jan 13, 2024Learning to recognize novel concepts from just a few image samples is very challenging as the learned model is easily overfitted on the few data and results in poor generalizability. One promising but underexplored solution is to compensate the novel classes by generating plausible samples. However, most existing works of this line exploit visual information only, rendering the generated data easy to be distracted by some challenging factors contained in the few available samples. Being aware of the semantic information in the textual modality that reflects human concepts, this work proposes a novel framework that exploits semantic relations to guide dual-view data hallucination for few-shot image recognition. The proposed framework enables generating more diverse and reasonable data samples for novel classes through effective information transfer from base classes. Specifically, an instance-view data hallucination module hallucinates each sample of a novel class to generate new data by employing local semantic correlated attention and global semantic feature fusion derived from base classes. Meanwhile, a prototype-view data hallucination module exploits semantic-aware measure to estimate the prototype of a novel class and the associated distribution from the few samples, which thereby harvests the prototype as a more stable sample and enables resampling a large number of samples. We conduct extensive experiments and comparisons with state-of-the-art methods on several popular few-shot benchmarks to verify the effectiveness of the proposed framework.
Uplifting the Expressive Power of Graph Neural Networks through Graph Partitioning
Dec 14, 2023Graph Neural Networks (GNNs) have paved its way for being a cornerstone in graph related learning tasks. From a theoretical perspective, the expressive power of GNNs is primarily characterised according to their ability to distinguish non-isomorphic graphs. It is a well-known fact that most of the conventional GNNs are upper-bounded by Weisfeiler-Lehman graph isomorphism test (1-WL). In this work, we study the expressive power of graph neural networks through the lens of graph partitioning. This follows from our observation that permutation invariant graph partitioning enables a powerful way of exploring structural interactions among vertex sets and subgraphs, and can help uplifting the expressive power of GNNs efficiently. Based on this, we first establish a theoretical connection between graph partitioning and graph isomorphism. Then we introduce a novel GNN architecture, namely Graph Partitioning Neural Networks (GPNNs). We theoretically analyse how a graph partitioning scheme and different kinds of structural interactions relate to the k-WL hierarchy. Empirically, we demonstrate its superior performance over existing GNN models in a variety of graph benchmark tasks.