 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJihao Liu
GLID: Pre-training a Generalist Encoder-Decoder Vision Model
Apr 11, 2024
This paper proposes a GeneraLIst encoder-Decoder (GLID) pre-training method for better handling various downstream computer vision tasks. While self-supervised pre-training approaches, e.g., Masked Autoencoder, have shown success in transfer learning, task-specific sub-architectures are still required to be appended for different downstream tasks, which cannot enjoy the benefits of large-scale pre-training. GLID overcomes this challenge by allowing the pre-trained generalist encoder-decoder to be fine-tuned on various vision tasks with minimal task-specific architecture modifications. In the GLID training scheme, pre-training pretext task and other downstream tasks are modeled as "query-to-answer" problems, including the pre-training pretext task and other downstream tasks. We pre-train a task-agnostic encoder-decoder with query-mask pairs. During fine-tuning, GLID maintains the pre-trained encoder-decoder and queries, only replacing the topmost linear transformation layer with task-specific linear heads. This minimizes the pretrain-finetune architecture inconsistency and enables the pre-trained model to better adapt to downstream tasks. GLID achieves competitive performance on various vision tasks, including object detection, image segmentation, pose estimation, and depth estimation, outperforming or matching specialist models such as Mask2Former, DETR, ViTPose, and BinsFormer.
DecisionNCE: Embodied Multimodal Representations via Implicit Preference Learning
Feb 28, 2024Multimodal pretraining has emerged as an effective strategy for the trinity of goals of representation learning in autonomous robots: 1) extracting both local and global task progression information; 2) enforcing temporal consistency of visual representation; 3) capturing trajectory-level language grounding. Most existing methods approach these via separate objectives, which often reach sub-optimal solutions. In this paper, we propose a universal unified objective that can simultaneously extract meaningful task progression information from image sequences and seamlessly align them with language instructions. We discover that via implicit preferences, where a visual trajectory inherently aligns better with its corresponding language instruction than mismatched pairs, the popular Bradley-Terry model can transform into representation learning through proper reward reparameterizations. The resulted framework, DecisionNCE, mirrors an InfoNCE-style objective but is distinctively tailored for decision-making tasks, providing an embodied representation learning framework that elegantly extracts both local and global task progression features, with temporal consistency enforced through implicit time contrastive learning, while ensuring trajectory-level instruction grounding via multimodal joint encoding. Evaluation on both simulated and real robots demonstrates that DecisionNCE effectively facilitates diverse downstream policy learning tasks, offering a versatile solution for unified representation and reward learning. Project Page: https://2toinf.github.io/DecisionNCE/
Towards Better 3D Knowledge Transfer via Masked Image Modeling for Multi-view 3D Understanding
Mar 20, 2023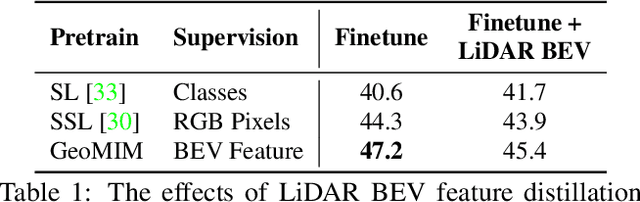
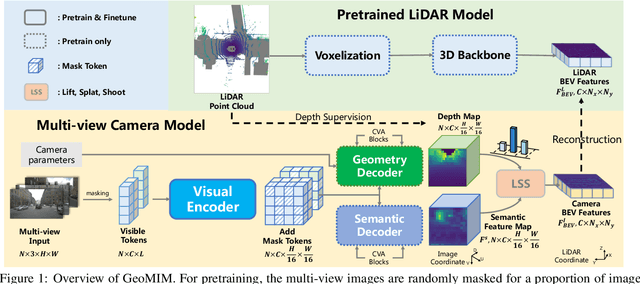

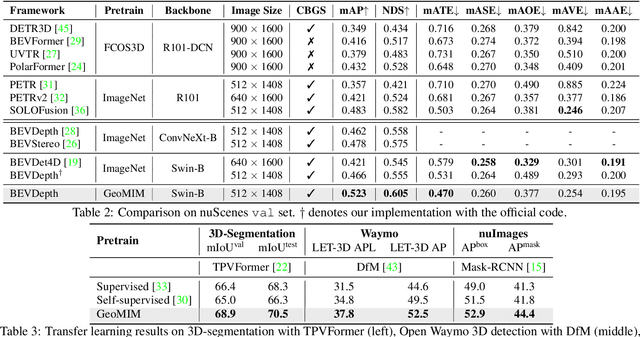
Multi-view camera-based 3D detection is a challenging problem in computer vision. Recent works leverage a pretrained LiDAR detection model to transfer knowledge to a camera-based student network. However, we argue that there is a major domain gap between the LiDAR BEV features and the camera-based BEV features, as they have different characteristics and are derived from different sources. In this paper, we propose Geometry Enhanced Masked Image Modeling (GeoMIM) to transfer the knowledge of the LiDAR model in a pretrain-finetune paradigm for improving the multi-view camera-based 3D detection. GeoMIM is a multi-camera vision transformer with Cross-View Attention (CVA) blocks that uses LiDAR BEV features encoded by the pretrained BEV model as learning targets. During pretraining, GeoMIM's decoder has a semantic branch completing dense perspective-view features and the other geometry branch reconstructing dense perspective-view depth maps. The depth branch is designed to be camera-aware by inputting the camera's parameters for better transfer capability. Extensive results demonstrate that GeoMIM outperforms existing methods on nuScenes benchmark, achieving state-of-the-art performance for camera-based 3D object detection and 3D segmentation.
TokenMix: Rethinking Image Mixing for Data Augmentation in Vision Transformers
Jul 18, 2022
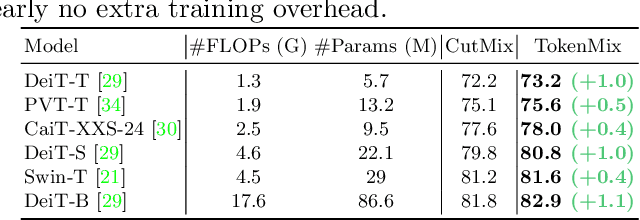
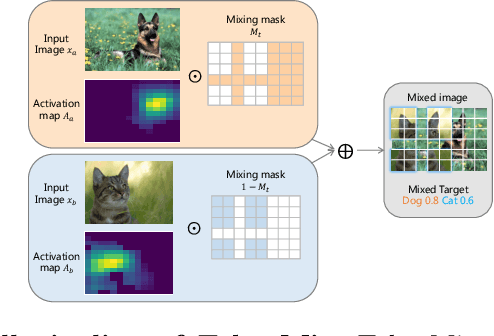

CutMix is a popular augmentation technique commonly used for training modern convolutional and transformer vision networks. It was originally designed to encourage Convolution Neural Networks (CNNs) to focus more on an image's global context instead of local information, which greatly improves the performance of CNNs. However, we found it to have limited benefits for transformer-based architectures that naturally have a global receptive field. In this paper, we propose a novel data augmentation technique TokenMix to improve the performance of vision transformers. TokenMix mixes two images at token level via partitioning the mixing region into multiple separated parts. Besides, we show that the mixed learning target in CutMix, a linear combination of a pair of the ground truth labels, might be inaccurate and sometimes counter-intuitive. To obtain a more suitable target, we propose to assign the target score according to the content-based neural activation maps of the two images from a pre-trained teacher model, which does not need to have high performance. With plenty of experiments on various vision transformer architectures, we show that our proposed TokenMix helps vision transformers focus on the foreground area to infer the classes and enhances their robustness to occlusion, with consistent performance gains. Notably, we improve DeiT-T/S/B with +1% ImageNet top-1 accuracy. Besides, TokenMix enjoys longer training, which achieves 81.2% top-1 accuracy on ImageNet with DeiT-S trained for 400 epochs. Code is available at https://github.com/Sense-X/TokenMix.
UniNet: Unified Architecture Search with Convolution, Transformer, and MLP
Jul 12, 2022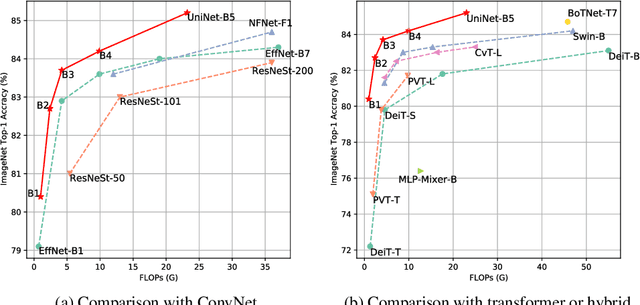
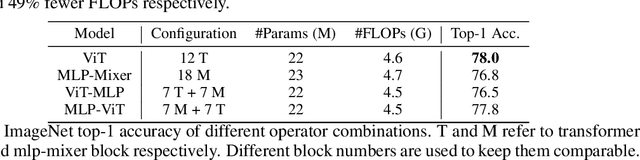

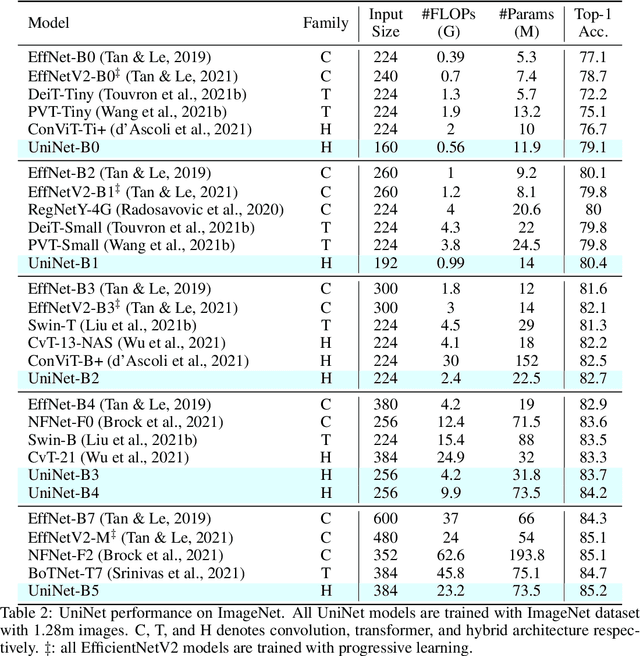
Recently, transformer and multi-layer perceptron (MLP) architectures have achieved impressive results on various vision tasks. However, how to effectively combine those operators to form high-performance hybrid visual architectures still remains a challenge. In this work, we study the learnable combination of convolution, transformer, and MLP by proposing a novel unified architecture search approach. Our approach contains two key designs to achieve the search for high-performance networks. First, we model the very different searchable operators in a unified form, and thus enable the operators to be characterized with the same set of configuration parameters. In this way, the overall search space size is significantly reduced, and the total search cost becomes affordable. Second, we propose context-aware downsampling modules (DSMs) to mitigate the gap between the different types of operators. Our proposed DSMs are able to better adapt features from different types of operators, which is important for identifying high-performance hybrid architectures. Finally, we integrate configurable operators and DSMs into a unified search space and search with a Reinforcement Learning-based search algorithm to fully explore the optimal combination of the operators. To this end, we search a baseline network and scale it up to obtain a family of models, named UniNets, which achieve much better accuracy and efficiency than previous ConvNets and Transformers. In particular, our UniNet-B5 achieves 84.9% top-1 accuracy on ImageNet, outperforming EfficientNet-B7 and BoTNet-T7 with 44% and 55% fewer FLOPs respectively. By pretraining on the ImageNet-21K, our UniNet-B6 achieves 87.4%, outperforming Swin-L with 51% fewer FLOPs and 41% fewer parameters. Code is available at https://github.com/Sense-X/UniNet.
MixMIM: Mixed and Masked Image Modeling for Efficient Visual Representation Learning
May 28, 2022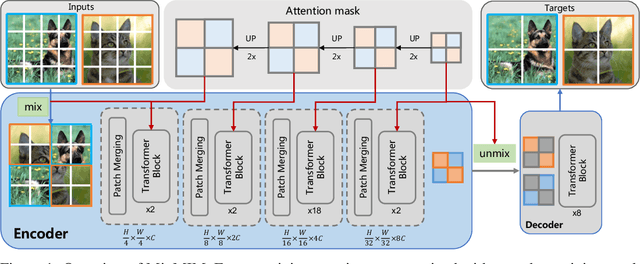

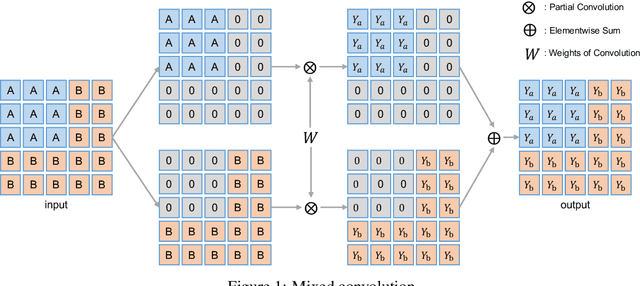
In this study, we propose Mixed and Masked Image Modeling (MixMIM), a simple but efficient MIM method that is applicable to various hierarchical Vision Transformers. Existing MIM methods replace a random subset of input tokens with a special MASK symbol and aim at reconstructing original image tokens from the corrupted image. However, we find that using the MASK symbol greatly slows down the training and causes training-finetuning inconsistency, due to the large masking ratio (e.g., 40% in BEiT). In contrast, we replace the masked tokens of one image with visible tokens of another image, i.e., creating a mixed image. We then conduct dual reconstruction to reconstruct the original two images from the mixed input, which significantly improves efficiency. While MixMIM can be applied to various architectures, this paper explores a simpler but stronger hierarchical Transformer, and scales with MixMIM-B, -L, and -H. Empirical results demonstrate that MixMIM can learn high-quality visual representations efficiently. Notably, MixMIM-B with 88M parameters achieves 85.1% top-1 accuracy on ImageNet-1K by pretraining for 600 epochs, setting a new record for neural networks with comparable model sizes (e.g., ViT-B) among MIM methods. Besides, its transferring performances on the other 6 datasets show MixMIM has better FLOPs / performance tradeoff than previous MIM methods. Code is available at https://github.com/Sense-X/MixMIM.
Meta Knowledge Distillation
Feb 16, 2022
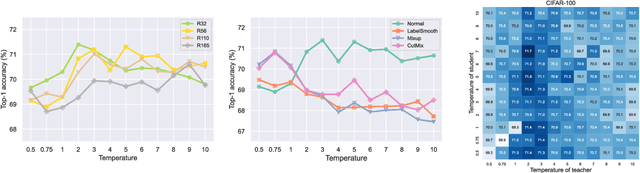
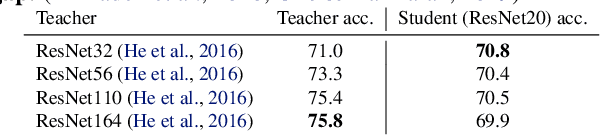
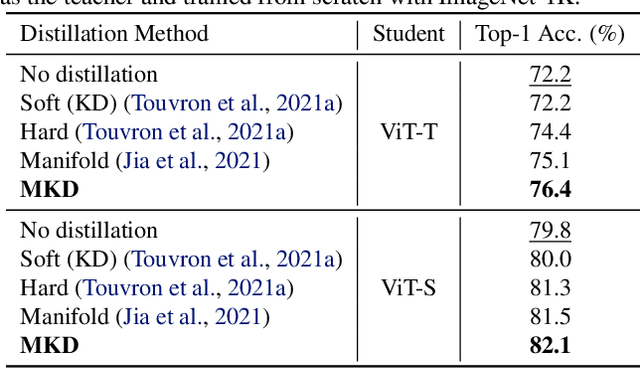
Recent studies pointed out that knowledge distillation (KD) suffers from two degradation problems, the teacher-student gap and the incompatibility with strong data augmentations, making it not applicable to training state-of-the-art models, which are trained with advanced augmentations. However, we observe that a key factor, i.e., the temperatures in the softmax functions for generating probabilities of both the teacher and student models, was mostly overlooked in previous methods. With properly tuned temperatures, such degradation problems of KD can be much mitigated. However, instead of relying on a naive grid search, which shows poor transferability, we propose Meta Knowledge Distillation (MKD) to meta-learn the distillation with learnable meta temperature parameters. The meta parameters are adaptively adjusted during training according to the gradients of the learning objective. We validate that MKD is robust to different dataset scales, different teacher/student architectures, and different types of data augmentation. With MKD, we achieve the best performance with popular ViT architectures among compared methods that use only ImageNet-1K as training data, ranging from tiny to large models. With ViT-L, we achieve 86.5% with 600 epochs of training, 0.6% better than MAE that trains for 1,650 epochs.
INTERN: A New Learning Paradigm Towards General Vision
Nov 16, 2021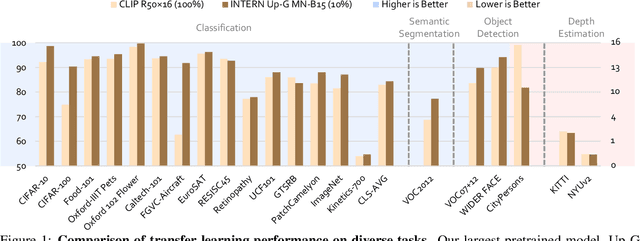
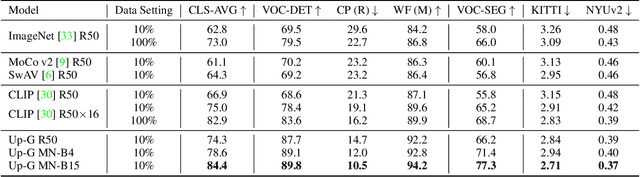
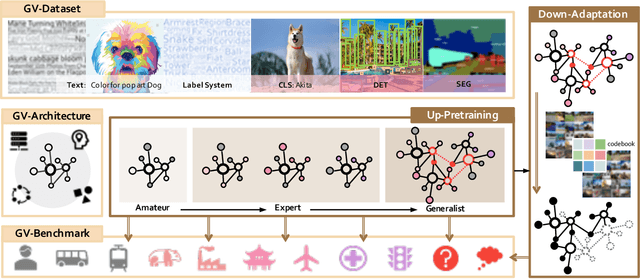
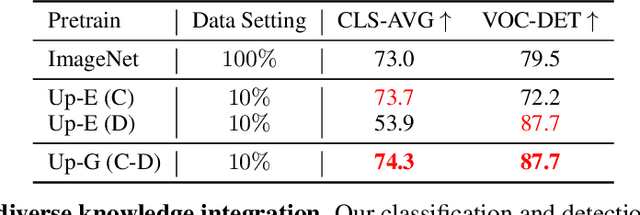
Enormous waves of technological innovations over the past several years, marked by the advances in AI technologies, are profoundly reshaping the industry and the society. However, down the road, a key challenge awaits us, that is, our capability of meeting rapidly-growing scenario-specific demands is severely limited by the cost of acquiring a commensurate amount of training data. This difficult situation is in essence due to limitations of the mainstream learning paradigm: we need to train a new model for each new scenario, based on a large quantity of well-annotated data and commonly from scratch. In tackling this fundamental problem, we move beyond and develop a new learning paradigm named INTERN. By learning with supervisory signals from multiple sources in multiple stages, the model being trained will develop strong generalizability. We evaluate our model on 26 well-known datasets that cover four categories of tasks in computer vision. In most cases, our models, adapted with only 10% of the training data in the target domain, outperform the counterparts trained with the full set of data, often by a significant margin. This is an important step towards a promising prospect where such a model with general vision capability can dramatically reduce our reliance on data, thus expediting the adoption of AI technologies. Furthermore, revolving around our new paradigm, we also introduce a new data system, a new architecture, and a new benchmark, which, together, form a general vision ecosystem to support its future development in an open and inclusive manner.
FNAS: Uncertainty-Aware Fast Neural Architecture Search
May 27, 2021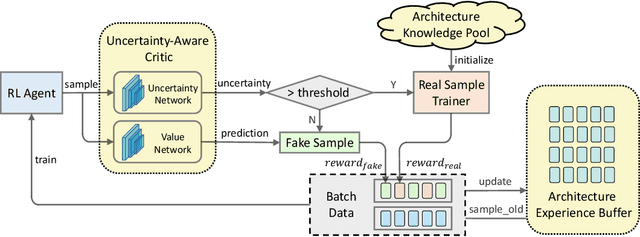
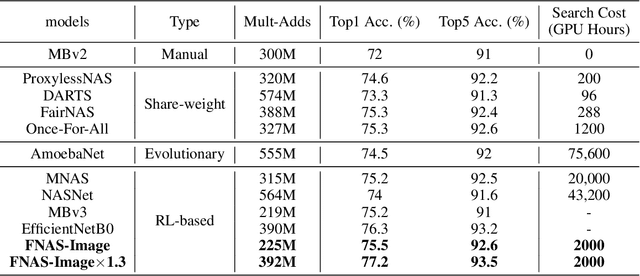
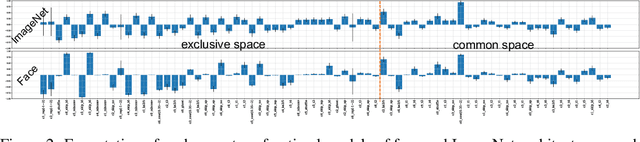
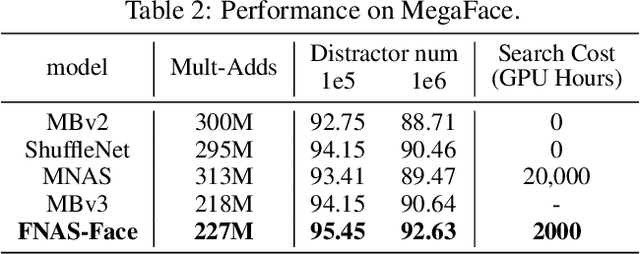
Reinforcement learning (RL)-based neural architecture search (NAS) generally guarantees better convergence yet suffers from the requirement of huge computational resources compared with gradient-based approaches, due to the rollout bottleneck -- exhaustive training for each sampled generation on proxy tasks. In this paper, we propose a general pipeline to accelerate the convergence of the rollout process as well as the RL process in NAS. It is motivated by the interesting observation that both the architecture and the parameter knowledge can be transferred between different experiments and even different tasks. We first introduce an uncertainty-aware critic (value function) in Proximal Policy Optimization (PPO) to utilize the architecture knowledge in previous experiments, which stabilizes the training process and reduces the searching time by 4 times. Further, an architecture knowledge pool together with a block similarity function is proposed to utilize parameter knowledge and reduces the searching time by 2 times. It is the first to introduce block-level weight sharing in RLbased NAS. The block similarity function guarantees a 100% hitting ratio with strict fairness. Besides, we show that a simply designed off-policy correction factor used in "replay buffer" in RL optimization can further reduce half of the searching time. Experiments on the Mobile Neural Architecture Search (MNAS) search space show the proposed Fast Neural Architecture Search (FNAS) accelerates standard RL-based NAS process by ~10x (e.g. ~256 2x2 TPUv2 x days / 20,000 GPU x hour -> 2,000 GPU x hour for MNAS), and guarantees better performance on various vision tasks.
Rotate-and-Render: Unsupervised Photorealistic Face Rotation from Single-View Images
Mar 18, 2020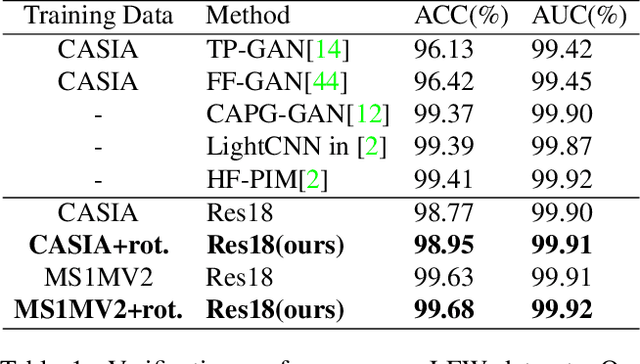
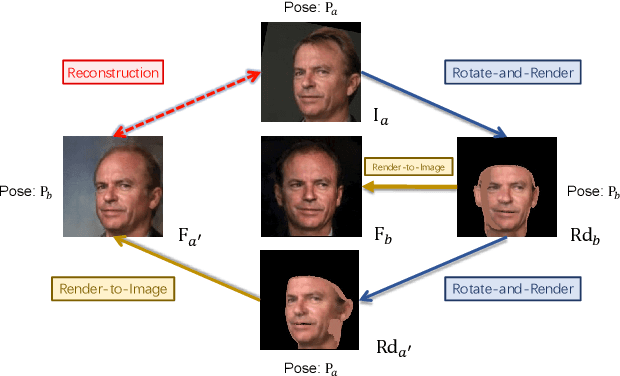

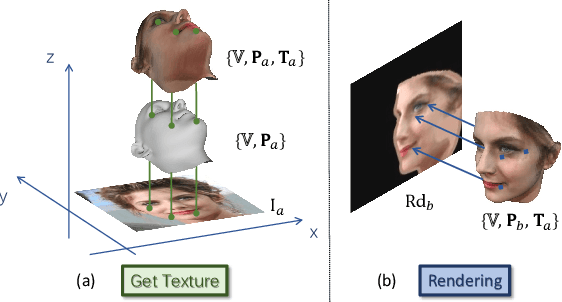
Though face rotation has achieved rapid progress in recent years, the lack of high-quality paired training data remains a great hurdle for existing methods. The current generative models heavily rely on datasets with multi-view images of the same person. Thus, their generated results are restricted by the scale and domain of the data source. To overcome these challenges, we propose a novel unsupervised framework that can synthesize photo-realistic rotated faces using only single-view image collections in the wild. Our key insight is that rotating faces in the 3D space back and forth, and re-rendering them to the 2D plane can serve as a strong self-supervision. We leverage the recent advances in 3D face modeling and high-resolution GAN to constitute our building blocks. Since the 3D rotation-and-render on faces can be applied to arbitrary angles without losing details, our approach is extremely suitable for in-the-wild scenarios (i.e. no paired data are available), where existing methods fall short. Extensive experiments demonstrate that our approach has superior synthesis quality as well as identity preservation over the state-of-the-art methods, across a wide range of poses and domains. Furthermore, we validate that our rotate-and-render framework naturally can act as an effective data augmentation engine for boosting modern face recognition systems even on strong baseline models.