 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHongsheng Li
MoVA: Adapting Mixture of Vision Experts to Multimodal Context
Apr 19, 2024
As the key component in multimodal large language models (MLLMs), the ability of the visual encoder greatly affects MLLM's understanding on diverse image content. Although some large-scale pretrained vision encoders such as vision encoders in CLIP and DINOv2 have brought promising performance, we found that there is still no single vision encoder that can dominate various image content understanding, e.g., the CLIP vision encoder leads to outstanding results on general image understanding but poor performance on document or chart content. To alleviate the bias of CLIP vision encoder, we first delve into the inherent behavior of different pre-trained vision encoders and then propose the MoVA, a powerful and novel MLLM, adaptively routing and fusing task-specific vision experts with a coarse-to-fine mechanism. In the coarse-grained stage, we design a context-aware expert routing strategy to dynamically select the most suitable vision experts according to the user instruction, input image, and expertise of vision experts. This benefits from the powerful model function understanding ability of the large language model (LLM) equipped with expert-routing low-rank adaptation (LoRA). In the fine-grained stage, we elaborately conduct the mixture-of-vision-expert adapter (MoV-Adapter) to extract and fuse task-specific knowledge from various experts. This coarse-to-fine paradigm effectively leverages representations from experts based on multimodal context and model expertise, further enhancing the generalization ability. We conduct extensive experiments to evaluate the effectiveness of the proposed approach. Without any bells and whistles, MoVA can achieve significant performance gains over current state-of-the-art methods in a wide range of challenging multimodal benchmarks. Codes and models will be available at https://github.com/TempleX98/MoVA.
GLID: Pre-training a Generalist Encoder-Decoder Vision Model
Apr 11, 2024This paper proposes a GeneraLIst encoder-Decoder (GLID) pre-training method for better handling various downstream computer vision tasks. While self-supervised pre-training approaches, e.g., Masked Autoencoder, have shown success in transfer learning, task-specific sub-architectures are still required to be appended for different downstream tasks, which cannot enjoy the benefits of large-scale pre-training. GLID overcomes this challenge by allowing the pre-trained generalist encoder-decoder to be fine-tuned on various vision tasks with minimal task-specific architecture modifications. In the GLID training scheme, pre-training pretext task and other downstream tasks are modeled as "query-to-answer" problems, including the pre-training pretext task and other downstream tasks. We pre-train a task-agnostic encoder-decoder with query-mask pairs. During fine-tuning, GLID maintains the pre-trained encoder-decoder and queries, only replacing the topmost linear transformation layer with task-specific linear heads. This minimizes the pretrain-finetune architecture inconsistency and enables the pre-trained model to better adapt to downstream tasks. GLID achieves competitive performance on various vision tasks, including object detection, image segmentation, pose estimation, and depth estimation, outperforming or matching specialist models such as Mask2Former, DETR, ViTPose, and BinsFormer.
Urban Architect: Steerable 3D Urban Scene Generation with Layout Prior
Apr 10, 2024Text-to-3D generation has achieved remarkable success via large-scale text-to-image diffusion models. Nevertheless, there is no paradigm for scaling up the methodology to urban scale. Urban scenes, characterized by numerous elements, intricate arrangement relationships, and vast scale, present a formidable barrier to the interpretability of ambiguous textual descriptions for effective model optimization. In this work, we surmount the limitations by introducing a compositional 3D layout representation into text-to-3D paradigm, serving as an additional prior. It comprises a set of semantic primitives with simple geometric structures and explicit arrangement relationships, complementing textual descriptions and enabling steerable generation. Upon this, we propose two modifications -- (1) We introduce Layout-Guided Variational Score Distillation to address model optimization inadequacies. It conditions the score distillation sampling process with geometric and semantic constraints of 3D layouts. (2) To handle the unbounded nature of urban scenes, we represent 3D scene with a Scalable Hash Grid structure, incrementally adapting to the growing scale of urban scenes. Extensive experiments substantiate the capability of our framework to scale text-to-3D generation to large-scale urban scenes that cover over 1000m driving distance for the first time. We also present various scene editing demonstrations, showing the powers of steerable urban scene generation. Website: https://urbanarchitect.github.io.
CoMat: Aligning Text-to-Image Diffusion Model with Image-to-Text Concept Matching
Apr 04, 2024Diffusion models have demonstrated great success in the field of text-to-image generation. However, alleviating the misalignment between the text prompts and images is still challenging. The root reason behind the misalignment has not been extensively investigated. We observe that the misalignment is caused by inadequate token attention activation. We further attribute this phenomenon to the diffusion model's insufficient condition utilization, which is caused by its training paradigm. To address the issue, we propose CoMat, an end-to-end diffusion model fine-tuning strategy with an image-to-text concept matching mechanism. We leverage an image captioning model to measure image-to-text alignment and guide the diffusion model to revisit ignored tokens. A novel attribute concentration module is also proposed to address the attribute binding problem. Without any image or human preference data, we use only 20K text prompts to fine-tune SDXL to obtain CoMat-SDXL. Extensive experiments show that CoMat-SDXL significantly outperforms the baseline model SDXL in two text-to-image alignment benchmarks and achieves start-of-the-art performance.
CameraCtrl: Enabling Camera Control for Text-to-Video Generation
Apr 02, 2024Controllability plays a crucial role in video generation since it allows users to create desired content. However, existing models largely overlooked the precise control of camera pose that serves as a cinematic language to express deeper narrative nuances. To alleviate this issue, we introduce CameraCtrl, enabling accurate camera pose control for text-to-video(T2V) models. After precisely parameterizing the camera trajectory, a plug-and-play camera module is then trained on a T2V model, leaving others untouched. Additionally, a comprehensive study on the effect of various datasets is also conducted, suggesting that videos with diverse camera distribution and similar appearances indeed enhance controllability and generalization. Experimental results demonstrate the effectiveness of CameraCtrl in achieving precise and domain-adaptive camera control, marking a step forward in the pursuit of dynamic and customized video storytelling from textual and camera pose inputs. Our project website is at: https://hehao13.github.io/projects-CameraCtrl/.
Draw-and-Understand: Leveraging Visual Prompts to Enable MLLMs to Comprehend What You Want
Apr 01, 2024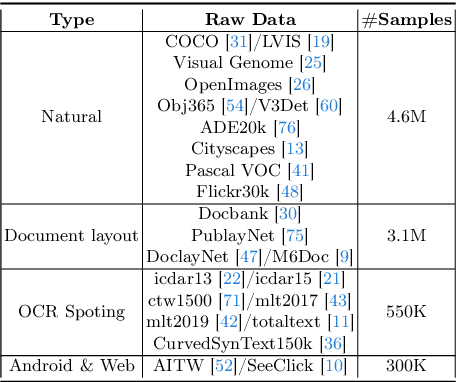
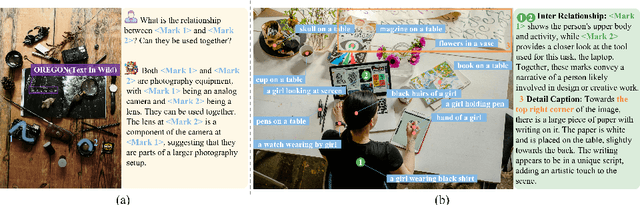
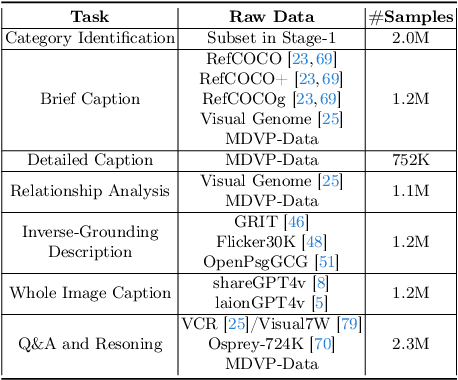
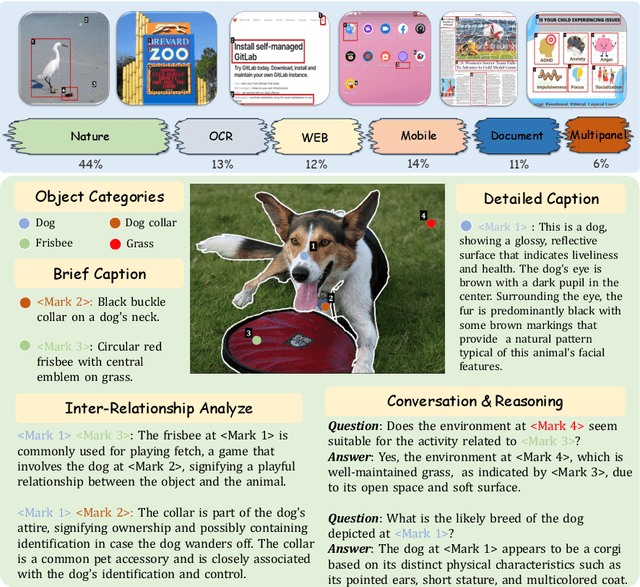
The interaction between humans and artificial intelligence (AI) is a crucial factor that reflects the effectiveness of multimodal large language models (MLLMs). However, current MLLMs primarily focus on image-level comprehension and limit interaction to textual instructions, thereby constraining their flexibility in usage and depth of response. In this paper, we introduce the Draw-and-Understand project: a new model, a multi-domain dataset, and a challenging benchmark for visual prompting. Specifically, we propose SPHINX-V, a new end-to-end trained Multimodal Large Language Model (MLLM) that connects a vision encoder, a visual prompt encoder and an LLM for various visual prompts (points, bounding boxes, and free-form shape) and language understanding. To advance visual prompting research for MLLMs, we introduce MDVP-Data and MDVP-Bench. MDVP-Data features a multi-domain dataset containing 1.6M unique image-visual prompt-text instruction-following samples, including natural images, document images, OCR images, mobile screenshots, web screenshots, and multi-panel images. Furthermore, we present MDVP-Bench, a comprehensive and challenging benchmark to assess a model's capability in understanding visual prompting instructions. Our experiments demonstrate SPHINX-V's impressive multimodal interaction capabilities through visual prompting, revealing significant improvements in detailed pixel-level description and question-answering abilities.
ECNet: Effective Controllable Text-to-Image Diffusion Models
Mar 27, 2024The conditional text-to-image diffusion models have garnered significant attention in recent years. However, the precision of these models is often compromised mainly for two reasons, ambiguous condition input and inadequate condition guidance over single denoising loss. To address the challenges, we introduce two innovative solutions. Firstly, we propose a Spatial Guidance Injector (SGI) which enhances conditional detail by encoding text inputs with precise annotation information. This method directly tackles the issue of ambiguous control inputs by providing clear, annotated guidance to the model. Secondly, to overcome the issue of limited conditional supervision, we introduce Diffusion Consistency Loss (DCL), which applies supervision on the denoised latent code at any given time step. This encourages consistency between the latent code at each time step and the input signal, thereby enhancing the robustness and accuracy of the output. The combination of SGI and DCL results in our Effective Controllable Network (ECNet), which offers a more accurate controllable end-to-end text-to-image generation framework with a more precise conditioning input and stronger controllable supervision. We validate our approach through extensive experiments on generation under various conditions, such as human body skeletons, facial landmarks, and sketches of general objects. The results consistently demonstrate that our method significantly enhances the controllability and robustness of the generated images, outperforming existing state-of-the-art controllable text-to-image models.
Visual CoT: Unleashing Chain-of-Thought Reasoning in Multi-Modal Language Models
Mar 25, 2024This paper presents Visual CoT, a novel pipeline that leverages the reasoning capabilities of multi-modal large language models (MLLMs) by incorporating visual Chain-of-Thought (CoT) reasoning. While MLLMs have shown promise in various visual tasks, they often lack interpretability and struggle with complex visual inputs. To address these challenges, we propose a multi-turn processing pipeline that dynamically focuses on visual inputs and provides interpretable thoughts. We collect and introduce the Visual CoT dataset comprising 373k question-answer pairs, annotated with intermediate bounding boxes highlighting key regions essential for answering the questions. Importantly, the introduced benchmark is capable of evaluating MLLMs in scenarios requiring specific local region identification. Extensive experiments demonstrate the effectiveness of our framework and shed light on better inference strategies. The Visual CoT dataset, benchmark, and pre-trained models are available to foster further research in this direction.
MathVerse: Does Your Multi-modal LLM Truly See the Diagrams in Visual Math Problems?
Mar 21, 2024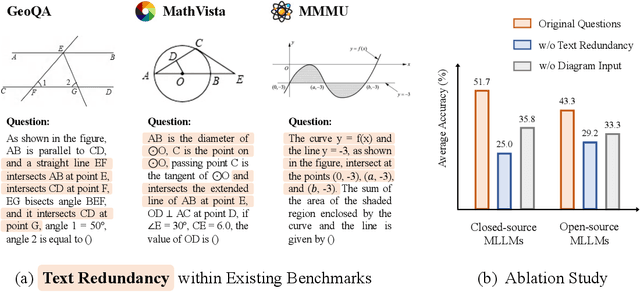

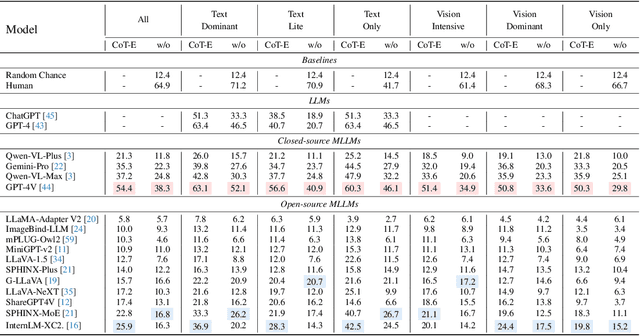
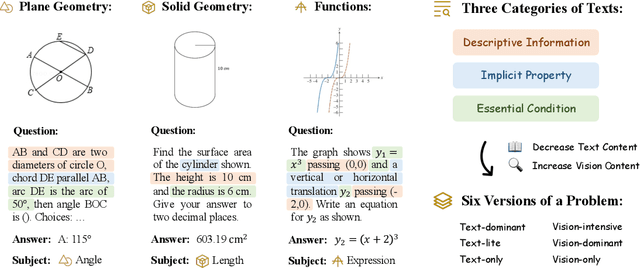
The remarkable progress of Multi-modal Large Language Models (MLLMs) has garnered unparalleled attention, due to their superior performance in visual contexts. However, their capabilities in visual math problem-solving remain insufficiently evaluated and understood. We investigate current benchmarks to incorporate excessive visual content within textual questions, which potentially assist MLLMs in deducing answers without truly interpreting the input diagrams. To this end, we introduce MathVerse, an all-around visual math benchmark designed for an equitable and in-depth evaluation of MLLMs. We meticulously collect 2,612 high-quality, multi-subject math problems with diagrams from publicly available sources. Each problem is then transformed by human annotators into six distinct versions, each offering varying degrees of information content in multi-modality, contributing to 15K test samples in total. This approach allows MathVerse to comprehensively assess whether and how much MLLMs can truly understand the visual diagrams for mathematical reasoning. In addition, we propose a Chain-of-Thought (CoT) evaluation strategy for a fine-grained assessment of the output answers. Rather than naively judging True or False, we employ GPT-4(V) to adaptively extract crucial reasoning steps, and then score each step with detailed error analysis, which can reveal the intermediate CoT reasoning quality by MLLMs. We hope the MathVerse benchmark may provide unique insights to guide the future development of MLLMs. Project page: https://mathverse-cuhk.github.io
Be-Your-Outpainter: Mastering Video Outpainting through Input-Specific Adaptation
Mar 20, 2024


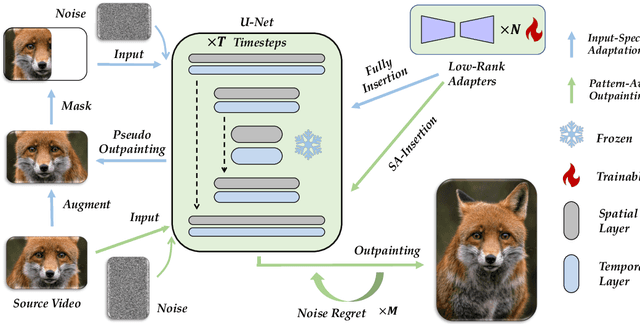
Video outpainting is a challenging task, aiming at generating video content outside the viewport of the input video while maintaining inter-frame and intra-frame consistency. Existing methods fall short in either generation quality or flexibility. We introduce MOTIA Mastering Video Outpainting Through Input-Specific Adaptation, a diffusion-based pipeline that leverages both the intrinsic data-specific patterns of the source video and the image/video generative prior for effective outpainting. MOTIA comprises two main phases: input-specific adaptation and pattern-aware outpainting. The input-specific adaptation phase involves conducting efficient and effective pseudo outpainting learning on the single-shot source video. This process encourages the model to identify and learn patterns within the source video, as well as bridging the gap between standard generative processes and outpainting. The subsequent phase, pattern-aware outpainting, is dedicated to the generalization of these learned patterns to generate outpainting outcomes. Additional strategies including spatial-aware insertion and noise travel are proposed to better leverage the diffusion model's generative prior and the acquired video patterns from source videos. Extensive evaluations underscore MOTIA's superiority, outperforming existing state-of-the-art methods in widely recognized benchmarks. Notably, these advancements are achieved without necessitating extensive, task-specific tuning.