 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheng Wan
MIPI 2024 Challenge on Demosaic for HybridEVS Camera: Methods and Results
May 08, 2024
The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2024. In total, 170 participants were successfully registered, and 14 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2024/.
Real-Time 4K Super-Resolution of Compressed AVIF Images. AIS 2024 Challenge Survey
Apr 25, 2024This paper introduces a novel benchmark as part of the AIS 2024 Real-Time Image Super-Resolution (RTSR) Challenge, which aims to upscale compressed images from 540p to 4K resolution (4x factor) in real-time on commercial GPUs. For this, we use a diverse test set containing a variety of 4K images ranging from digital art to gaming and photography. The images are compressed using the modern AVIF codec, instead of JPEG. All the proposed methods improve PSNR fidelity over Lanczos interpolation, and process images under 10ms. Out of the 160 participants, 25 teams submitted their code and models. The solutions present novel designs tailored for memory-efficiency and runtime on edge devices. This survey describes the best solutions for real-time SR of compressed high-resolution images.
Deep RAW Image Super-Resolution. A NTIRE 2024 Challenge Survey
Apr 24, 2024This paper reviews the NTIRE 2024 RAW Image Super-Resolution Challenge, highlighting the proposed solutions and results. New methods for RAW Super-Resolution could be essential in modern Image Signal Processing (ISP) pipelines, however, this problem is not as explored as in the RGB domain. Th goal of this challenge is to upscale RAW Bayer images by 2x, considering unknown degradations such as noise and blur. In the challenge, a total of 230 participants registered, and 45 submitted results during thee challenge period. The performance of the top-5 submissions is reviewed and provided here as a gauge for the current state-of-the-art in RAW Image Super-Resolution.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
NTIRE 2024 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 15, 2024This paper reviews the NTIRE 2024 challenge on image super-resolution ($\times$4), highlighting the solutions proposed and the outcomes obtained. The challenge involves generating corresponding high-resolution (HR) images, magnified by a factor of four, from low-resolution (LR) inputs using prior information. The LR images originate from bicubic downsampling degradation. The aim of the challenge is to obtain designs/solutions with the most advanced SR performance, with no constraints on computational resources (e.g., model size and FLOPs) or training data. The track of this challenge assesses performance with the PSNR metric on the DIV2K testing dataset. The competition attracted 199 registrants, with 20 teams submitting valid entries. This collective endeavour not only pushes the boundaries of performance in single-image SR but also offers a comprehensive overview of current trends in this field.
Real-Time Image Segmentation via Hybrid Convolutional-Transformer Architecture Search
Mar 15, 2024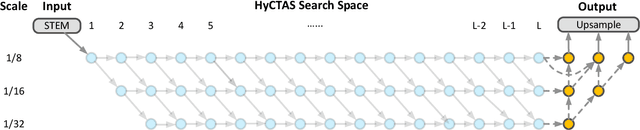
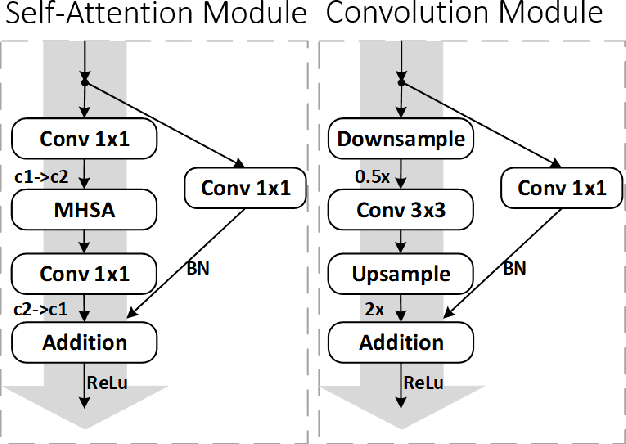
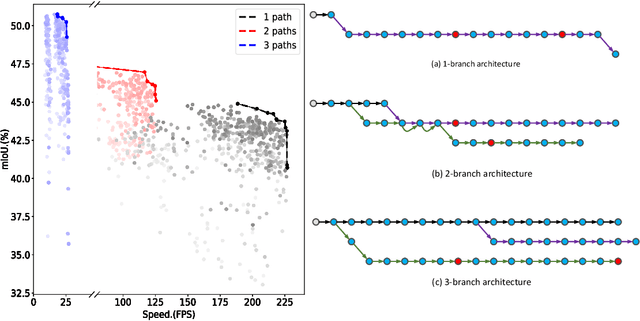
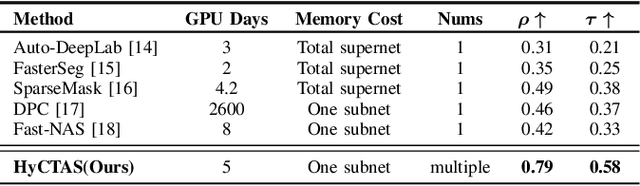
Image segmentation is one of the most fundamental problems in computer vision and has drawn a lot of attentions due to its vast applications in image understanding and autonomous driving. However, designing effective and efficient segmentation neural architectures is a labor-intensive process that may require lots of trials by human experts. In this paper, we address the challenge of integrating multi-head self-attention into high resolution representation CNNs efficiently, by leveraging architecture search. Manually replacing convolution layers with multi-head self-attention is non-trivial due to the costly overhead in memory to maintain high resolution. By contrast, we develop a multi-target multi-branch supernet method, which not only fully utilizes the advantages of high-resolution features, but also finds the proper location for placing multi-head self-attention module. Our search algorithm is optimized towards multiple objective s (e.g., latency and mIoU) and capable of finding architectures on Pareto frontier with arbitrary number of branches in a single search. We further present a series of model via Hybrid Convolutional-Transformer Architecture Search (HyCTAS) method that searched for the best hybrid combination of light-weight convolution layers and memory-efficient self-attention layers between branches from different resolutions and fuse to high resolution for both efficiency and effectiveness. Extensive experiments demonstrate that HyCTAS outperforms previous methods on semantic segmentation task. Code and models are available at \url{https://github.com/MarvinYu1995/HyCTAS}.
Towards Cognitive AI Systems: a Survey and Prospective on Neuro-Symbolic AI
Jan 02, 2024The remarkable advancements in artificial intelligence (AI), primarily driven by deep neural networks, have significantly impacted various aspects of our lives. However, the current challenges surrounding unsustainable computational trajectories, limited robustness, and a lack of explainability call for the development of next-generation AI systems. Neuro-symbolic AI (NSAI) emerges as a promising paradigm, fusing neural, symbolic, and probabilistic approaches to enhance interpretability, robustness, and trustworthiness while facilitating learning from much less data. Recent NSAI systems have demonstrated great potential in collaborative human-AI scenarios with reasoning and cognitive capabilities. In this paper, we provide a systematic review of recent progress in NSAI and analyze the performance characteristics and computational operators of NSAI models. Furthermore, we discuss the challenges and potential future directions of NSAI from both system and architectural perspectives.
Swift Parameter-free Attention Network for Efficient Super-Resolution
Nov 21, 2023Single Image Super-Resolution (SISR) is a crucial task in low-level computer vision, aiming to reconstruct high-resolution images from low-resolution counterparts. Conventional attention mechanisms have significantly improved SISR performance but often result in complex network structures and large number of parameters, leading to slow inference speed and large model size. To address this issue, we propose the Swift Parameter-free Attention Network (SPAN), a highly efficient SISR model that balances parameter count, inference speed, and image quality. SPAN employs a novel parameter-free attention mechanism, which leverages symmetric activation functions and residual connections to enhance high-contribution information and suppress redundant information. Our theoretical analysis demonstrates the effectiveness of this design in achieving the attention mechanism's purpose. We evaluate SPAN on multiple benchmarks, showing that it outperforms existing efficient super-resolution models in terms of both image quality and inference speed, achieving a significant quality-speed trade-off. This makes SPAN highly suitable for real-world applications, particularly in resource-constrained scenarios. Notably, our model attains the best PSNR of 27.09 dB, and the test runtime of our team is reduced by 7.08ms in the NTIRE 2023 efficient super-resolution challenge. Our code and models are made publicly available at \url{https://github.com/hongyuanyu/SPAN}.
GPT4AIGChip: Towards Next-Generation AI Accelerator Design Automation via Large Language Models
Sep 19, 2023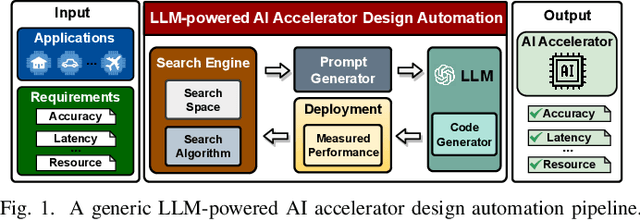
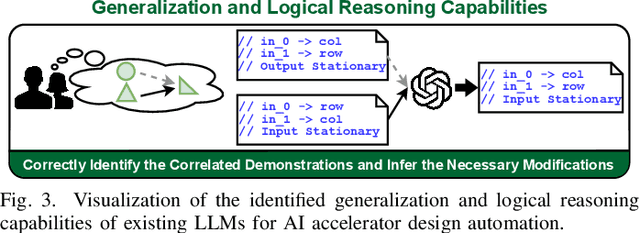
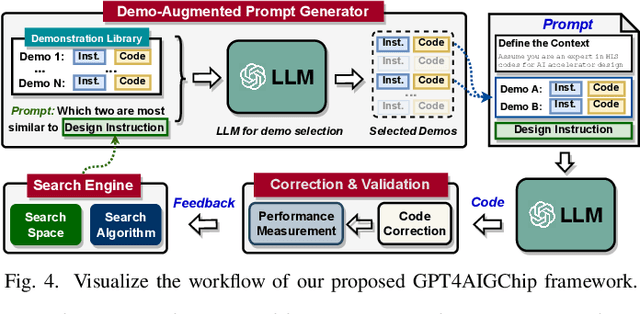
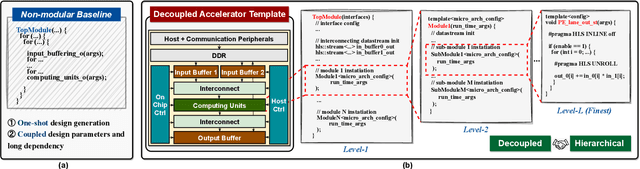
The remarkable capabilities and intricate nature of Artificial Intelligence (AI) have dramatically escalated the imperative for specialized AI accelerators. Nonetheless, designing these accelerators for various AI workloads remains both labor- and time-intensive. While existing design exploration and automation tools can partially alleviate the need for extensive human involvement, they still demand substantial hardware expertise, posing a barrier to non-experts and stifling AI accelerator development. Motivated by the astonishing potential of large language models (LLMs) for generating high-quality content in response to human language instructions, we embark on this work to examine the possibility of harnessing LLMs to automate AI accelerator design. Through this endeavor, we develop GPT4AIGChip, a framework intended to democratize AI accelerator design by leveraging human natural languages instead of domain-specific languages. Specifically, we first perform an in-depth investigation into LLMs' limitations and capabilities for AI accelerator design, thus aiding our understanding of our current position and garnering insights into LLM-powered automated AI accelerator design. Furthermore, drawing inspiration from the above insights, we develop a framework called GPT4AIGChip, which features an automated demo-augmented prompt-generation pipeline utilizing in-context learning to guide LLMs towards creating high-quality AI accelerator design. To our knowledge, this work is the first to demonstrate an effective pipeline for LLM-powered automated AI accelerator generation. Accordingly, we anticipate that our insights and framework can serve as a catalyst for innovations in next-generation LLM-powered design automation tools.
A Survey on Graph Neural Network Acceleration: Algorithms, Systems, and Customized Hardware
Jun 24, 2023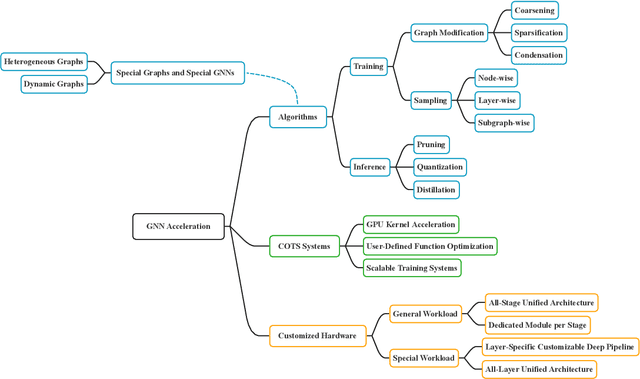
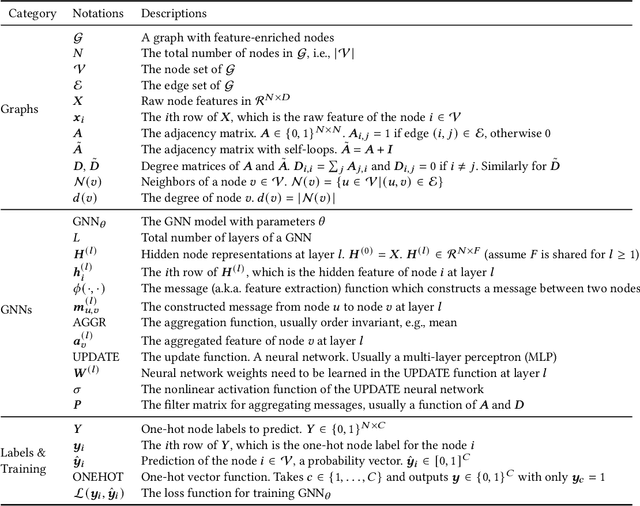
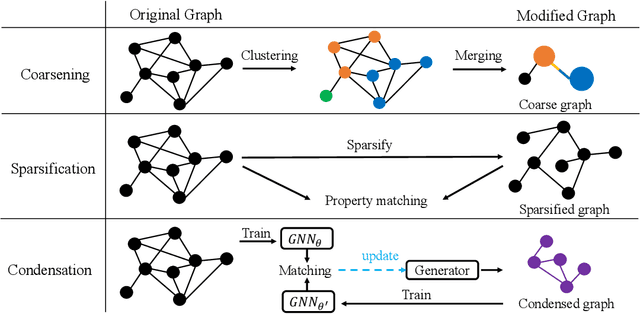
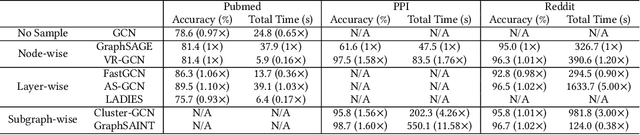
Graph neural networks (GNNs) are emerging for machine learning research on graph-structured data. GNNs achieve state-of-the-art performance on many tasks, but they face scalability challenges when it comes to real-world applications that have numerous data and strict latency requirements. Many studies have been conducted on how to accelerate GNNs in an effort to address these challenges. These acceleration techniques touch on various aspects of the GNN pipeline, from smart training and inference algorithms to efficient systems and customized hardware. As the amount of research on GNN acceleration has grown rapidly, there lacks a systematic treatment to provide a unified view and address the complexity of relevant works. In this survey, we provide a taxonomy of GNN acceleration, review the existing approaches, and suggest future research directions. Our taxonomic treatment of GNN acceleration connects the existing works and sets the stage for further development in this area.