 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaijin Zeng
MIPI 2024 Challenge on Demosaic for HybridEVS Camera: Methods and Results
May 08, 2024
The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2024. In total, 170 participants were successfully registered, and 14 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2024/.
DiffSCI: Zero-Shot Snapshot Compressive Imaging via Iterative Spectral Diffusion Model
Nov 19, 2023



This paper endeavors to advance the precision of snapshot compressive imaging (SCI) reconstruction for multispectral image (MSI). To achieve this, we integrate the advantageous attributes of established SCI techniques and an image generative model, propose a novel structured zero-shot diffusion model, dubbed DiffSCI. DiffSCI leverages the structural insights from the deep prior and optimization-based methodologies, complemented by the generative capabilities offered by the contemporary denoising diffusion model. Specifically, firstly, we employ a pre-trained diffusion model, which has been trained on a substantial corpus of RGB images, as the generative denoiser within the Plug-and-Play framework for the first time. This integration allows for the successful completion of SCI reconstruction, especially in the case that current methods struggle to address effectively. Secondly, we systematically account for spectral band correlations and introduce a robust methodology to mitigate wavelength mismatch, thus enabling seamless adaptation of the RGB diffusion model to MSIs. Thirdly, an accelerated algorithm is implemented to expedite the resolution of the data subproblem. This augmentation not only accelerates the convergence rate but also elevates the quality of the reconstruction process. We present extensive testing to show that DiffSCI exhibits discernible performance enhancements over prevailing self-supervised and zero-shot approaches, surpassing even supervised transformer counterparts across both simulated and real datasets. Our code will be available.
Unsupervised Spectral Demosaicing with Lightweight Spectral Attention Networks
Jul 05, 2023
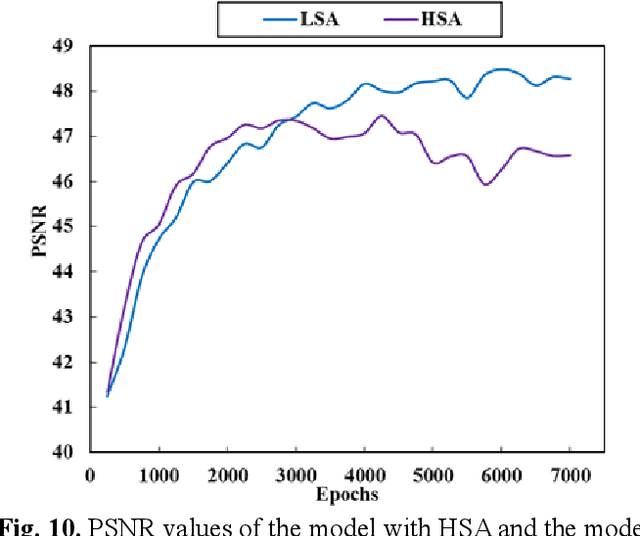
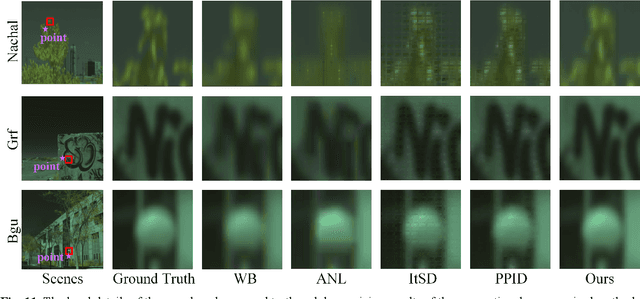
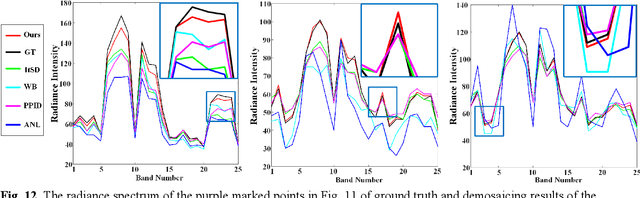
This paper presents a deep learning-based spectral demosaicing technique trained in an unsupervised manner. Many existing deep learning-based techniques relying on supervised learning with synthetic images, often underperform on real-world images especially when the number of spectral bands increases. According to the characteristics of the spectral mosaic image, this paper proposes a mosaic loss function, the corresponding model structure, a transformation strategy, and an early stopping strategy, which form a complete unsupervised spectral demosaicing framework. A challenge in real-world spectral demosaicing is inconsistency between the model parameters and the computational resources of the imager. We reduce the complexity and parameters of the spectral attention module by dividing the spectral attention tensor into spectral attention matrices in the spatial dimension and spectral attention vector in the channel dimension, which is more suitable for unsupervised framework. This paper also presents Mosaic25, a real 25-band hyperspectral mosaic image dataset of various objects, illuminations, and materials for benchmarking. Extensive experiments on synthetic and real-world datasets demonstrate that the proposed method outperforms conventional unsupervised methods in terms of spatial distortion suppression, spectral fidelity, robustness, and computational cost.
Degradation-Noise-Aware Deep Unfolding Transformer for Hyperspectral Image Denoising
May 06, 2023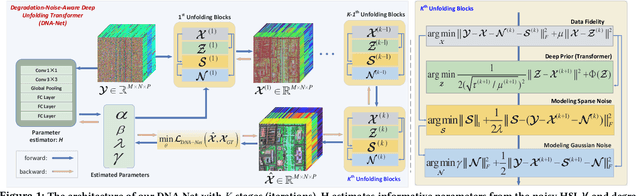
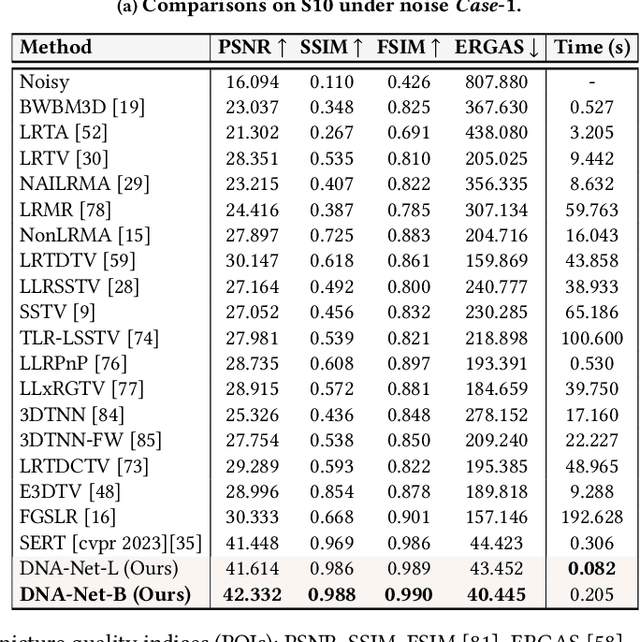
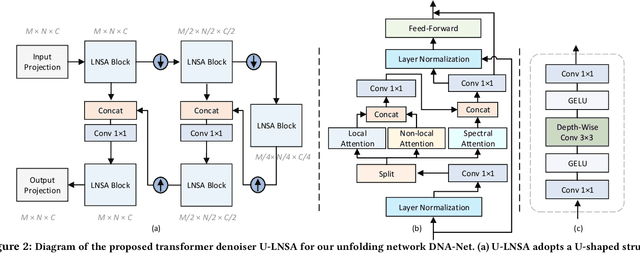
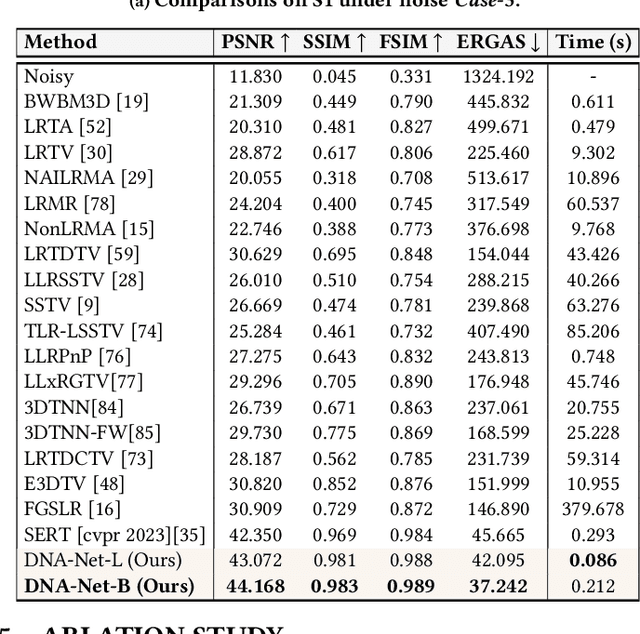
Hyperspectral imaging (HI) has emerged as a powerful tool in diverse fields such as medical diagnosis, industrial inspection, and agriculture, owing to its ability to detect subtle differences in physical properties through high spectral resolution. However, hyperspectral images (HSIs) are often quite noisy because of narrow band spectral filtering. To reduce the noise in HSI data cubes, both model-driven and learning-based denoising algorithms have been proposed. However, model-based approaches rely on hand-crafted priors and hyperparameters, while learning-based methods are incapable of estimating the inherent degradation patterns and noise distributions in the imaging procedure, which could inform supervised learning. Secondly, learning-based algorithms predominantly rely on CNN and fail to capture long-range dependencies, resulting in limited interpretability. This paper proposes a Degradation-Noise-Aware Unfolding Network (DNA-Net) that addresses these issues. Firstly, DNA-Net models sparse noise, Gaussian noise, and explicitly represent image prior using transformer. Then the model is unfolded into an end-to-end network, the hyperparameters within the model are estimated from the noisy HSI and degradation model and utilizes them to control each iteration. Additionally, we introduce a novel U-Shaped Local-Non-local-Spectral Transformer (U-LNSA) that captures spectral correlation, local contents, and non-local dependencies simultaneously. By integrating U-LNSA into DNA-Net, we present the first Transformer-based deep unfolding HSI denoising method. Experimental results show that DNA-Net outperforms state-of-the-art methods, and the modeling of noise distributions helps in cases with heavy noise.
MSFA-Frequency-Aware Transformer for Hyperspectral Images Demosaicing
Mar 23, 2023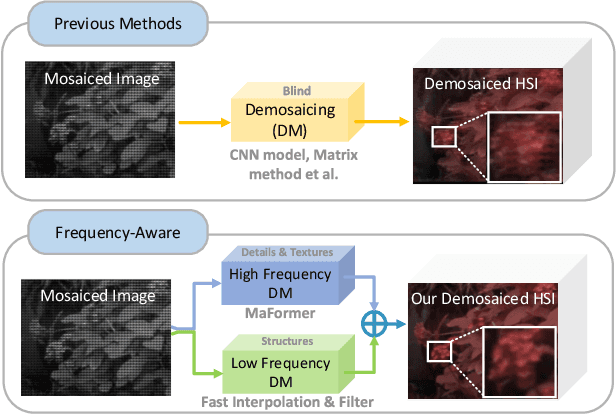
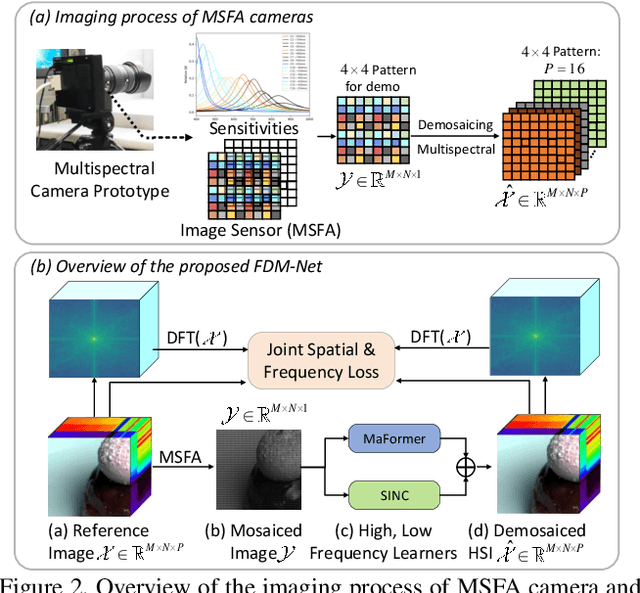


Hyperspectral imaging systems that use multispectral filter arrays (MSFA) capture only one spectral component in each pixel. Hyperspectral demosaicing is used to recover the non-measured components. While deep learning methods have shown promise in this area, they still suffer from several challenges, including limited modeling of non-local dependencies, lack of consideration of the periodic MSFA pattern that could be linked to periodic artifacts, and difficulty in recovering high-frequency details. To address these challenges, this paper proposes a novel de-mosaicing framework, the MSFA-frequency-aware Transformer network (FDM-Net). FDM-Net integrates a novel MSFA-frequency-aware multi-head self-attention mechanism (MaFormer) and a filter-based Fourier zero-padding method to reconstruct high pass components with greater difficulty and low pass components with relative ease, separately. The advantage of Maformer is that it can leverage the MSFA information and non-local dependencies present in the data. Additionally, we introduce a joint spatial and frequency loss to transfer MSFA information and enhance training on frequency components that are hard to recover. Our experimental results demonstrate that FDM-Net outperforms state-of-the-art methods with 6dB PSNR, and reconstructs high-fidelity details successfully.
Inheriting Bayer's Legacy-Joint Remosaicing and Denoising for Quad Bayer Image Sensor
Mar 23, 2023Pixel binning based Quad sensors have emerged as a promising solution to overcome the hardware limitations of compact cameras in low-light imaging. However, binning results in lower spatial resolution and non-Bayer CFA artifacts. To address these challenges, we propose a dual-head joint remosaicing and denoising network (DJRD), which enables the conversion of noisy Quad Bayer and standard noise-free Bayer pattern without any resolution loss. DJRD includes a newly designed Quad Bayer remosaicing (QB-Re) block, integrated denoising modules based on Swin-transformer and multi-scale wavelet transform. The QB-Re block constructs the convolution kernel based on the CFA pattern to achieve a periodic color distribution in the perceptual field, which is used to extract exact spectral information and reduce color misalignment. The integrated Swin-Transformer and multi-scale wavelet transform capture non-local dependencies, frequency and location information to effectively reduce practical noise. By identifying challenging patches utilizing Moire and zipper detection metrics, we enable our model to concentrate on difficult patches during the post-training phase, which enhances the model's performance in hard cases. Our proposed model outperforms competing models by approximately 3dB, without additional complexity in hardware or software.
Low-rank Meets Sparseness: An Integrated Spatial-Spectral Total Variation Approach to Hyperspectral Denoising
Apr 27, 2022



Spatial-Spectral Total Variation (SSTV) can quantify local smoothness of image structures, so it is widely used in hyperspectral image (HSI) processing tasks. Essentially, SSTV assumes a sparse structure of gradient maps calculated along the spatial and spectral directions. In fact, these gradient tensors are not only sparse, but also (approximately) low-rank under FFT, which we have verified by numerical tests and theoretical analysis. Based on this fact, we propose a novel TV regularization to simultaneously characterize the sparsity and low-rank priors of the gradient map (LRSTV). The new regularization not only imposes sparsity on the gradient map itself, but also penalize the rank on the gradient map after Fourier transform along the spectral dimension. It naturally encodes the sparsity and lowrank priors of the gradient map, and thus is expected to reflect the inherent structure of the original image more faithfully. Further, we use LRSTV to replace conventional SSTV and embed it in the HSI processing model to improve its performance. Experimental results on multiple public data-sets with heavy mixed noise show that the proposed model can get 1.5dB improvement of PSNR.
Multi-mode Core Tensor Factorization based Low-Rankness and Its Applications to Tensor Completion
Dec 03, 2020



Low-rank tensor completion has been widely used in computer vision and machine learning. This paper develops a tensor low-rank decomposition method together with a tensor low-rankness measure (MCTF) and a better nonconvex relaxation form of it (NonMCTF). This is the first method that can accurately restore the clean data of intrinsic low-rank structure based on few known inputs. This metric encodes low-rank insights for general tensors provided by Tucker and T-SVD. Furthermore, we studied the MCTF and NonMCTF regularization minimization problem, and designed an effective BSUM algorithm to solve the problem. This efficient solver can extend MCTF to various tasks, such as tensor completion and tensor robust principal component analysis. A series of experiments, including hyperspectral image (HSI) denoising, video completion and MRI restoration, confirmed the superior performance of the proposed method
Enhanced nonconvex low-rank approximation of tensor multi-modes for tensor completion
Jun 22, 2020



Higher-order low-rank tensor arises in many data processing applications and has attracted great interests. Inspired by low-rank approximation theory, researchers have proposed a series of effective tensor completion methods. However, most of these methods directly consider the global low-rankness of underlying tensors, which is not sufficient for a low sampling rate; in addition, the single nuclear norm or its relaxation is usually adopted to approximate the rank function, which would lead to suboptimal solution deviated from the original one. To alleviate the above problems, in this paper, we propose a novel low-rank approximation of tensor multi-modes (LRATM), in which a double nonconvex $L_{\gamma}$ norm is designed to represent the underlying joint-manifold drawn from the modal factorization factors of the underlying tensor. A block successive upper-bound minimization method-based algorithm is designed to efficiently solve the proposed model, and it can be demonstrated that our numerical scheme converges to the coordinatewise minimizers. Numerical results on three types of public multi-dimensional datasets have tested and shown that our algorithm can recover a variety of low-rank tensors with significantly fewer samples than the compared methods.
Hyperspectral Image Denoising via Global Spatial-Spectral Total Variation Regularized Nonconvex Local Low-Rank Tensor Approximation
May 30, 2020



Hyperspectral image (HSI) denoising aims to restore clean HSI from the noise-contaminated one. Noise contamination can often be caused during data acquisition and conversion. In this paper, we propose a novel spatial-spectral total variation (SSTV) regularized nonconvex local low-rank (LR) tensor approximation method to remove mixed noise in HSIs. From one aspect, the clean HSI data have its underlying local LR tensor property, even though the real HSI data may not be globally low-rank due to out-liers and non-Gaussian noise. According to this fact, we propose a novel tensor $L_{\gamma}$-norm to formulate the local LR prior. From another aspect, HSIs are assumed to be piecewisely smooth in the global spatial and spectral domains. Instead of traditional bandwise total variation, we use the SSTV regularization to simultaneously consider global spatial structure and spectral correlation of neighboring bands. Results on simulated and real HSI datasets indicate that the use of local LR tensor penalty and global SSTV can boost the preserving of local details and overall structural information in HSIs.