 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXueyang Fu
MIPI 2024 Challenge on Demosaic for HybridEVS Camera: Methods and Results
May 08, 2024
The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2024. In total, 170 participants were successfully registered, and 14 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2024/.
CCM: Adding Conditional Controls to Text-to-Image Consistency Models
Dec 12, 2023Consistency Models (CMs) have showed a promise in creating visual content efficiently and with high quality. However, the way to add new conditional controls to the pretrained CMs has not been explored. In this technical report, we consider alternative strategies for adding ControlNet-like conditional control to CMs and present three significant findings. 1) ControlNet trained for diffusion models (DMs) can be directly applied to CMs for high-level semantic controls but struggles with low-level detail and realism control. 2) CMs serve as an independent class of generative models, based on which ControlNet can be trained from scratch using Consistency Training proposed by Song et al. 3) A lightweight adapter can be jointly optimized under multiple conditions through Consistency Training, allowing for the swift transfer of DMs-based ControlNet to CMs. We study these three solutions across various conditional controls, including edge, depth, human pose, low-resolution image and masked image with text-to-image latent consistency models.
Decoupling Degradation and Content Processing for Adverse Weather Image Restoration
Dec 08, 2023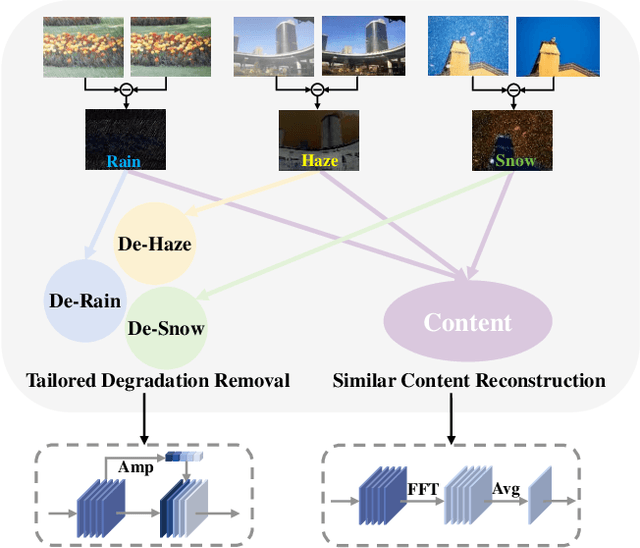
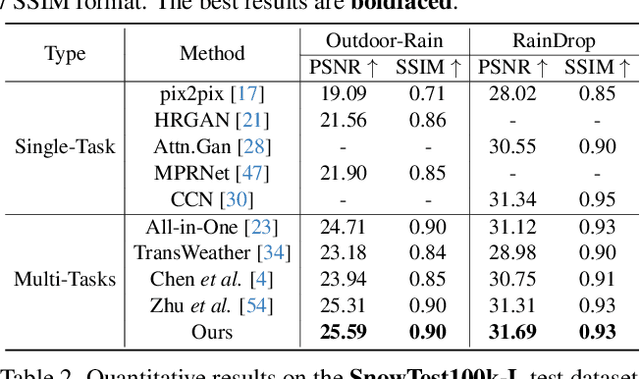
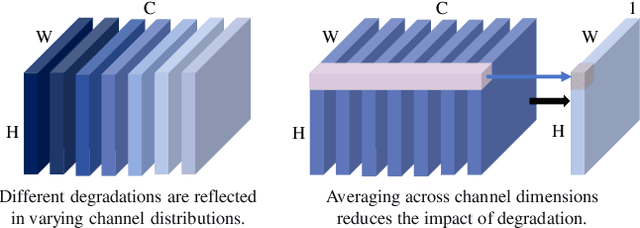
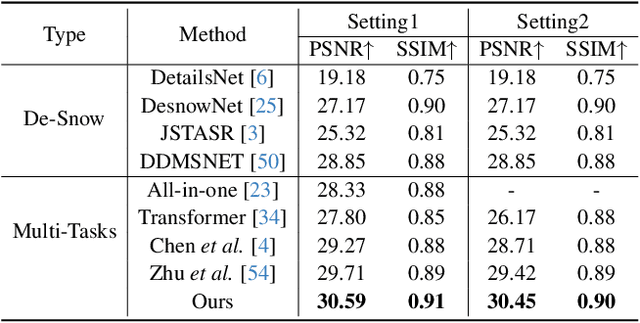
Adverse weather image restoration strives to recover clear images from those affected by various weather types, such as rain, haze, and snow. Each weather type calls for a tailored degradation removal approach due to its unique impact on images. Conversely, content reconstruction can employ a uniform approach, as the underlying image content remains consistent. Although previous techniques can handle multiple weather types within a single network, they neglect the crucial distinction between these two processes, limiting the quality of restored images. This work introduces a novel adverse weather image restoration method, called DDCNet, which decouples the degradation removal and content reconstruction process at the feature level based on their channel statistics. Specifically, we exploit the unique advantages of the Fourier transform in both these two processes: (1) the degradation information is mainly located in the amplitude component of the Fourier domain, and (2) the Fourier domain contains global information. The former facilitates channel-dependent degradation removal operation, allowing the network to tailor responses to various adverse weather types; the latter, by integrating Fourier's global properties into channel-independent content features, enhances network capacity for consistent global content reconstruction. We further augment the degradation removal process with a degradation mapping loss function. Extensive experiments demonstrate our method achieves state-of-the-art performance in multiple adverse weather removal benchmarks.
Revisiting Single Image Reflection Removal In the Wild
Nov 29, 2023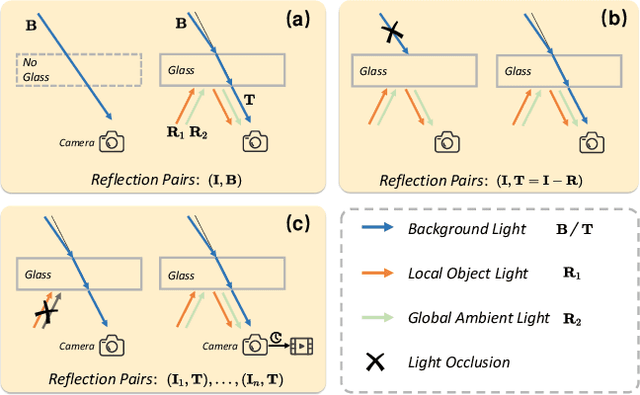
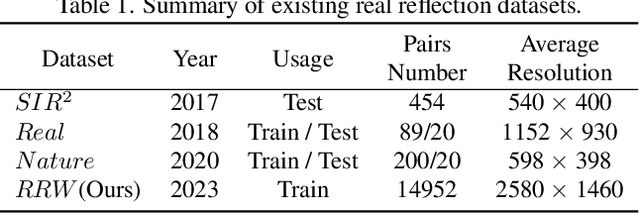

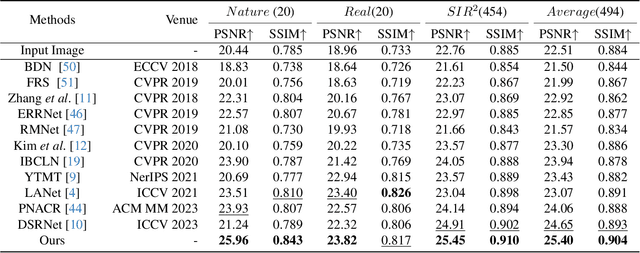
This research focuses on the issue of single-image reflection removal (SIRR) in real-world conditions, examining it from two angles: the collection pipeline of real reflection pairs and the perception of real reflection locations. We devise an advanced reflection collection pipeline that is highly adaptable to a wide range of real-world reflection scenarios and incurs reduced costs in collecting large-scale aligned reflection pairs. In the process, we develop a large-scale, high-quality reflection dataset named Reflection Removal in the Wild (RRW). RRW contains over 14,950 high-resolution real-world reflection pairs, a dataset forty-five times larger than its predecessors. Regarding perception of reflection locations, we identify that numerous virtual reflection objects visible in reflection images are not present in the corresponding ground-truth images. This observation, drawn from the aligned pairs, leads us to conceive the Maximum Reflection Filter (MaxRF). The MaxRF could accurately and explicitly characterize reflection locations from pairs of images. Building upon this, we design a reflection location-aware cascaded framework, specifically tailored for SIRR. Powered by these innovative techniques, our solution achieves superior performance than current leading methods across multiple real-world benchmarks. Codes and datasets will be publicly available.
Unfolding Taylor's Approximations for Image Restoration
Sep 08, 2021



Deep learning provides a new avenue for image restoration, which demands a delicate balance between fine-grained details and high-level contextualized information during recovering the latent clear image. In practice, however, existing methods empirically construct encapsulated end-to-end mapping networks without deepening into the rationality, and neglect the intrinsic prior knowledge of restoration task. To solve the above problems, inspired by Taylor's Approximations, we unfold Taylor's Formula to construct a novel framework for image restoration. We find the main part and the derivative part of Taylor's Approximations take the same effect as the two competing goals of high-level contextualized information and spatial details of image restoration respectively. Specifically, our framework consists of two steps, correspondingly responsible for the mapping and derivative functions. The former first learns the high-level contextualized information and the later combines it with the degraded input to progressively recover local high-order spatial details. Our proposed framework is orthogonal to existing methods and thus can be easily integrated with them for further improvement, and extensive experiments demonstrate the effectiveness and scalability of our proposed framework.
Twice Mixing: A Rank Learning based Quality Assessment Approach for Underwater Image Enhancement
Feb 01, 2021



To improve the quality of underwater images, various kinds of underwater image enhancement (UIE) operators have been proposed during the past few years. However, the lack of effective objective evaluation methods limits the further development of UIE techniques. In this paper, we propose a novel rank learning guided no-reference quality assessment method for UIE. Our approach, termed Twice Mixing, is motivated by the observation that a mid-quality image can be generated by mixing a high-quality image with its low-quality version. Typical mixup algorithms linearly interpolate a given pair of input data. However, the human visual system is non-uniformity and non-linear in processing images. Therefore, instead of directly training a deep neural network based on the mixed images and their absolute scores calculated by linear combinations, we propose to train a Siamese Network to learn their quality rankings. Twice Mixing is trained based on an elaborately formulated self-supervision mechanism. Specifically, before each iteration, we randomly generate two mixing ratios which will be employed for both generating virtual images and guiding the network training. In the test phase, a single branch of the network is extracted to predict the quality rankings of different UIE outputs. We conduct extensive experiments on both synthetic and real-world datasets. Experimental results demonstrate that our approach outperforms the previous methods significantly.
Real-world Person Re-Identification via Degradation Invariance Learning
Apr 10, 2020



Person re-identification (Re-ID) in real-world scenarios usually suffers from various degradation factors, e.g., low-resolution, weak illumination, blurring and adverse weather. On the one hand, these degradations lead to severe discriminative information loss, which significantly obstructs identity representation learning; on the other hand, the feature mismatch problem caused by low-level visual variations greatly reduces retrieval performance. An intuitive solution to this problem is to utilize low-level image restoration methods to improve the image quality. However, existing restoration methods cannot directly serve to real-world Re-ID due to various limitations, e.g., the requirements of reference samples, domain gap between synthesis and reality, and incompatibility between low-level and high-level methods. In this paper, to solve the above problem, we propose a degradation invariance learning framework for real-world person Re-ID. By introducing a self-supervised disentangled representation learning strategy, our method is able to simultaneously extract identity-related robust features and remove real-world degradations without extra supervision. We use low-resolution images as the main demonstration, and experiments show that our approach is able to achieve state-of-the-art performance on several Re-ID benchmarks. In addition, our framework can be easily extended to other real-world degradation factors, such as weak illumination, with only a few modifications.
Noise2Blur: Online Noise Extraction and Denoising
Dec 03, 2019
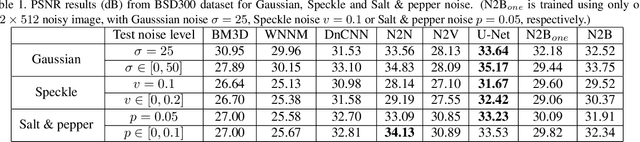
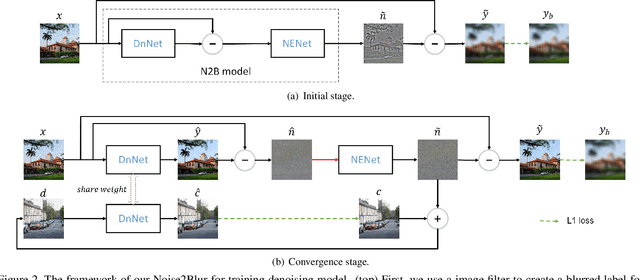
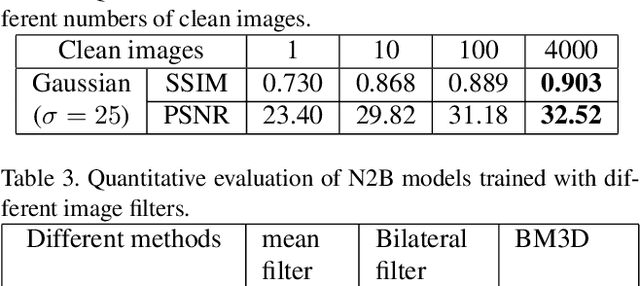
We propose a new framework called Noise2Blur (N2B) for training robust image denoising models without pre-collected paired noisy/clean images. The training of the model requires only some (or even one) noisy images, some random unpaired clean images, and noise-free but blurred labels obtained by predefined filtering of the noisy images. The N2B model consists of two parts: a denoising network and a noise extraction network. First, the noise extraction network learns to output a noise map using the noise information from the denoising network under the guidence of the blurred labels. Then, the noise map is added to a clean image to generate a new ``noisy/clean'' image pair. Using the new image pair, the denoising network learns to generate clean and high-quality images from noisy observations. These two networks are trained simultaneously and mutually aid each other to learn the mappings of noise to clean/blur. Experiments on several denoising tasks show that the denoising performance of N2B is close to that of other denoising CNNs trained with pre-collected paired data.
A^2Net: Adjacent Aggregation Networks for Image Raindrop Removal
Nov 24, 2018

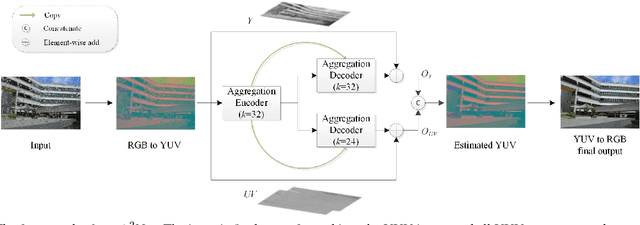

Existing methods for single images raindrop removal either have poor robustness or suffer from parameter burdens. In this paper, we propose a new Adjacent Aggregation Network (A^2Net) with lightweight architectures to remove raindrops from single images. Instead of directly cascading convolutional layers, we design an adjacent aggregation architecture to better fuse features for rich representations generation, which can lead to high quality images reconstruction. To further simplify the learning process, we utilize a problem-specific knowledge to force the network focus on the luminance channel in the YUV color space instead of all RGB channels. By combining adjacent aggregating operation with color space transformation, the proposed A^2Net can achieve state-of-the-art performances on raindrop removal with significant parameters reduction.
A Deep Tree-Structured Fusion Model for Single Image Deraining
Nov 21, 2018



We propose a simple yet effective deep tree-structured fusion model based on feature aggregation for the deraining problem. We argue that by effectively aggregating features, a relatively simple network can still handle tough image deraining problems well. First, to capture the spatial structure of rain we use dilated convolutions as our basic network block. We then design a tree-structured fusion architecture which is deployed within each block (spatial information) and across all blocks (content information). Our method is based on the assumption that adjacent features contain redundant information. This redundancy obstructs generation of new representations and can be reduced by hierarchically fusing adjacent features. Thus, the proposed model is more compact and can effectively use spatial and content information. Experiments on synthetic and real-world datasets show that our network achieves better deraining results with fewer parameters.