 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiawei Yu
Not All Voxels Are Equal: Hardness-Aware Semantic Scene Completion with Self-Distillation
Apr 18, 2024
Semantic scene completion, also known as semantic occupancy prediction, can provide dense geometric and semantic information for autonomous vehicles, which attracts the increasing attention of both academia and industry. Unfortunately, existing methods usually formulate this task as a voxel-wise classification problem and treat each voxel equally in 3D space during training. As the hard voxels have not been paid enough attention, the performance in some challenging regions is limited. The 3D dense space typically contains a large number of empty voxels, which are easy to learn but require amounts of computation due to handling all the voxels uniformly for the existing models. Furthermore, the voxels in the boundary region are more challenging to differentiate than those in the interior. In this paper, we propose HASSC approach to train the semantic scene completion model with hardness-aware design. The global hardness from the network optimization process is defined for dynamical hard voxel selection. Then, the local hardness with geometric anisotropy is adopted for voxel-wise refinement. Besides, self-distillation strategy is introduced to make training process stable and consistent. Extensive experiments show that our HASSC scheme can effectively promote the accuracy of the baseline model without incurring the extra inference cost. Source code is available at: https://github.com/songw-zju/HASSC.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
SUN Team's Contribution to ABAW 2024 Competition: Audio-visual Valence-Arousal Estimation and Expression Recognition
Mar 19, 2024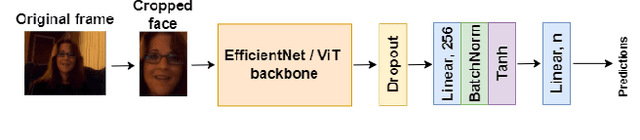
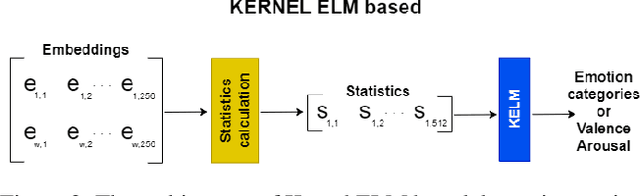
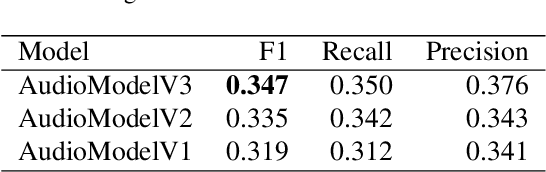

As emotions play a central role in human communication, automatic emotion recognition has attracted increasing attention in the last two decades. While multimodal systems enjoy high performances on lab-controlled data, they are still far from providing ecological validity on non-lab-controlled, namely 'in-the-wild' data. This work investigates audiovisual deep learning approaches for emotion recognition in-the-wild problem. We particularly explore the effectiveness of architectures based on fine-tuned Convolutional Neural Networks (CNN) and Public Dimensional Emotion Model (PDEM), for video and audio modality, respectively. We compare alternative temporal modeling and fusion strategies using the embeddings from these multi-stage trained modality-specific Deep Neural Networks (DNN). We report results on the AffWild2 dataset under Affective Behavior Analysis in-the-Wild 2024 (ABAW'24) challenge protocol.
Using Large Language Model for End-to-End Chinese ASR and NER
Jan 21, 2024Mapping speech tokens to the same feature space as text tokens has become the paradigm for the integration of speech modality into decoder-only large language models (LLMs). An alternative approach is to use an encoder-decoder architecture that incorporates speech features through cross-attention. This approach, however, has received less attention in the literature. In this work, we connect the Whisper encoder with ChatGLM3 and provide in-depth comparisons of these two approaches using Chinese automatic speech recognition (ASR) and name entity recognition (NER) tasks. We evaluate them not only by conventional metrics like the F1 score but also by a novel fine-grained taxonomy of ASR-NER errors. Our experiments reveal that encoder-decoder architecture outperforms decoder-only architecture with a short context, while decoder-only architecture benefits from a long context as it fully exploits all layers of the LLM. By using LLM, we significantly reduced the entity omission errors and improved the entity ASR accuracy compared to the Conformer baseline. Additionally, we obtained a state-of-the-art (SOTA) F1 score of 0.805 on the AISHELL-NER test set by using chain-of-thought (CoT) NER which first infers long-form ASR transcriptions and then predicts NER labels.
CB-Whisper: Contextual Biasing Whisper using TTS-based Keyword Spotting
Sep 18, 2023
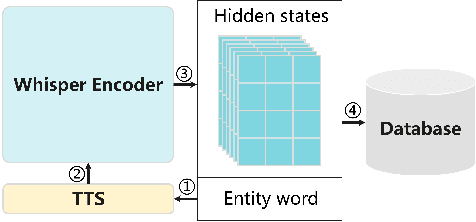
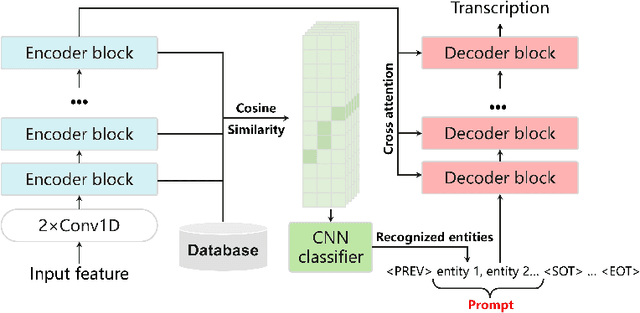
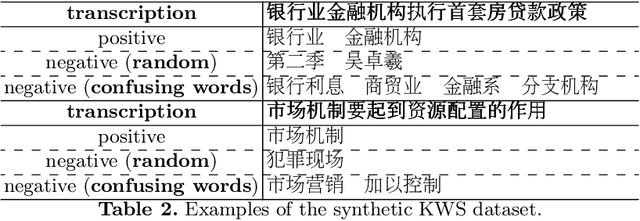
End-to-end automatic speech recognition (ASR) systems often struggle to recognize rare name entities, such as personal names, organizations, or technical terms that are not frequently encountered in the training data. This paper presents Contextual Biasing Whisper (CB-Whisper), a novel ASR system based on OpenAI's Whisper model that performs keyword-spotting (KWS) before the decoder. The KWS module leverages text-to-speech (TTS) techniques and a convolutional neural network (CNN) classifier to match the features between the entities and the utterances. Experiments demonstrate that by incorporating predicted entities into a carefully designed spoken form prompt, the mixed-error-rate (MER) and entity recall of the Whisper model is significantly improved on three internal datasets and two open-sourced datasets that cover English-only, Chinese-only, and code-switching scenarios.
Exploring Better Text Image Translation with Multimodal Codebook
Jun 02, 2023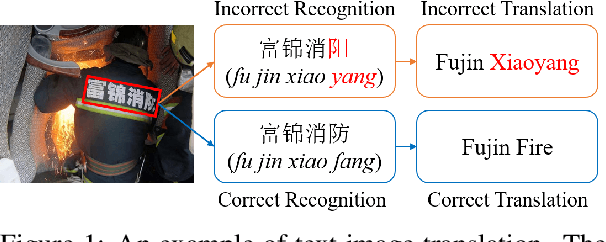
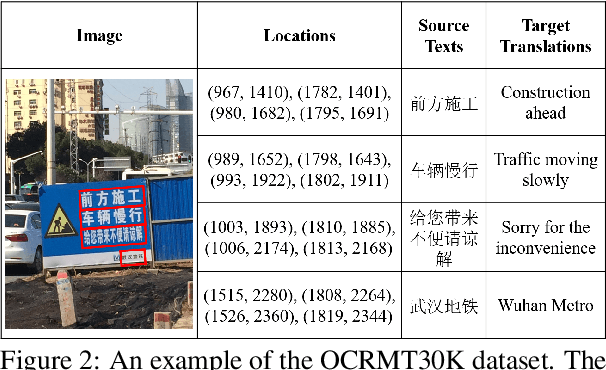
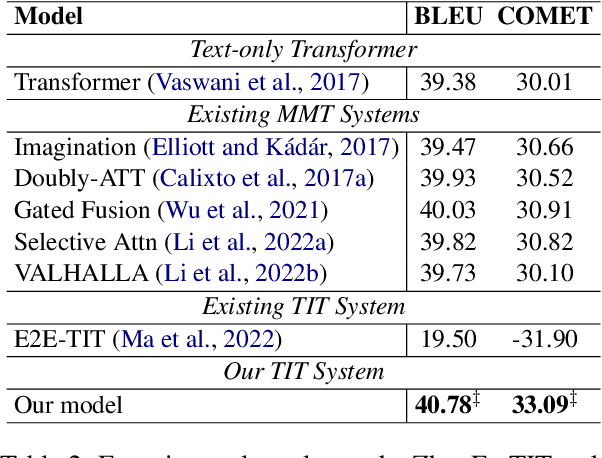
Text image translation (TIT) aims to translate the source texts embedded in the image to target translations, which has a wide range of applications and thus has important research value. However, current studies on TIT are confronted with two main bottlenecks: 1) this task lacks a publicly available TIT dataset, 2) dominant models are constructed in a cascaded manner, which tends to suffer from the error propagation of optical character recognition (OCR). In this work, we first annotate a Chinese-English TIT dataset named OCRMT30K, providing convenience for subsequent studies. Then, we propose a TIT model with a multimodal codebook, which is able to associate the image with relevant texts, providing useful supplementary information for translation. Moreover, we present a multi-stage training framework involving text machine translation, image-text alignment, and TIT tasks, which fully exploits additional bilingual texts, OCR dataset and our OCRMT30K dataset to train our model. Extensive experiments and in-depth analyses strongly demonstrate the effectiveness of our proposed model and training framework.
FastFlow: Unsupervised Anomaly Detection and Localization via 2D Normalizing Flows
Nov 16, 2021
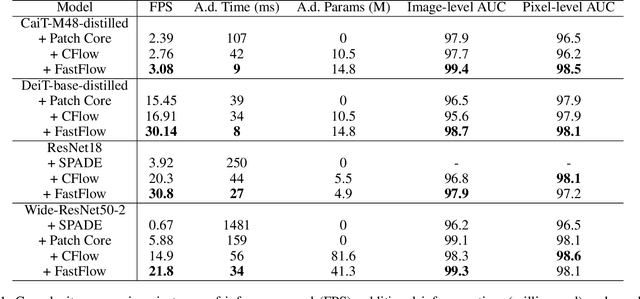
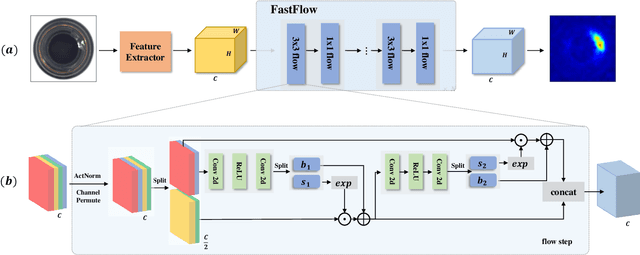
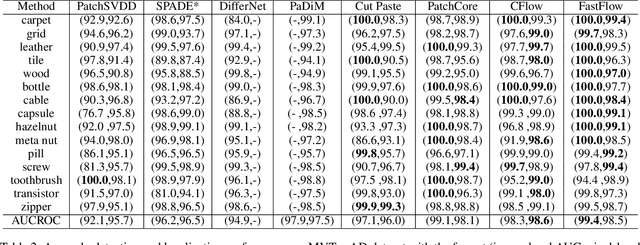
Unsupervised anomaly detection and localization is crucial to the practical application when collecting and labeling sufficient anomaly data is infeasible. Most existing representation-based approaches extract normal image features with a deep convolutional neural network and characterize the corresponding distribution through non-parametric distribution estimation methods. The anomaly score is calculated by measuring the distance between the feature of the test image and the estimated distribution. However, current methods can not effectively map image features to a tractable base distribution and ignore the relationship between local and global features which are important to identify anomalies. To this end, we propose FastFlow implemented with 2D normalizing flows and use it as the probability distribution estimator. Our FastFlow can be used as a plug-in module with arbitrary deep feature extractors such as ResNet and vision transformer for unsupervised anomaly detection and localization. In training phase, FastFlow learns to transform the input visual feature into a tractable distribution and obtains the likelihood to recognize anomalies in inference phase. Extensive experimental results on the MVTec AD dataset show that FastFlow surpasses previous state-of-the-art methods in terms of accuracy and inference efficiency with various backbone networks. Our approach achieves 99.4% AUC in anomaly detection with high inference efficiency.