 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYu Liu
MoVA: Adapting Mixture of Vision Experts to Multimodal Context
Apr 19, 2024
As the key component in multimodal large language models (MLLMs), the ability of the visual encoder greatly affects MLLM's understanding on diverse image content. Although some large-scale pretrained vision encoders such as vision encoders in CLIP and DINOv2 have brought promising performance, we found that there is still no single vision encoder that can dominate various image content understanding, e.g., the CLIP vision encoder leads to outstanding results on general image understanding but poor performance on document or chart content. To alleviate the bias of CLIP vision encoder, we first delve into the inherent behavior of different pre-trained vision encoders and then propose the MoVA, a powerful and novel MLLM, adaptively routing and fusing task-specific vision experts with a coarse-to-fine mechanism. In the coarse-grained stage, we design a context-aware expert routing strategy to dynamically select the most suitable vision experts according to the user instruction, input image, and expertise of vision experts. This benefits from the powerful model function understanding ability of the large language model (LLM) equipped with expert-routing low-rank adaptation (LoRA). In the fine-grained stage, we elaborately conduct the mixture-of-vision-expert adapter (MoV-Adapter) to extract and fuse task-specific knowledge from various experts. This coarse-to-fine paradigm effectively leverages representations from experts based on multimodal context and model expertise, further enhancing the generalization ability. We conduct extensive experiments to evaluate the effectiveness of the proposed approach. Without any bells and whistles, MoVA can achieve significant performance gains over current state-of-the-art methods in a wide range of challenging multimodal benchmarks. Codes and models will be available at https://github.com/TempleX98/MoVA.
InFusion: Inpainting 3D Gaussians via Learning Depth Completion from Diffusion Prior
Apr 17, 20243D Gaussians have recently emerged as an efficient representation for novel view synthesis. This work studies its editability with a particular focus on the inpainting task, which aims to supplement an incomplete set of 3D Gaussians with additional points for visually harmonious rendering. Compared to 2D inpainting, the crux of inpainting 3D Gaussians is to figure out the rendering-relevant properties of the introduced points, whose optimization largely benefits from their initial 3D positions. To this end, we propose to guide the point initialization with an image-conditioned depth completion model, which learns to directly restore the depth map based on the observed image. Such a design allows our model to fill in depth values at an aligned scale with the original depth, and also to harness strong generalizability from largescale diffusion prior. Thanks to the more accurate depth completion, our approach, dubbed InFusion, surpasses existing alternatives with sufficiently better fidelity and efficiency under various complex scenarios. We further demonstrate the effectiveness of InFusion with several practical applications, such as inpainting with user-specific texture or with novel object insertion.
GLID: Pre-training a Generalist Encoder-Decoder Vision Model
Apr 11, 2024This paper proposes a GeneraLIst encoder-Decoder (GLID) pre-training method for better handling various downstream computer vision tasks. While self-supervised pre-training approaches, e.g., Masked Autoencoder, have shown success in transfer learning, task-specific sub-architectures are still required to be appended for different downstream tasks, which cannot enjoy the benefits of large-scale pre-training. GLID overcomes this challenge by allowing the pre-trained generalist encoder-decoder to be fine-tuned on various vision tasks with minimal task-specific architecture modifications. In the GLID training scheme, pre-training pretext task and other downstream tasks are modeled as "query-to-answer" problems, including the pre-training pretext task and other downstream tasks. We pre-train a task-agnostic encoder-decoder with query-mask pairs. During fine-tuning, GLID maintains the pre-trained encoder-decoder and queries, only replacing the topmost linear transformation layer with task-specific linear heads. This minimizes the pretrain-finetune architecture inconsistency and enables the pre-trained model to better adapt to downstream tasks. GLID achieves competitive performance on various vision tasks, including object detection, image segmentation, pose estimation, and depth estimation, outperforming or matching specialist models such as Mask2Former, DETR, ViTPose, and BinsFormer.
Rethinking the Spatial Inconsistency in Classifier-Free Diffusion Guidance
Apr 08, 2024Classifier-Free Guidance (CFG) has been widely used in text-to-image diffusion models, where the CFG scale is introduced to control the strength of text guidance on the whole image space. However, we argue that a global CFG scale results in spatial inconsistency on varying semantic strengths and suboptimal image quality. To address this problem, we present a novel approach, Semantic-aware Classifier-Free Guidance (S-CFG), to customize the guidance degrees for different semantic units in text-to-image diffusion models. Specifically, we first design a training-free semantic segmentation method to partition the latent image into relatively independent semantic regions at each denoising step. In particular, the cross-attention map in the denoising U-net backbone is renormalized for assigning each patch to the corresponding token, while the self-attention map is used to complete the semantic regions. Then, to balance the amplification of diverse semantic units, we adaptively adjust the CFG scales across different semantic regions to rescale the text guidance degrees into a uniform level. Finally, extensive experiments demonstrate the superiority of S-CFG over the original CFG strategy on various text-to-image diffusion models, without requiring any extra training cost. our codes are available at https://github.com/SmilesDZgk/S-CFG.
CoMat: Aligning Text-to-Image Diffusion Model with Image-to-Text Concept Matching
Apr 04, 2024Diffusion models have demonstrated great success in the field of text-to-image generation. However, alleviating the misalignment between the text prompts and images is still challenging. The root reason behind the misalignment has not been extensively investigated. We observe that the misalignment is caused by inadequate token attention activation. We further attribute this phenomenon to the diffusion model's insufficient condition utilization, which is caused by its training paradigm. To address the issue, we propose CoMat, an end-to-end diffusion model fine-tuning strategy with an image-to-text concept matching mechanism. We leverage an image captioning model to measure image-to-text alignment and guide the diffusion model to revisit ignored tokens. A novel attribute concentration module is also proposed to address the attribute binding problem. Without any image or human preference data, we use only 20K text prompts to fine-tune SDXL to obtain CoMat-SDXL. Extensive experiments show that CoMat-SDXL significantly outperforms the baseline model SDXL in two text-to-image alignment benchmarks and achieves start-of-the-art performance.
Genetic Quantization-Aware Approximation for Non-Linear Operations in Transformers
Mar 29, 2024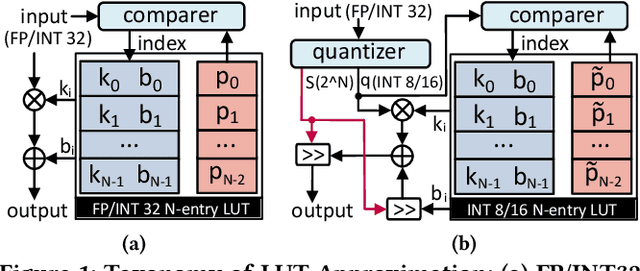
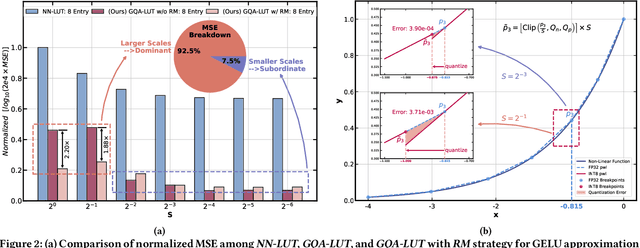

Non-linear functions are prevalent in Transformers and their lightweight variants, incurring substantial and frequently underestimated hardware costs. Previous state-of-the-art works optimize these operations by piece-wise linear approximation and store the parameters in look-up tables (LUT), but most of them require unfriendly high-precision arithmetics such as FP/INT 32 and lack consideration of integer-only INT quantization. This paper proposed a genetic LUT-Approximation algorithm namely GQA-LUT that can automatically determine the parameters with quantization awareness. The results demonstrate that GQA-LUT achieves negligible degradation on the challenging semantic segmentation task for both vanilla and linear Transformer models. Besides, proposed GQA-LUT enables the employment of INT8-based LUT-Approximation that achieves an area savings of 81.3~81.7% and a power reduction of 79.3~80.2% compared to the high-precision FP/INT 32 alternatives. Code is available at https:// github.com/PingchengDong/GQA-LUT.
FlashFace: Human Image Personalization with High-fidelity Identity Preservation
Mar 25, 2024This work presents FlashFace, a practical tool with which users can easily personalize their own photos on the fly by providing one or a few reference face images and a text prompt. Our approach is distinguishable from existing human photo customization methods by higher-fidelity identity preservation and better instruction following, benefiting from two subtle designs. First, we encode the face identity into a series of feature maps instead of one image token as in prior arts, allowing the model to retain more details of the reference faces (e.g., scars, tattoos, and face shape ). Second, we introduce a disentangled integration strategy to balance the text and image guidance during the text-to-image generation process, alleviating the conflict between the reference faces and the text prompts (e.g., personalizing an adult into a "child" or an "elder"). Extensive experimental results demonstrate the effectiveness of our method on various applications, including human image personalization, face swapping under language prompts, making virtual characters into real people, etc. Project Page: https://jshilong.github.io/flashface-page.
Visual CoT: Unleashing Chain-of-Thought Reasoning in Multi-Modal Language Models
Mar 25, 2024This paper presents Visual CoT, a novel pipeline that leverages the reasoning capabilities of multi-modal large language models (MLLMs) by incorporating visual Chain-of-Thought (CoT) reasoning. While MLLMs have shown promise in various visual tasks, they often lack interpretability and struggle with complex visual inputs. To address these challenges, we propose a multi-turn processing pipeline that dynamically focuses on visual inputs and provides interpretable thoughts. We collect and introduce the Visual CoT dataset comprising 373k question-answer pairs, annotated with intermediate bounding boxes highlighting key regions essential for answering the questions. Importantly, the introduced benchmark is capable of evaluating MLLMs in scenarios requiring specific local region identification. Extensive experiments demonstrate the effectiveness of our framework and shed light on better inference strategies. The Visual CoT dataset, benchmark, and pre-trained models are available to foster further research in this direction.
Be-Your-Outpainter: Mastering Video Outpainting through Input-Specific Adaptation
Mar 20, 2024


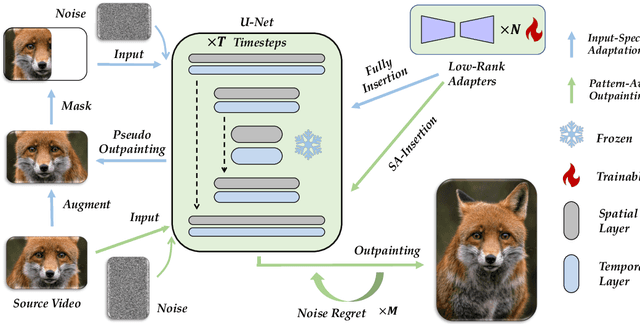
Video outpainting is a challenging task, aiming at generating video content outside the viewport of the input video while maintaining inter-frame and intra-frame consistency. Existing methods fall short in either generation quality or flexibility. We introduce MOTIA Mastering Video Outpainting Through Input-Specific Adaptation, a diffusion-based pipeline that leverages both the intrinsic data-specific patterns of the source video and the image/video generative prior for effective outpainting. MOTIA comprises two main phases: input-specific adaptation and pattern-aware outpainting. The input-specific adaptation phase involves conducting efficient and effective pseudo outpainting learning on the single-shot source video. This process encourages the model to identify and learn patterns within the source video, as well as bridging the gap between standard generative processes and outpainting. The subsequent phase, pattern-aware outpainting, is dedicated to the generalization of these learned patterns to generate outpainting outcomes. Additional strategies including spatial-aware insertion and noise travel are proposed to better leverage the diffusion model's generative prior and the acquired video patterns from source videos. Extensive evaluations underscore MOTIA's superiority, outperforming existing state-of-the-art methods in widely recognized benchmarks. Notably, these advancements are achieved without necessitating extensive, task-specific tuning.
FouriScale: A Frequency Perspective on Training-Free High-Resolution Image Synthesis
Mar 19, 2024
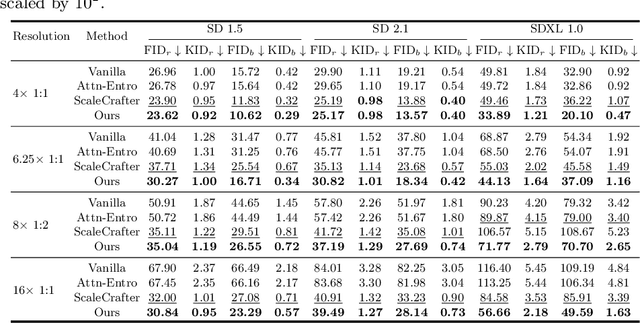
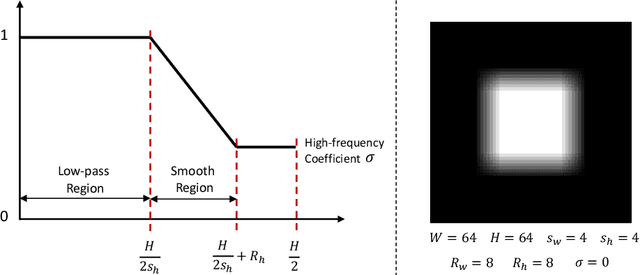

In this study, we delve into the generation of high-resolution images from pre-trained diffusion models, addressing persistent challenges, such as repetitive patterns and structural distortions, that emerge when models are applied beyond their trained resolutions. To address this issue, we introduce an innovative, training-free approach FouriScale from the perspective of frequency domain analysis. We replace the original convolutional layers in pre-trained diffusion models by incorporating a dilation technique along with a low-pass operation, intending to achieve structural consistency and scale consistency across resolutions, respectively. Further enhanced by a padding-then-crop strategy, our method can flexibly handle text-to-image generation of various aspect ratios. By using the FouriScale as guidance, our method successfully balances the structural integrity and fidelity of generated images, achieving an astonishing capacity of arbitrary-size, high-resolution, and high-quality generation. With its simplicity and compatibility, our method can provide valuable insights for future explorations into the synthesis of ultra-high-resolution images. The code will be released at https://github.com/LeonHLJ/FouriScale.