 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBo Wang
WPS-Dataset: A benchmark for wood plate segmentation in bark removal processing
Apr 17, 2024
Using deep learning methods is a promising approach to improving bark removal efficiency and enhancing the quality of wood products. However, the lack of publicly available datasets for wood plate segmentation in bark removal processing poses challenges for researchers in this field. To address this issue, a benchmark for wood plate segmentation in bark removal processing named WPS-dataset is proposed in this study, which consists of 4863 images. We designed an image acquisition device and assembled it on a bark removal equipment to capture images in real industrial settings. We evaluated the WPS-dataset using six typical segmentation models. The models effectively learn and understand the WPS-dataset characteristics during training, resulting in high performance and accuracy in wood plate segmentation tasks. We believe that our dataset can lay a solid foundation for future research in bark removal processing and contribute to advancements in this field.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
NTIRE 2024 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 15, 2024This paper reviews the NTIRE 2024 challenge on image super-resolution ($\times$4), highlighting the solutions proposed and the outcomes obtained. The challenge involves generating corresponding high-resolution (HR) images, magnified by a factor of four, from low-resolution (LR) inputs using prior information. The LR images originate from bicubic downsampling degradation. The aim of the challenge is to obtain designs/solutions with the most advanced SR performance, with no constraints on computational resources (e.g., model size and FLOPs) or training data. The track of this challenge assesses performance with the PSNR metric on the DIV2K testing dataset. The competition attracted 199 registrants, with 20 teams submitting valid entries. This collective endeavour not only pushes the boundaries of performance in single-image SR but also offers a comprehensive overview of current trends in this field.
Efficient and accurate neural field reconstruction using resistive memory
Apr 15, 2024Human beings construct perception of space by integrating sparse observations into massively interconnected synapses and neurons, offering a superior parallelism and efficiency. Replicating this capability in AI finds wide applications in medical imaging, AR/VR, and embodied AI, where input data is often sparse and computing resources are limited. However, traditional signal reconstruction methods on digital computers face both software and hardware challenges. On the software front, difficulties arise from storage inefficiencies in conventional explicit signal representation. Hardware obstacles include the von Neumann bottleneck, which limits data transfer between the CPU and memory, and the limitations of CMOS circuits in supporting parallel processing. We propose a systematic approach with software-hardware co-optimizations for signal reconstruction from sparse inputs. Software-wise, we employ neural field to implicitly represent signals via neural networks, which is further compressed using low-rank decomposition and structured pruning. Hardware-wise, we design a resistive memory-based computing-in-memory (CIM) platform, featuring a Gaussian Encoder (GE) and an MLP Processing Engine (PE). The GE harnesses the intrinsic stochasticity of resistive memory for efficient input encoding, while the PE achieves precise weight mapping through a Hardware-Aware Quantization (HAQ) circuit. We demonstrate the system's efficacy on a 40nm 256Kb resistive memory-based in-memory computing macro, achieving huge energy efficiency and parallelism improvements without compromising reconstruction quality in tasks like 3D CT sparse reconstruction, novel view synthesis, and novel view synthesis for dynamic scenes. This work advances the AI-driven signal restoration technology and paves the way for future efficient and robust medical AI and 3D vision applications.
Resistive Memory-based Neural Differential Equation Solver for Score-based Diffusion Model
Apr 08, 2024Human brains image complicated scenes when reading a novel. Replicating this imagination is one of the ultimate goals of AI-Generated Content (AIGC). However, current AIGC methods, such as score-based diffusion, are still deficient in terms of rapidity and efficiency. This deficiency is rooted in the difference between the brain and digital computers. Digital computers have physically separated storage and processing units, resulting in frequent data transfers during iterative calculations, incurring large time and energy overheads. This issue is further intensified by the conversion of inherently continuous and analog generation dynamics, which can be formulated by neural differential equations, into discrete and digital operations. Inspired by the brain, we propose a time-continuous and analog in-memory neural differential equation solver for score-based diffusion, employing emerging resistive memory. The integration of storage and computation within resistive memory synapses surmount the von Neumann bottleneck, benefiting the generative speed and energy efficiency. The closed-loop feedback integrator is time-continuous, analog, and compact, physically implementing an infinite-depth neural network. Moreover, the software-hardware co-design is intrinsically robust to analog noise. We experimentally validate our solution with 180 nm resistive memory in-memory computing macros. Demonstrating equivalent generative quality to the software baseline, our system achieved remarkable enhancements in generative speed for both unconditional and conditional generation tasks, by factors of 64.8 and 156.5, respectively. Moreover, it accomplished reductions in energy consumption by factors of 5.2 and 4.1. Our approach heralds a new horizon for hardware solutions in edge computing for generative AI applications.
FraGNNet: A Deep Probabilistic Model for Mass Spectrum Prediction
Apr 02, 2024The process of identifying a compound from its mass spectrum is a critical step in the analysis of complex mixtures. Typical solutions for the mass spectrum to compound (MS2C) problem involve matching the unknown spectrum against a library of known spectrum-molecule pairs, an approach that is limited by incomplete library coverage. Compound to mass spectrum (C2MS) models can improve retrieval rates by augmenting real libraries with predicted spectra. Unfortunately, many existing C2MS models suffer from problems with prediction resolution, scalability, or interpretability. We develop a new probabilistic method for C2MS prediction, FraGNNet, that can efficiently and accurately predict high-resolution spectra. FraGNNet uses a structured latent space to provide insight into the underlying processes that define the spectrum. Our model achieves state-of-the-art performance in terms of prediction error, and surpasses existing C2MS models as a tool for retrieval-based MS2C.
Rethinking Multi-view Representation Learning via Distilled Disentangling
Mar 29, 2024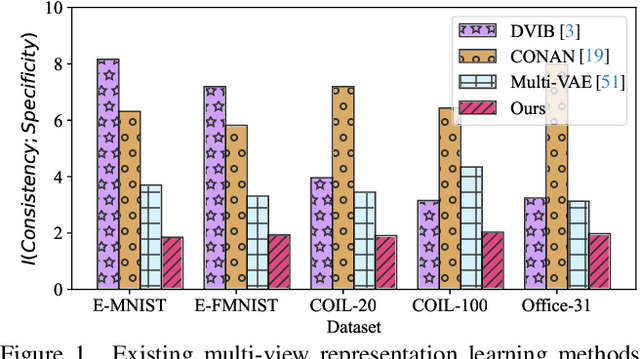
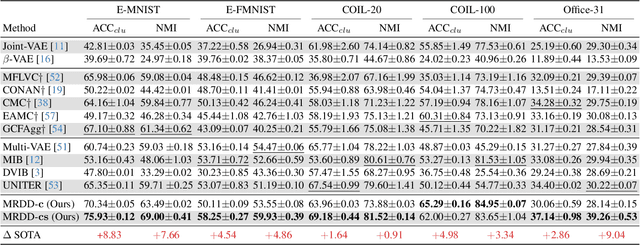
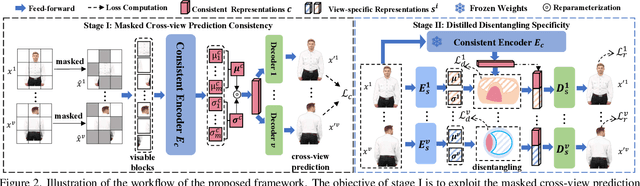
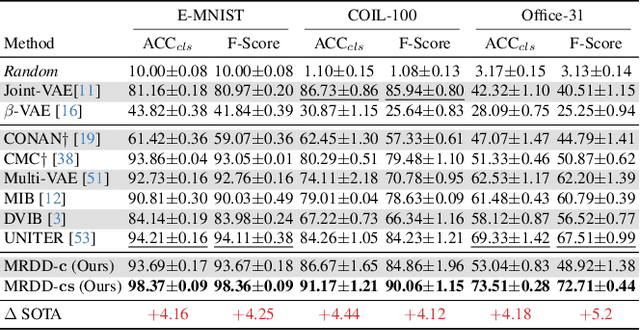
Multi-view representation learning aims to derive robust representations that are both view-consistent and view-specific from diverse data sources. This paper presents an in-depth analysis of existing approaches in this domain, highlighting a commonly overlooked aspect: the redundancy between view-consistent and view-specific representations. To this end, we propose an innovative framework for multi-view representation learning, which incorporates a technique we term 'distilled disentangling'. Our method introduces the concept of masked cross-view prediction, enabling the extraction of compact, high-quality view-consistent representations from various sources without incurring extra computational overhead. Additionally, we develop a distilled disentangling module that efficiently filters out consistency-related information from multi-view representations, resulting in purer view-specific representations. This approach significantly reduces redundancy between view-consistent and view-specific representations, enhancing the overall efficiency of the learning process. Our empirical evaluations reveal that higher mask ratios substantially improve the quality of view-consistent representations. Moreover, we find that reducing the dimensionality of view-consistent representations relative to that of view-specific representations further refines the quality of the combined representations. Our code is accessible at: https://github.com/Guanzhou-Ke/MRDD.
SceneTracker: Long-term Scene Flow Estimation Network
Mar 29, 2024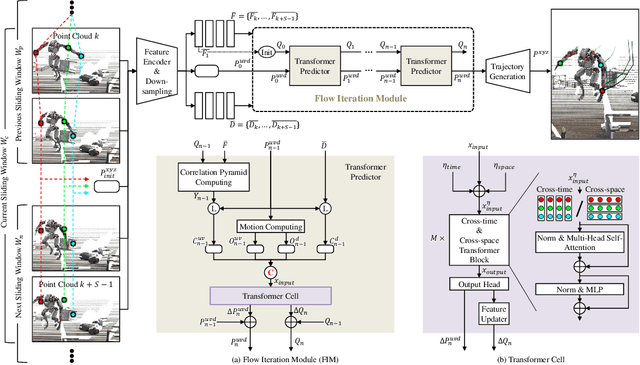



Considering the complementarity of scene flow estimation in the spatial domain's focusing capability and 3D object tracking in the temporal domain's coherence, this study aims to address a comprehensive new task that can simultaneously capture fine-grained and long-term 3D motion in an online manner: long-term scene flow estimation (LSFE). We introduce SceneTracker, a novel learning-based LSFE network that adopts an iterative approach to approximate the optimal trajectory. Besides, it dynamically indexes and constructs appearance and depth correlation features simultaneously and employs the Transformer to explore and utilize long-range connections within and between trajectories. With detailed experiments, SceneTracker shows superior capabilities in handling 3D spatial occlusion and depth noise interference, highly tailored to the LSFE task's needs. The code for SceneTracker is available at https://github.com/wwsource/SceneTracker.
Knowledge Condensation and Reasoning for Knowledge-based VQA
Mar 15, 2024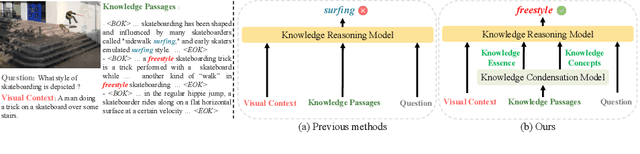
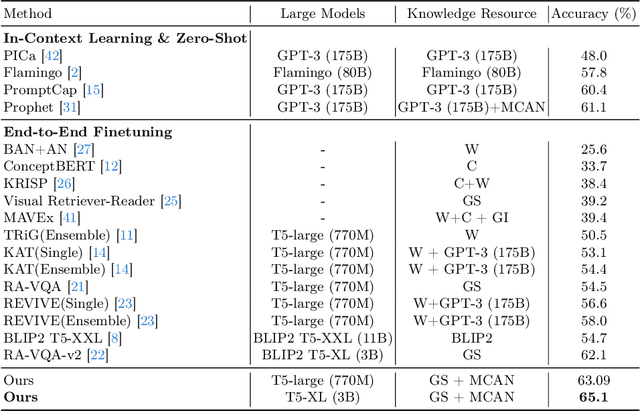
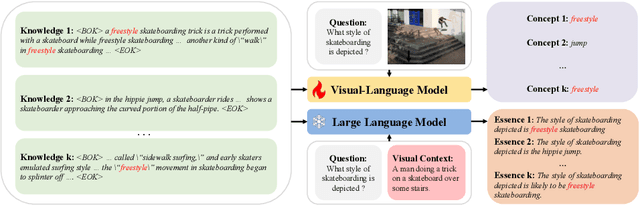
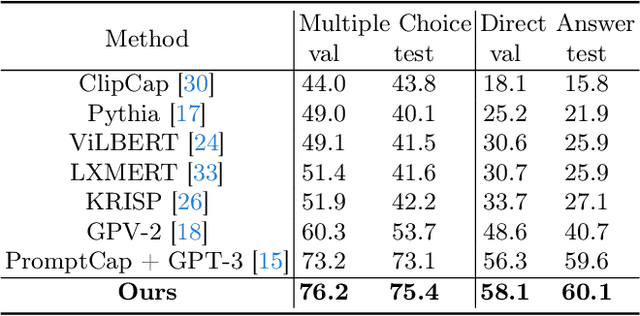
Knowledge-based visual question answering (KB-VQA) is a challenging task, which requires the model to leverage external knowledge for comprehending and answering questions grounded in visual content. Recent studies retrieve the knowledge passages from external knowledge bases and then use them to answer questions. However, these retrieved knowledge passages often contain irrelevant or noisy information, which limits the performance of the model. To address the challenge, we propose two synergistic models: Knowledge Condensation model and Knowledge Reasoning model. We condense the retrieved knowledge passages from two perspectives. First, we leverage the multimodal perception and reasoning ability of the visual-language models to distill concise knowledge concepts from retrieved lengthy passages, ensuring relevance to both the visual content and the question. Second, we leverage the text comprehension ability of the large language models to summarize and condense the passages into the knowledge essence which helps answer the question. These two types of condensed knowledge are then seamlessly integrated into our Knowledge Reasoning model, which judiciously navigates through the amalgamated information to arrive at the conclusive answer. Extensive experiments validate the superiority of the proposed method. Compared to previous methods, our method achieves state-of-the-art performance on knowledge-based VQA datasets (65.1% on OK-VQA and 60.1% on A-OKVQA) without resorting to the knowledge produced by GPT-3 (175B).