 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhen Qin
TAVGBench: Benchmarking Text to Audible-Video Generation
Apr 22, 2024
The Text to Audible-Video Generation (TAVG) task involves generating videos with accompanying audio based on text descriptions. Achieving this requires skillful alignment of both audio and video elements. To support research in this field, we have developed a comprehensive Text to Audible-Video Generation Benchmark (TAVGBench), which contains over 1.7 million clips with a total duration of 11.8 thousand hours. We propose an automatic annotation pipeline to ensure each audible video has detailed descriptions for both its audio and video contents. We also introduce the Audio-Visual Harmoni score (AVHScore) to provide a quantitative measure of the alignment between the generated audio and video modalities. Additionally, we present a baseline model for TAVG called TAVDiffusion, which uses a two-stream latent diffusion model to provide a fundamental starting point for further research in this area. We achieve the alignment of audio and video by employing cross-attention and contrastive learning. Through extensive experiments and evaluations on TAVGBench, we demonstrate the effectiveness of our proposed model under both conventional metrics and our proposed metrics.
Consolidating Ranking and Relevance Predictions of Large Language Models through Post-Processing
Apr 17, 2024The powerful generative abilities of large language models (LLMs) show potential in generating relevance labels for search applications. Previous work has found that directly asking about relevancy, such as ``How relevant is document A to query Q?", results in sub-optimal ranking. Instead, the pairwise ranking prompting (PRP) approach produces promising ranking performance through asking about pairwise comparisons, e.g., ``Is document A more relevant than document B to query Q?". Thus, while LLMs are effective at their ranking ability, this is not reflected in their relevance label generation. In this work, we propose a post-processing method to consolidate the relevance labels generated by an LLM with its powerful ranking abilities. Our method takes both LLM generated relevance labels and pairwise preferences. The labels are then altered to satisfy the pairwise preferences of the LLM, while staying as close to the original values as possible. Our experimental results indicate that our approach effectively balances label accuracy and ranking performance. Thereby, our work shows it is possible to combine both the ranking and labeling abilities of LLMs through post-processing.
HGRN2: Gated Linear RNNs with State Expansion
Apr 11, 2024Hierarchically gated linear RNN (HGRN,Qin et al. 2023) has demonstrated competitive training speed and performance in language modeling, while offering efficient inference. However, the recurrent state size of HGRN remains relatively small, which limits its expressiveness.To address this issue, inspired by linear attention, we introduce a simple outer-product-based state expansion mechanism so that the recurrent state size can be significantly enlarged without introducing any additional parameters. The linear attention form also allows for hardware-efficient training.Our extensive experiments verify the advantage of HGRN2 over HGRN1 in language modeling, image classification, and Long Range Arena.Our largest 3B HGRN2 model slightly outperforms Mamba and LLaMa Architecture Transformer for language modeling in a controlled experiment setting; and performs competitively with many open-source 3B models in downstream evaluation while using much fewer total training tokens.
Linear Attention Sequence Parallelism
Apr 03, 2024Sequence Parallel (SP) serves as a prevalent strategy to handle long sequences that exceed the memory limit of a single GPU. However, existing SP methods do not take advantage of linear attention features, resulting in sub-optimal parallelism efficiency and usability for linear attention-based language models. In this paper, we introduce Linear Attention Sequence Parallel (LASP), an efficient SP method tailored to linear attention-based language models. Specifically, we design an efficient point-to-point communication mechanism to leverage the right-product kernel trick of linear attention, which sharply decreases the communication overhead of SP. We also enhance the practical efficiency of LASP by performing kernel fusion and intermediate state caching, making the implementation of LASP hardware-friendly on GPU clusters. Furthermore, we meticulously ensure the compatibility of sequence-level LASP with all types of batch-level data parallel methods, which is vital for distributed training on large clusters with long sequences and large batches. We conduct extensive experiments on two linear attention-based models with varying sequence lengths and GPU cluster sizes. LASP scales sequence length up to 4096K using 128 A100 80G GPUs on 1B models, which is 8 times longer than existing SP methods while being significantly faster. The code is available at https://github.com/OpenNLPLab/LASP.
LiPO: Listwise Preference Optimization through Learning-to-Rank
Feb 02, 2024Aligning language models (LMs) with curated human feedback is critical to control their behaviors in real-world applications. Several recent policy optimization methods, such as DPO and SLiC, serve as promising alternatives to the traditional Reinforcement Learning from Human Feedback (RLHF) approach. In practice, human feedback often comes in a format of a ranked list over multiple responses to amortize the cost of reading prompt. Multiple responses can also be ranked by reward models or AI feedback. There lacks such a study on directly fitting upon a list of responses. In this work, we formulate the LM alignment as a listwise ranking problem and describe the Listwise Preference Optimization (LiPO) framework, where the policy can potentially learn more effectively from a ranked list of plausible responses given the prompt. This view draws an explicit connection to Learning-to-Rank (LTR), where most existing preference optimization work can be mapped to existing ranking objectives, especially pairwise ones. Following this connection, we provide an examination of ranking objectives that are not well studied for LM alignment withDPO and SLiC as special cases when list size is two. In particular, we highlight a specific method, LiPO-{\lambda}, which leverages a state-of-the-art listwise ranking objective and weights each preference pair in a more advanced manner. We show that LiPO-{\lambda} can outperform DPO and SLiC by a clear margin on two preference alignment tasks.
CO2: Efficient Distributed Training with Full Communication-Computation Overlap
Jan 29, 2024The fundamental success of large language models hinges upon the efficacious implementation of large-scale distributed training techniques. Nevertheless, building a vast, high-performance cluster featuring high-speed communication interconnectivity is prohibitively costly, and accessible only to prominent entities. In this work, we aim to lower this barrier and democratize large-scale training with limited bandwidth clusters. We propose a new approach called CO2 that introduces local-updating and asynchronous communication to the distributed data-parallel training, thereby facilitating the full overlap of COmunication with COmputation. CO2 is able to attain a high scalability even on extensive multi-node clusters constrained by very limited communication bandwidth. We further propose the staleness gap penalty and outer momentum clipping techniques together with CO2 to bolster its convergence and training stability. Besides, CO2 exhibits seamless integration with well-established ZeRO-series optimizers which mitigate memory consumption of model states with large model training. We also provide a mathematical proof of convergence, accompanied by the establishment of a stringent upper bound. Furthermore, we validate our findings through an extensive set of practical experiments encompassing a wide range of tasks in the fields of computer vision and natural language processing. These experiments serve to demonstrate the capabilities of CO2 in terms of convergence, generalization, and scalability when deployed across configurations comprising up to 128 A100 GPUs. The outcomes emphasize the outstanding capacity of CO2 to hugely improve scalability, no matter on clusters with 800Gbps RDMA or 80Gbps TCP/IP inter-node connections.
Lightning Attention-2: A Free Lunch for Handling Unlimited Sequence Lengths in Large Language Models
Jan 15, 2024Linear attention is an efficient attention mechanism that has recently emerged as a promising alternative to conventional softmax attention. With its ability to process tokens in linear computational complexities, linear attention, in theory, can handle sequences of unlimited length without sacrificing speed, i.e., maintaining a constant training speed for various sequence lengths with a fixed memory consumption. However, due to the issue with cumulative summation (cumsum), current linear attention algorithms cannot demonstrate their theoretical advantage in a causal setting. In this paper, we present Lightning Attention-2, the first linear attention implementation that enables linear attention to realize its theoretical computational benefits. To achieve this, we leverage the thought of tiling, separately handling the intra-block and inter-block components in linear attention calculation. Specifically, we utilize the conventional attention computation mechanism for the intra-blocks and apply linear attention kernel tricks for the inter-blocks. A tiling technique is adopted through both forward and backward procedures to take full advantage of the GPU hardware. We implement our algorithm in Triton to make it IO-aware and hardware-friendly. Various experiments are conducted on different model sizes and sequence lengths. Lightning Attention-2 retains consistent training and inference speed regardless of input sequence length and is significantly faster than other attention mechanisms. The source code is available at https://github.com/OpenNLPLab/lightning-attention.
Guaranteed Nonconvex Factorization Approach for Tensor Train Recovery
Jan 05, 2024In this paper, we provide the first convergence guarantee for the factorization approach. Specifically, to avoid the scaling ambiguity and to facilitate theoretical analysis, we optimize over the so-called left-orthogonal TT format which enforces orthonormality among most of the factors. To ensure the orthonormal structure, we utilize the Riemannian gradient descent (RGD) for optimizing those factors over the Stiefel manifold. We first delve into the TT factorization problem and establish the local linear convergence of RGD. Notably, the rate of convergence only experiences a linear decline as the tensor order increases. We then study the sensing problem that aims to recover a TT format tensor from linear measurements. Assuming the sensing operator satisfies the restricted isometry property (RIP), we show that with a proper initialization, which could be obtained through spectral initialization, RGD also converges to the ground-truth tensor at a linear rate. Furthermore, we expand our analysis to encompass scenarios involving Gaussian noise in the measurements. We prove that RGD can reliably recover the ground truth at a linear rate, with the recovery error exhibiting only polynomial growth in relation to the tensor order. We conduct various experiments to validate our theoretical findings.
Federated Full-Parameter Tuning of Billion-Sized Language Models with Communication Cost under 18 Kilobytes
Dec 26, 2023Pre-trained large language models (LLMs) require fine-tuning to improve their responsiveness to natural language instructions. Federated learning (FL) offers a way to perform fine-tuning using the abundant data on end devices without compromising data privacy. Most existing federated fine-tuning methods for LLMs rely on parameter-efficient fine-tuning techniques, which may not reach the performance heights possible with full-parameter tuning. However, the communication overhead associated with full-parameter tuning is prohibitively high for both servers and clients. This work introduces FedKSeed, a novel approach that employs zeroth-order optimization (ZOO) with a set of random seeds. It enables federated full-parameter tuning of billion-sized LLMs directly on devices. Our method significantly reduces transmission requirements between the server and clients to just a few scalar gradients and random seeds, amounting to only a few thousand bytes. Building on this, we develop a strategy to assess the significance of ZOO perturbations for FL, allowing for probability-differentiated seed sampling. This prioritizes perturbations that have a greater impact on model accuracy. Experiments across six scenarios with different LLMs, datasets and data partitions demonstrate that our approach outperforms existing federated LLM fine-tuning methods in terms of both communication efficiency and new task generalization.
MACE: A Multi-pattern Accommodated and Efficient Anomaly Detection Method in the Frequency Domain
Nov 26, 2023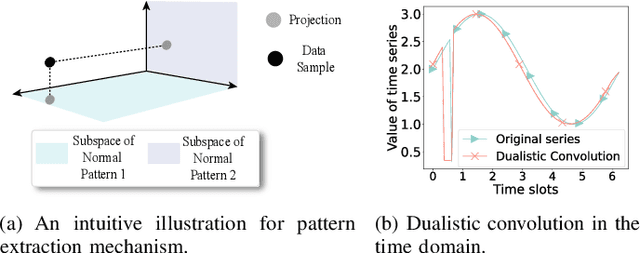



Anomaly detection significantly enhances the robustness of cloud systems. While neural network-based methods have recently demonstrated strong advantages, they encounter practical challenges in cloud environments: the contradiction between the impracticality of maintaining a unique model for each service and the limited ability of dealing with diverse normal patterns by a unified model, as well as issues with handling heavy traffic in real time and short-term anomaly detection sensitivity. Thus, we propose MACE, a Multi-pattern Accommodated and efficient Anomaly detection method in the frequency domain for time series anomaly detection. There are three novel characteristics of it: (i) a pattern extraction mechanism excelling at handling diverse normal patterns, which enables the model to identify anomalies by examining the correlation between the data sample and its service normal pattern, instead of solely focusing on the data sample itself; (ii) a dualistic convolution mechanism that amplifies short-term anomalies in the time domain and hinders the reconstruction of anomalies in the frequency domain, which enlarges the reconstruction error disparity between anomaly and normality and facilitates anomaly detection; (iii) leveraging the sparsity and parallelism of frequency domain to enhance model efficiency. We theoretically and experimentally prove that using a strategically selected subset of Fourier bases can not only reduce computational overhead but is also profit to distinguish anomalies, compared to using the complete spectrum. Moreover, extensive experiments demonstrate MACE's effectiveness in handling diverse normal patterns with a unified model and it achieves state-of-the-art performance with high efficiency. \end{abstract}