 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYu Qiao
FedCCL: Federated Dual-Clustered Feature Contrast Under Domain Heterogeneity
Apr 14, 2024
Federated learning (FL) facilitates a privacy-preserving neural network training paradigm through collaboration between edge clients and a central server. One significant challenge is that the distributed data is not independently and identically distributed (non-IID), typically including both intra-domain and inter-domain heterogeneity. However, recent research is limited to simply using averaged signals as a form of regularization and only focusing on one aspect of these non-IID challenges. Given these limitations, this paper clarifies these two non-IID challenges and attempts to introduce cluster representation to address them from both local and global perspectives. Specifically, we propose a dual-clustered feature contrast-based FL framework with dual focuses. First, we employ clustering on the local representations of each client, aiming to capture intra-class information based on these local clusters at a high level of granularity. Then, we facilitate cross-client knowledge sharing by pulling the local representation closer to clusters shared by clients with similar semantics while pushing them away from clusters with dissimilar semantics. Second, since the sizes of local clusters belonging to the same class may differ for each client, we further utilize clustering on the global side and conduct averaging to create a consistent global signal for guiding each local training in a contrastive manner. Experimental results on multiple datasets demonstrate that our proposal achieves comparable or superior performance gain under intra-domain and inter-domain heterogeneity.
Logit Calibration and Feature Contrast for Robust Federated Learning on Non-IID Data
Apr 10, 2024Federated learning (FL) is a privacy-preserving distributed framework for collaborative model training on devices in edge networks. However, challenges arise due to vulnerability to adversarial examples (AEs) and the non-independent and identically distributed (non-IID) nature of data distribution among devices, hindering the deployment of adversarially robust and accurate learning models at the edge. While adversarial training (AT) is commonly acknowledged as an effective defense strategy against adversarial attacks in centralized training, we shed light on the adverse effects of directly applying AT in FL that can severely compromise accuracy, especially in non-IID challenges. Given this limitation, this paper proposes FatCC, which incorporates local logit \underline{C}alibration and global feature \underline{C}ontrast into the vanilla federated adversarial training (\underline{FAT}) process from both logit and feature perspectives. This approach can effectively enhance the federated system's robust accuracy (RA) and clean accuracy (CA). First, we propose logit calibration, where the logits are calibrated during local adversarial updates, thereby improving adversarial robustness. Second, FatCC introduces feature contrast, which involves a global alignment term that aligns each local representation with unbiased global features, thus further enhancing robustness and accuracy in federated adversarial environments. Extensive experiments across multiple datasets demonstrate that FatCC achieves comparable or superior performance gains in both CA and RA compared to other baselines.
InternLM-XComposer2-4KHD: A Pioneering Large Vision-Language Model Handling Resolutions from 336 Pixels to 4K HD
Apr 09, 2024The Large Vision-Language Model (LVLM) field has seen significant advancements, yet its progression has been hindered by challenges in comprehending fine-grained visual content due to limited resolution. Recent efforts have aimed to enhance the high-resolution understanding capabilities of LVLMs, yet they remain capped at approximately 1500 x 1500 pixels and constrained to a relatively narrow resolution range. This paper represents InternLM-XComposer2-4KHD, a groundbreaking exploration into elevating LVLM resolution capabilities up to 4K HD (3840 x 1600) and beyond. Concurrently, considering the ultra-high resolution may not be necessary in all scenarios, it supports a wide range of diverse resolutions from 336 pixels to 4K standard, significantly broadening its scope of applicability. Specifically, this research advances the patch division paradigm by introducing a novel extension: dynamic resolution with automatic patch configuration. It maintains the training image aspect ratios while automatically varying patch counts and configuring layouts based on a pre-trained Vision Transformer (ViT) (336 x 336), leading to dynamic training resolution from 336 pixels to 4K standard. Our research demonstrates that scaling training resolution up to 4K HD leads to consistent performance enhancements without hitting the ceiling of potential improvements. InternLM-XComposer2-4KHD shows superb capability that matches or even surpasses GPT-4V and Gemini Pro in 10 of the 16 benchmarks. The InternLM-XComposer2-4KHD model series with 7B parameters are publicly available at https://github.com/InternLM/InternLM-XComposer.
Are We on the Right Way for Evaluating Large Vision-Language Models?
Apr 09, 2024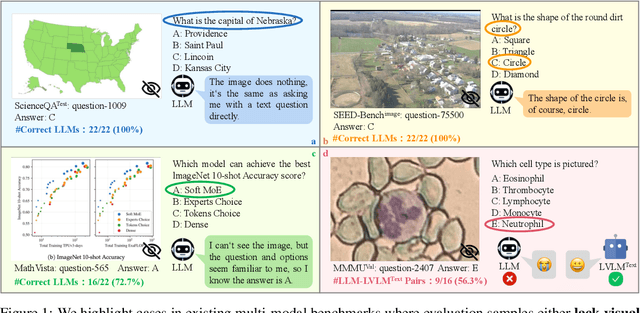
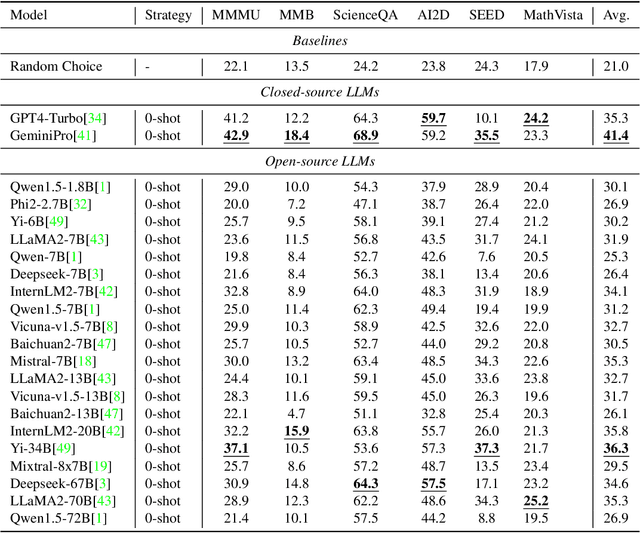
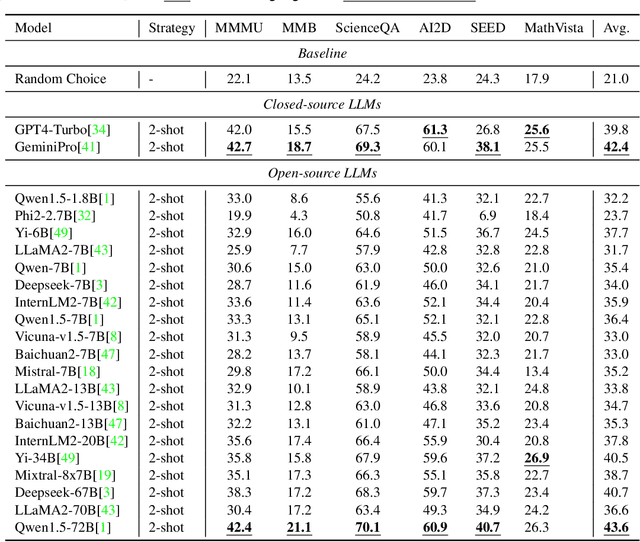
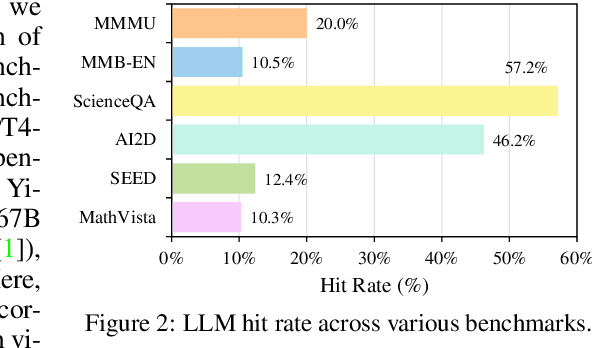
Large vision-language models (LVLMs) have recently achieved rapid progress, sparking numerous studies to evaluate their multi-modal capabilities. However, we dig into current evaluation works and identify two primary issues: 1) Visual content is unnecessary for many samples. The answers can be directly inferred from the questions and options, or the world knowledge embedded in LLMs. This phenomenon is prevalent across current benchmarks. For instance, GeminiPro achieves 42.9% on the MMMU benchmark without any visual input, and outperforms the random choice baseline across six benchmarks over 24% on average. 2) Unintentional data leakage exists in LLM and LVLM training. LLM and LVLM could still answer some visual-necessary questions without visual content, indicating the memorizing of these samples within large-scale training data. For example, Sphinx-X-MoE gets 43.6% on MMMU without accessing images, surpassing its LLM backbone with 17.9%. Both problems lead to misjudgments of actual multi-modal gains and potentially misguide the study of LVLM. To this end, we present MMStar, an elite vision-indispensable multi-modal benchmark comprising 1,500 samples meticulously selected by humans. MMStar benchmarks 6 core capabilities and 18 detailed axes, aiming to evaluate LVLMs' multi-modal capacities with carefully balanced and purified samples. These samples are first roughly selected from current benchmarks with an automated pipeline, human review is then involved to ensure each curated sample exhibits visual dependency, minimal data leakage, and requires advanced multi-modal capabilities. Moreover, two metrics are developed to measure data leakage and actual performance gain in multi-modal training. We evaluate 16 leading LVLMs on MMStar to assess their multi-modal capabilities, and on 7 benchmarks with the proposed metrics to investigate their data leakage and actual multi-modal gain.
Linear Attention Sequence Parallelism
Apr 03, 2024Sequence Parallel (SP) serves as a prevalent strategy to handle long sequences that exceed the memory limit of a single GPU. However, existing SP methods do not take advantage of linear attention features, resulting in sub-optimal parallelism efficiency and usability for linear attention-based language models. In this paper, we introduce Linear Attention Sequence Parallel (LASP), an efficient SP method tailored to linear attention-based language models. Specifically, we design an efficient point-to-point communication mechanism to leverage the right-product kernel trick of linear attention, which sharply decreases the communication overhead of SP. We also enhance the practical efficiency of LASP by performing kernel fusion and intermediate state caching, making the implementation of LASP hardware-friendly on GPU clusters. Furthermore, we meticulously ensure the compatibility of sequence-level LASP with all types of batch-level data parallel methods, which is vital for distributed training on large clusters with long sequences and large batches. We conduct extensive experiments on two linear attention-based models with varying sequence lengths and GPU cluster sizes. LASP scales sequence length up to 4096K using 128 A100 80G GPUs on 1B models, which is 8 times longer than existing SP methods while being significantly faster. The code is available at https://github.com/OpenNLPLab/LASP.
DIBS: Enhancing Dense Video Captioning with Unlabeled Videos via Pseudo Boundary Enrichment and Online Refinement
Apr 03, 2024We present Dive Into the BoundarieS (DIBS), a novel pretraining framework for dense video captioning (DVC), that elaborates on improving the quality of the generated event captions and their associated pseudo event boundaries from unlabeled videos. By leveraging the capabilities of diverse large language models (LLMs), we generate rich DVC-oriented caption candidates and optimize the corresponding pseudo boundaries under several meticulously designed objectives, considering diversity, event-centricity, temporal ordering, and coherence. Moreover, we further introduce a novel online boundary refinement strategy that iteratively improves the quality of pseudo boundaries during training. Comprehensive experiments have been conducted to examine the effectiveness of the proposed technique components. By leveraging a substantial amount of unlabeled video data, such as HowTo100M, we achieve a remarkable advancement on standard DVC datasets like YouCook2 and ActivityNet. We outperform the previous state-of-the-art Vid2Seq across a majority of metrics, achieving this with just 0.4% of the unlabeled video data used for pre-training by Vid2Seq.
VideoDistill: Language-aware Vision Distillation for Video Question Answering
Apr 01, 2024Significant advancements in video question answering (VideoQA) have been made thanks to thriving large image-language pretraining frameworks. Although these image-language models can efficiently represent both video and language branches, they typically employ a goal-free vision perception process and do not interact vision with language well during the answer generation, thus omitting crucial visual cues. In this paper, we are inspired by the human recognition and learning pattern and propose VideoDistill, a framework with language-aware (i.e., goal-driven) behavior in both vision perception and answer generation process. VideoDistill generates answers only from question-related visual embeddings and follows a thinking-observing-answering approach that closely resembles human behavior, distinguishing it from previous research. Specifically, we develop a language-aware gating mechanism to replace the standard cross-attention, avoiding language's direct fusion into visual representations. We incorporate this mechanism into two key components of the entire framework. The first component is a differentiable sparse sampling module, which selects frames containing the necessary dynamics and semantics relevant to the questions. The second component is a vision refinement module that merges existing spatial-temporal attention layers to ensure the extraction of multi-grained visual semantics associated with the questions. We conduct experimental evaluations on various challenging video question-answering benchmarks, and VideoDistill achieves state-of-the-art performance in both general and long-form VideoQA datasets. In Addition, we verify that VideoDistill can effectively alleviate the utilization of language shortcut solutions in the EgoTaskQA dataset.
LLaMA-Excitor: General Instruction Tuning via Indirect Feature Interaction
Apr 01, 2024Existing methods to fine-tune LLMs, like Adapter, Prefix-tuning, and LoRA, which introduce extra modules or additional input sequences to inject new skills or knowledge, may compromise the innate abilities of LLMs. In this paper, we propose LLaMA-Excitor, a lightweight method that stimulates the LLMs' potential to better follow instructions by gradually paying more attention to worthwhile information. Specifically, the LLaMA-Excitor does not directly change the intermediate hidden state during the self-attention calculation of the transformer structure. We designed the Excitor block as a bypass module for the similarity score computation in LLMs' self-attention to reconstruct keys and change the importance of values by learnable prompts. LLaMA-Excitor ensures a self-adaptive allocation of additional attention to input instructions, thus effectively preserving LLMs' pre-trained knowledge when fine-tuning LLMs on low-quality instruction-following datasets. Furthermore, we unify the modeling of multi-modal tuning and language-only tuning, extending LLaMA-Excitor to a powerful visual instruction follower without the need for complex multi-modal alignment. Our proposed approach is evaluated in language-only and multi-modal tuning experimental scenarios. Notably, LLaMA-Excitor is the only method that maintains basic capabilities while achieving a significant improvement (+6%) on the MMLU benchmark. In the visual instruction tuning, we achieve a new state-of-the-art image captioning performance of 157.5 CIDEr on MSCOCO, and a comparable performance (88.39%) on ScienceQA to cutting-edge models with more parameters and extensive vision-language pertaining.
DiffAgent: Fast and Accurate Text-to-Image API Selection with Large Language Model
Mar 31, 2024Text-to-image (T2I) generative models have attracted significant attention and found extensive applications within and beyond academic research. For example, the Civitai community, a platform for T2I innovation, currently hosts an impressive array of 74,492 distinct models. However, this diversity presents a formidable challenge in selecting the most appropriate model and parameters, a process that typically requires numerous trials. Drawing inspiration from the tool usage research of large language models (LLMs), we introduce DiffAgent, an LLM agent designed to screen the accurate selection in seconds via API calls. DiffAgent leverages a novel two-stage training framework, SFTA, enabling it to accurately align T2I API responses with user input in accordance with human preferences. To train and evaluate DiffAgent's capabilities, we present DABench, a comprehensive dataset encompassing an extensive range of T2I APIs from the community. Our evaluations reveal that DiffAgent not only excels in identifying the appropriate T2I API but also underscores the effectiveness of the SFTA training framework. Codes are available at https://github.com/OpenGVLab/DiffAgent.