 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChangjun Jiang
Urban Architect: Steerable 3D Urban Scene Generation with Layout Prior
Apr 10, 2024
Text-to-3D generation has achieved remarkable success via large-scale text-to-image diffusion models. Nevertheless, there is no paradigm for scaling up the methodology to urban scale. Urban scenes, characterized by numerous elements, intricate arrangement relationships, and vast scale, present a formidable barrier to the interpretability of ambiguous textual descriptions for effective model optimization. In this work, we surmount the limitations by introducing a compositional 3D layout representation into text-to-3D paradigm, serving as an additional prior. It comprises a set of semantic primitives with simple geometric structures and explicit arrangement relationships, complementing textual descriptions and enabling steerable generation. Upon this, we propose two modifications -- (1) We introduce Layout-Guided Variational Score Distillation to address model optimization inadequacies. It conditions the score distillation sampling process with geometric and semantic constraints of 3D layouts. (2) To handle the unbounded nature of urban scenes, we represent 3D scene with a Scalable Hash Grid structure, incrementally adapting to the growing scale of urban scenes. Extensive experiments substantiate the capability of our framework to scale text-to-3D generation to large-scale urban scenes that cover over 1000m driving distance for the first time. We also present various scene editing demonstrations, showing the powers of steerable urban scene generation. Website: https://urbanarchitect.github.io.
LiDAR4D: Dynamic Neural Fields for Novel Space-time View LiDAR Synthesis
Apr 03, 2024Although neural radiance fields (NeRFs) have achieved triumphs in image novel view synthesis (NVS), LiDAR NVS remains largely unexplored. Previous LiDAR NVS methods employ a simple shift from image NVS methods while ignoring the dynamic nature and the large-scale reconstruction problem of LiDAR point clouds. In light of this, we propose LiDAR4D, a differentiable LiDAR-only framework for novel space-time LiDAR view synthesis. In consideration of the sparsity and large-scale characteristics, we design a 4D hybrid representation combined with multi-planar and grid features to achieve effective reconstruction in a coarse-to-fine manner. Furthermore, we introduce geometric constraints derived from point clouds to improve temporal consistency. For the realistic synthesis of LiDAR point clouds, we incorporate the global optimization of ray-drop probability to preserve cross-region patterns. Extensive experiments on KITTI-360 and NuScenes datasets demonstrate the superiority of our method in accomplishing geometry-aware and time-consistent dynamic reconstruction. Codes are available at https://github.com/ispc-lab/LiDAR4D.
Pensieve: Retrospect-then-Compare Mitigates Visual Hallucination
Mar 21, 2024
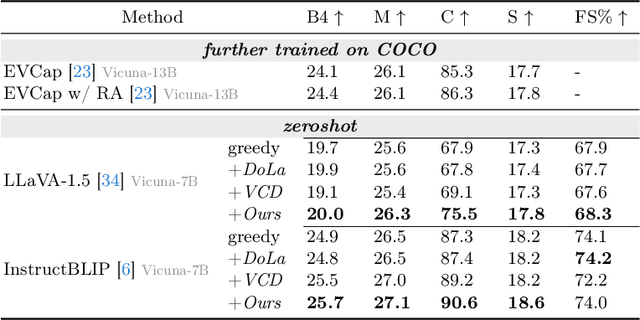
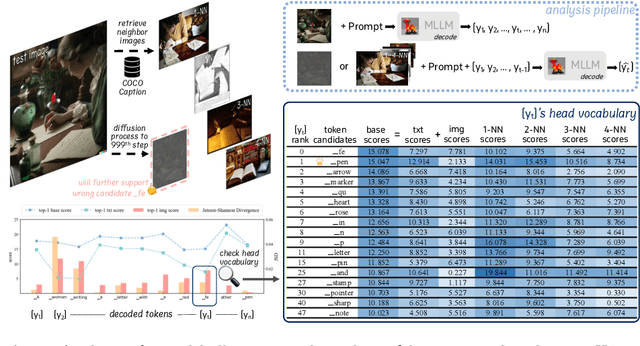
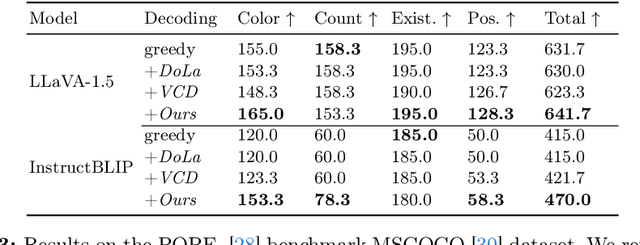
Multi-modal Large Language Models (MLLMs) demonstrate remarkable success across various vision-language tasks. However, they suffer from visual hallucination, where the generated responses diverge from the provided image. Are MLLMs completely oblivious to accurate visual cues when they hallucinate? Our investigation reveals that the visual branch may simultaneously advocate both accurate and non-existent content. To address this issue, we propose Pensieve, a training-free method inspired by our observation that analogous visual hallucinations can arise among images sharing common semantic and appearance characteristics. During inference, Pensieve enables MLLMs to retrospect relevant images as references and compare them with the test image. This paradigm assists MLLMs in downgrading hallucinatory content mistakenly supported by the visual input. Experiments on Whoops, MME, POPE, and LLaVA Bench demonstrate the efficacy of Pensieve in mitigating visual hallucination, surpassing other advanced decoding strategies. Additionally, Pensieve aids MLLMs in identifying details in the image and enhancing the specificity of image descriptions.
GLC++: Source-Free Universal Domain Adaptation through Global-Local Clustering and Contrastive Affinity Learning
Mar 21, 2024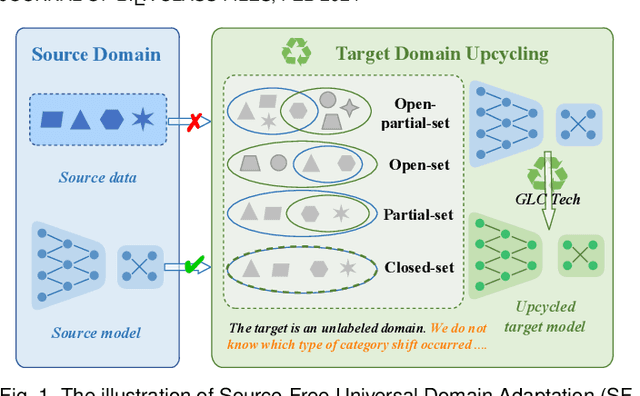
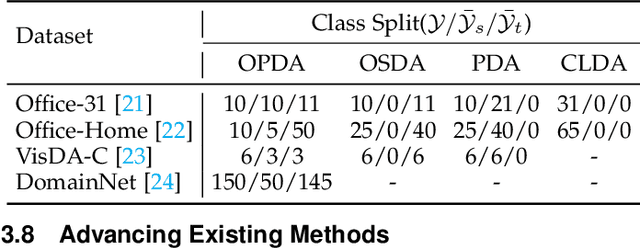
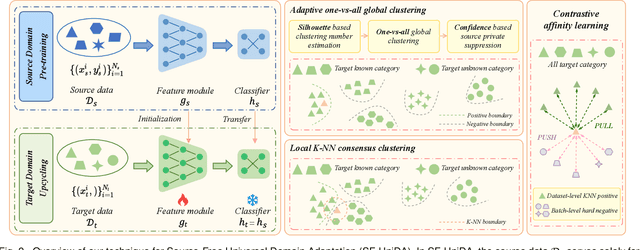
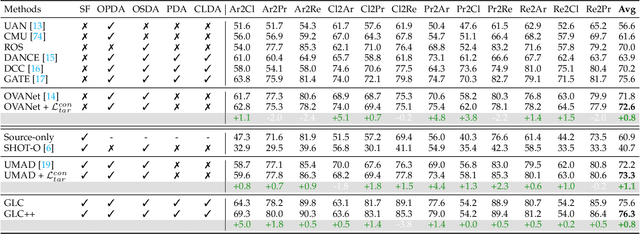
Deep neural networks often exhibit sub-optimal performance under covariate and category shifts. Source-Free Domain Adaptation (SFDA) presents a promising solution to this dilemma, yet most SFDA approaches are restricted to closed-set scenarios. In this paper, we explore Source-Free Universal Domain Adaptation (SF-UniDA) aiming to accurately classify "known" data belonging to common categories and segregate them from target-private "unknown" data. We propose a novel Global and Local Clustering (GLC) technique, which comprises an adaptive one-vs-all global clustering algorithm to discern between target classes, complemented by a local k-NN clustering strategy to mitigate negative transfer. Despite the effectiveness, the inherent closed-set source architecture leads to uniform treatment of "unknown" data, impeding the identification of distinct "unknown" categories. To address this, we evolve GLC to GLC++, integrating a contrastive affinity learning strategy. We examine the superiority of GLC and GLC++ across multiple benchmarks and category shift scenarios. Remarkably, in the most challenging open-partial-set scenarios, GLC and GLC++ surpass GATE by 16.7% and 18.6% in H-score on VisDA, respectively. GLC++ enhances the novel category clustering accuracy of GLC by 4.3% in open-set scenarios on Office-Home. Furthermore, the introduced contrastive learning strategy not only enhances GLC but also significantly facilitates existing methodologies.
LEAD: Learning Decomposition for Source-free Universal Domain Adaptation
Mar 06, 2024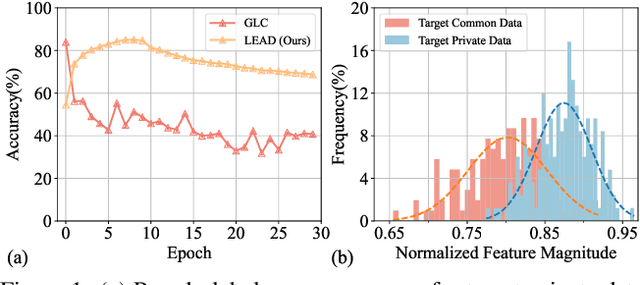

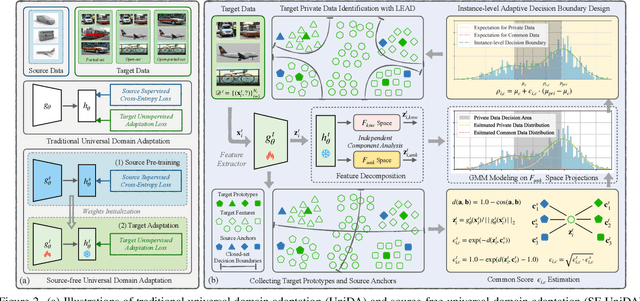
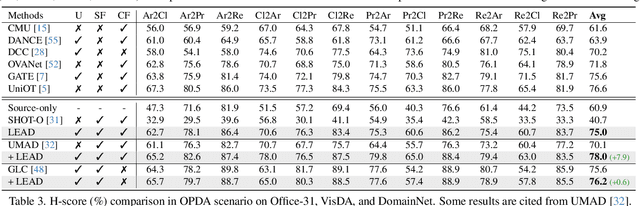
Universal Domain Adaptation (UniDA) targets knowledge transfer in the presence of both covariate and label shifts. Recently, Source-free Universal Domain Adaptation (SF-UniDA) has emerged to achieve UniDA without access to source data, which tends to be more practical due to data protection policies. The main challenge lies in determining whether covariate-shifted samples belong to target-private unknown categories. Existing methods tackle this either through hand-crafted thresholding or by developing time-consuming iterative clustering strategies. In this paper, we propose a new idea of LEArning Decomposition (LEAD), which decouples features into source-known and -unknown components to identify target-private data. Technically, LEAD initially leverages the orthogonal decomposition analysis for feature decomposition. Then, LEAD builds instance-level decision boundaries to adaptively identify target-private data. Extensive experiments across various UniDA scenarios have demonstrated the effectiveness and superiority of LEAD. Notably, in the OPDA scenario on VisDA dataset, LEAD outperforms GLC by 3.5% overall H-score and reduces 75% time to derive pseudo-labeling decision boundaries. Besides, LEAD is also appealing in that it is complementary to most existing methods. The code is available at https://github.com/ispc-lab/LEAD.
Spreeze: High-Throughput Parallel Reinforcement Learning Framework
Dec 11, 2023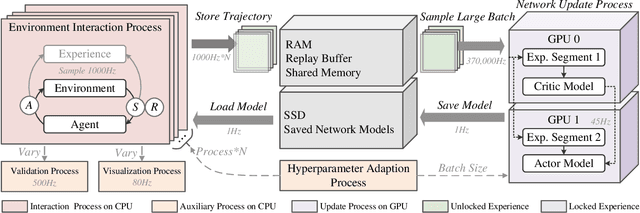


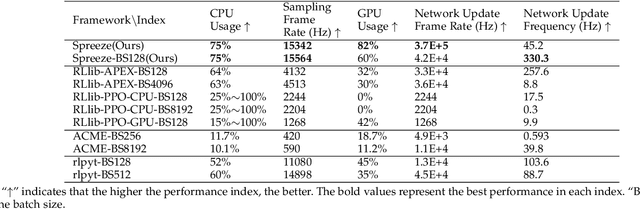
The promotion of large-scale applications of reinforcement learning (RL) requires efficient training computation. While existing parallel RL frameworks encompass a variety of RL algorithms and parallelization techniques, the excessively burdensome communication frameworks hinder the attainment of the hardware's limit for final throughput and training effects on a single desktop. In this paper, we propose Spreeze, a lightweight parallel framework for RL that efficiently utilizes a single desktop hardware resource to approach the throughput limit. We asynchronously parallelize the experience sampling, network update, performance evaluation, and visualization operations, and employ multiple efficient data transmission techniques to transfer various types of data between processes. The framework can automatically adjust the parallelization hyperparameters based on the computing ability of the hardware device in order to perform efficient large-batch updates. Based on the characteristics of the "Actor-Critic" RL algorithm, our framework uses dual GPUs to independently update the network of actors and critics in order to further improve throughput. Simulation results show that our framework can achieve up to 15,000Hz experience sampling and 370,000Hz network update frame rate using only a personal desktop computer, which is an order of magnitude higher than other mainstream parallel RL frameworks, resulting in a 73% reduction of training time. Our work on fully utilizing the hardware resources of a single desktop computer is fundamental to enabling efficient large-scale distributed RL training.
CFBenchmark: Chinese Financial Assistant Benchmark for Large Language Model
Nov 10, 2023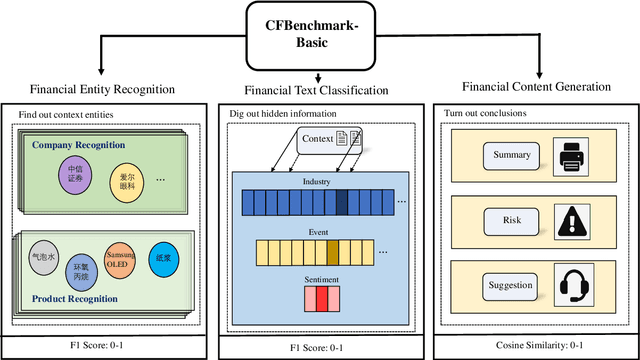
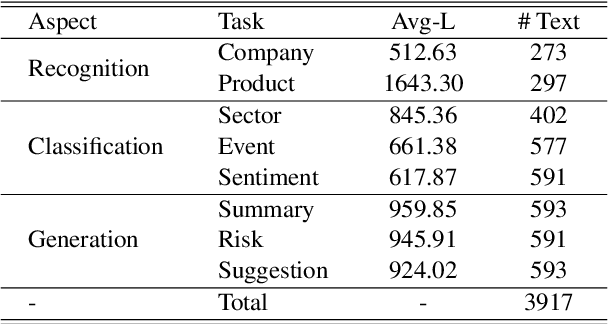

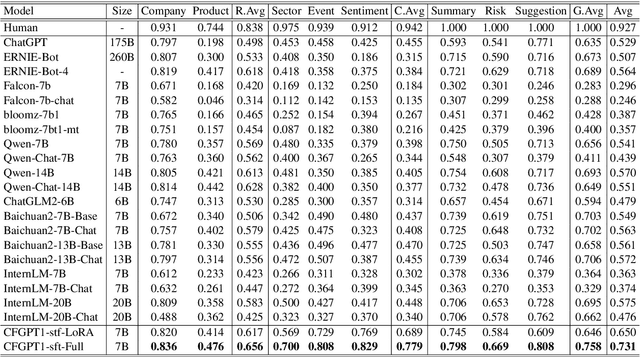
Large language models (LLMs) have demonstrated great potential in the financial domain. Thus, it becomes important to assess the performance of LLMs in the financial tasks. In this work, we introduce CFBenchmark, to evaluate the performance of LLMs for Chinese financial assistant. The basic version of CFBenchmark is designed to evaluate the basic ability in Chinese financial text processing from three aspects~(\emph{i.e.} recognition, classification, and generation) including eight tasks, and includes financial texts ranging in length from 50 to over 1,800 characters. We conduct experiments on several LLMs available in the literature with CFBenchmark-Basic, and the experimental results indicate that while some LLMs show outstanding performance in specific tasks, overall, there is still significant room for improvement in basic tasks of financial text processing with existing models. In the future, we plan to explore the advanced version of CFBenchmark, aiming to further explore the extensive capabilities of language models in more profound dimensions as a financial assistant in Chinese. Our codes are released at https://github.com/TongjiFinLab/CFBenchmark.
CFGPT: Chinese Financial Assistant with Large Language Model
Sep 22, 2023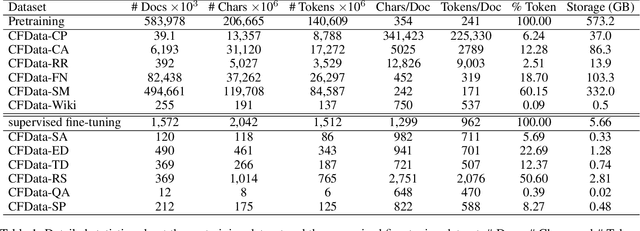
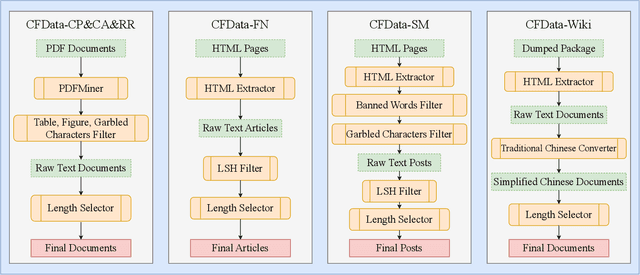

Large language models (LLMs) have demonstrated great potential in natural language processing tasks within the financial domain. In this work, we present a Chinese Financial Generative Pre-trained Transformer framework, named CFGPT, which includes a dataset~(CFData) for pre-training and supervised fine-tuning, a financial LLM~(CFLLM) to adeptly manage financial texts, and a deployment framework~(CFAPP) designed to navigate real-world financial applications. The CFData comprising both a pre-training dataset and a supervised fine-tuning dataset, where the pre-training dataset collates Chinese financial data and analytics, alongside a smaller subset of general-purpose text with 584M documents and 141B tokens in total, and the supervised fine-tuning dataset is tailored for six distinct financial tasks, embodying various facets of financial analysis and decision-making with 1.5M instruction pairs and 1.5B tokens in total. The CFLLM, which is based on InternLM-7B to balance the model capability and size, is trained on CFData in two stage, continued pre-training and supervised fine-tuning. The CFAPP is centered on large language models (LLMs) and augmented with additional modules to ensure multifaceted functionality in real-world application. Our codes are released at https://github.com/TongjiFinLab/CFGPT.
Urban Radiance Field Representation with Deformable Neural Mesh Primitives
Jul 20, 2023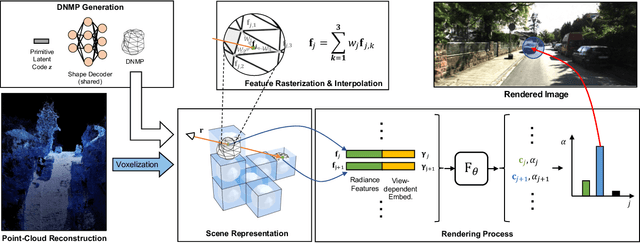
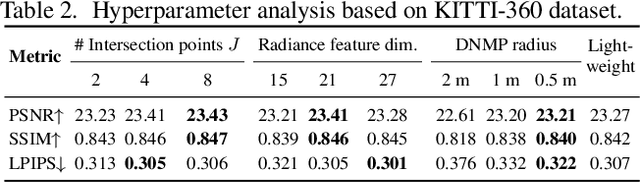


Neural Radiance Fields (NeRFs) have achieved great success in the past few years. However, most current methods still require intensive resources due to ray marching-based rendering. To construct urban-level radiance fields efficiently, we design Deformable Neural Mesh Primitive~(DNMP), and propose to parameterize the entire scene with such primitives. The DNMP is a flexible and compact neural variant of classic mesh representation, which enjoys both the efficiency of rasterization-based rendering and the powerful neural representation capability for photo-realistic image synthesis. Specifically, a DNMP consists of a set of connected deformable mesh vertices with paired vertex features to parameterize the geometry and radiance information of a local area. To constrain the degree of freedom for optimization and lower the storage budgets, we enforce the shape of each primitive to be decoded from a relatively low-dimensional latent space. The rendering colors are decoded from the vertex features (interpolated with rasterization) by a view-dependent MLP. The DNMP provides a new paradigm for urban-level scene representation with appealing properties: $(1)$ High-quality rendering. Our method achieves leading performance for novel view synthesis in urban scenarios. $(2)$ Low computational costs. Our representation enables fast rendering (2.07ms/1k pixels) and low peak memory usage (110MB/1k pixels). We also present a lightweight version that can run 33$\times$ faster than vanilla NeRFs, and comparable to the highly-optimized Instant-NGP (0.61 vs 0.71ms/1k pixels). Project page: \href{https://dnmp.github.io/}{https://dnmp.github.io/}.
NeuralPCI: Spatio-temporal Neural Field for 3D Point Cloud Multi-frame Non-linear Interpolation
Mar 27, 2023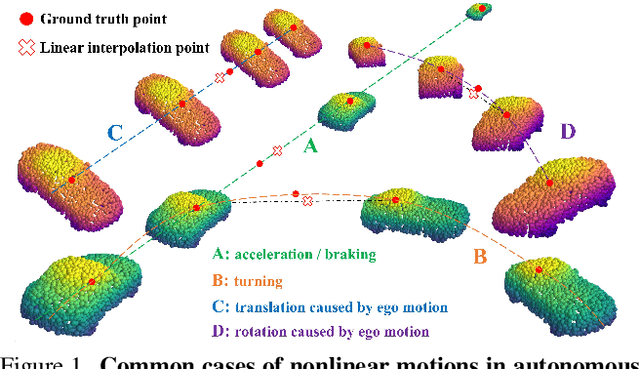

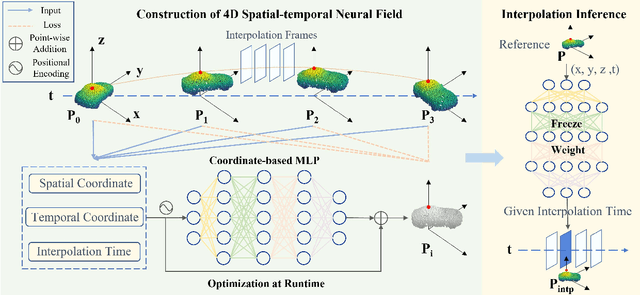
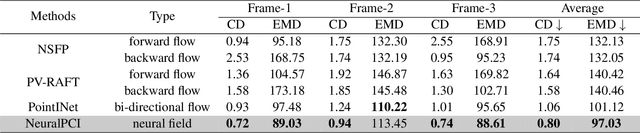
In recent years, there has been a significant increase in focus on the interpolation task of computer vision. Despite the tremendous advancement of video interpolation, point cloud interpolation remains insufficiently explored. Meanwhile, the existence of numerous nonlinear large motions in real-world scenarios makes the point cloud interpolation task more challenging. In light of these issues, we present NeuralPCI: an end-to-end 4D spatio-temporal Neural field for 3D Point Cloud Interpolation, which implicitly integrates multi-frame information to handle nonlinear large motions for both indoor and outdoor scenarios. Furthermore, we construct a new multi-frame point cloud interpolation dataset called NL-Drive for large nonlinear motions in autonomous driving scenes to better demonstrate the superiority of our method. Ultimately, NeuralPCI achieves state-of-the-art performance on both DHB (Dynamic Human Bodies) and NL-Drive datasets. Beyond the interpolation task, our method can be naturally extended to point cloud extrapolation, morphing, and auto-labeling, which indicates its substantial potential in other domains. Codes are available at https://github.com/ispc-lab/NeuralPCI.