 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZehui Chen
Are We on the Right Way for Evaluating Large Vision-Language Models?
Apr 09, 2024
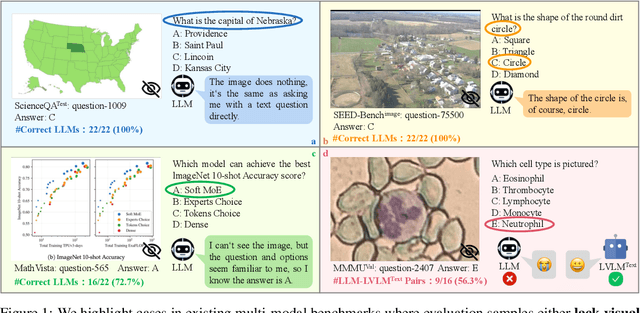
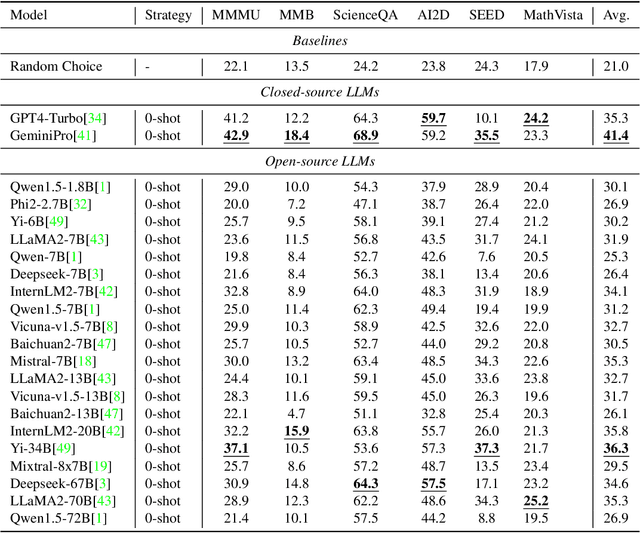
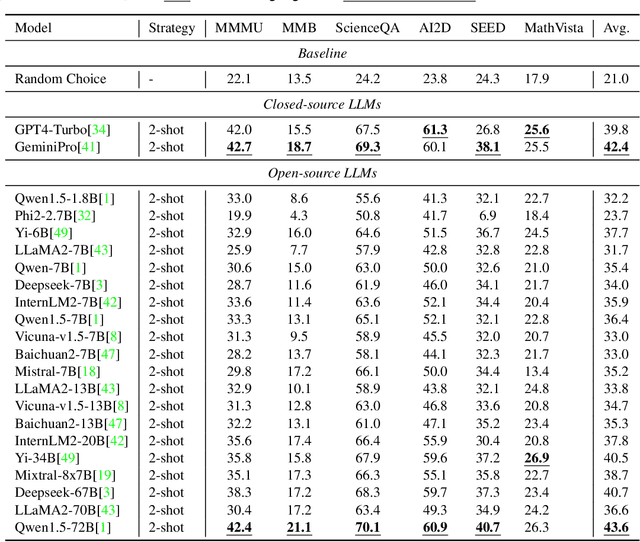
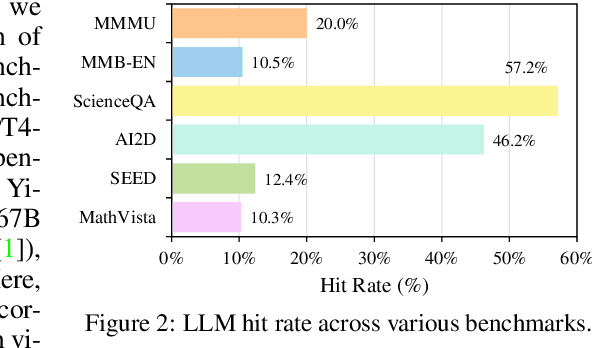
Large vision-language models (LVLMs) have recently achieved rapid progress, sparking numerous studies to evaluate their multi-modal capabilities. However, we dig into current evaluation works and identify two primary issues: 1) Visual content is unnecessary for many samples. The answers can be directly inferred from the questions and options, or the world knowledge embedded in LLMs. This phenomenon is prevalent across current benchmarks. For instance, GeminiPro achieves 42.9% on the MMMU benchmark without any visual input, and outperforms the random choice baseline across six benchmarks over 24% on average. 2) Unintentional data leakage exists in LLM and LVLM training. LLM and LVLM could still answer some visual-necessary questions without visual content, indicating the memorizing of these samples within large-scale training data. For example, Sphinx-X-MoE gets 43.6% on MMMU without accessing images, surpassing its LLM backbone with 17.9%. Both problems lead to misjudgments of actual multi-modal gains and potentially misguide the study of LVLM. To this end, we present MMStar, an elite vision-indispensable multi-modal benchmark comprising 1,500 samples meticulously selected by humans. MMStar benchmarks 6 core capabilities and 18 detailed axes, aiming to evaluate LVLMs' multi-modal capacities with carefully balanced and purified samples. These samples are first roughly selected from current benchmarks with an automated pipeline, human review is then involved to ensure each curated sample exhibits visual dependency, minimal data leakage, and requires advanced multi-modal capabilities. Moreover, two metrics are developed to measure data leakage and actual performance gain in multi-modal training. We evaluate 16 leading LVLMs on MMStar to assess their multi-modal capabilities, and on 7 benchmarks with the proposed metrics to investigate their data leakage and actual multi-modal gain.
InternLM2 Technical Report
Mar 26, 2024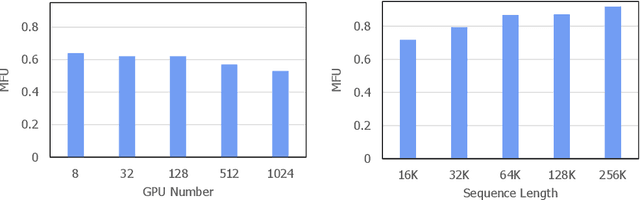
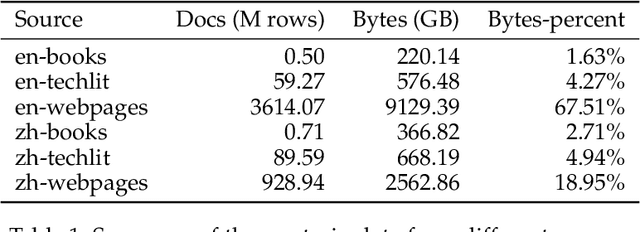


The evolution of Large Language Models (LLMs) like ChatGPT and GPT-4 has sparked discussions on the advent of Artificial General Intelligence (AGI). However, replicating such advancements in open-source models has been challenging. This paper introduces InternLM2, an open-source LLM that outperforms its predecessors in comprehensive evaluations across 6 dimensions and 30 benchmarks, long-context modeling, and open-ended subjective evaluations through innovative pre-training and optimization techniques. The pre-training process of InternLM2 is meticulously detailed, highlighting the preparation of diverse data types including text, code, and long-context data. InternLM2 efficiently captures long-term dependencies, initially trained on 4k tokens before advancing to 32k tokens in pre-training and fine-tuning stages, exhibiting remarkable performance on the 200k ``Needle-in-a-Haystack" test. InternLM2 is further aligned using Supervised Fine-Tuning (SFT) and a novel Conditional Online Reinforcement Learning from Human Feedback (COOL RLHF) strategy that addresses conflicting human preferences and reward hacking. By releasing InternLM2 models in different training stages and model sizes, we provide the community with insights into the model's evolution.
PlainMamba: Improving Non-Hierarchical Mamba in Visual Recognition
Mar 26, 2024

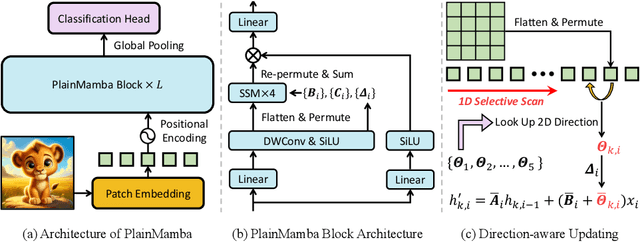
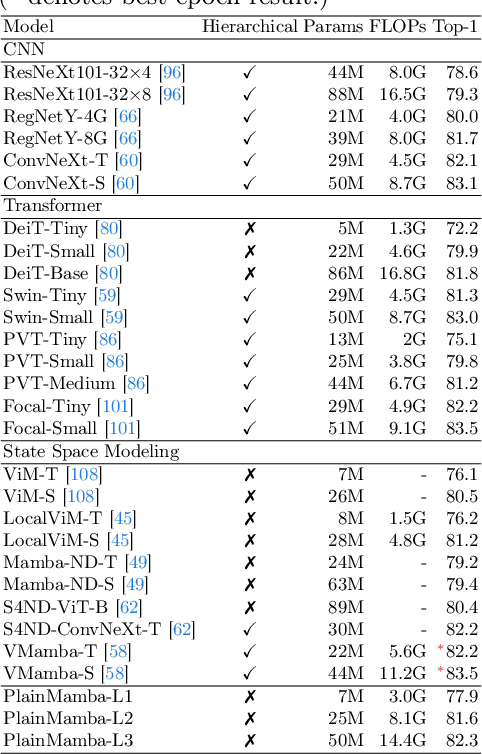
We present PlainMamba: a simple non-hierarchical state space model (SSM) designed for general visual recognition. The recent Mamba model has shown how SSMs can be highly competitive with other architectures on sequential data and initial attempts have been made to apply it to images. In this paper, we further adapt the selective scanning process of Mamba to the visual domain, enhancing its ability to learn features from two-dimensional images by (i) a continuous 2D scanning process that improves spatial continuity by ensuring adjacency of tokens in the scanning sequence, and (ii) direction-aware updating which enables the model to discern the spatial relations of tokens by encoding directional information. Our architecture is designed to be easy to use and easy to scale, formed by stacking identical PlainMamba blocks, resulting in a model with constant width throughout all layers. The architecture is further simplified by removing the need for special tokens. We evaluate PlainMamba on a variety of visual recognition tasks including image classification, semantic segmentation, object detection, and instance segmentation. Our method achieves performance gains over previous non-hierarchical models and is competitive with hierarchical alternatives. For tasks requiring high-resolution inputs, in particular, PlainMamba requires much less computing while maintaining high performance. Code and models are available at https://github.com/ChenhongyiYang/PlainMamba
Point-DETR3D: Leveraging Imagery Data with Spatial Point Prior for Weakly Semi-supervised 3D Object Detection
Mar 25, 2024Training high-accuracy 3D detectors necessitates massive labeled 3D annotations with 7 degree-of-freedom, which is laborious and time-consuming. Therefore, the form of point annotations is proposed to offer significant prospects for practical applications in 3D detection, which is not only more accessible and less expensive but also provides strong spatial information for object localization. In this paper, we empirically discover that it is non-trivial to merely adapt Point-DETR to its 3D form, encountering two main bottlenecks: 1) it fails to encode strong 3D prior into the model, and 2) it generates low-quality pseudo labels in distant regions due to the extreme sparsity of LiDAR points. To overcome these challenges, we introduce Point-DETR3D, a teacher-student framework for weakly semi-supervised 3D detection, designed to fully capitalize on point-wise supervision within a constrained instance-wise annotation budget.Different from Point-DETR which encodes 3D positional information solely through a point encoder, we propose an explicit positional query initialization strategy to enhance the positional prior. Considering the low quality of pseudo labels at distant regions produced by the teacher model, we enhance the detector's perception by incorporating dense imagery data through a novel Cross-Modal Deformable RoI Fusion (D-RoI).Moreover, an innovative point-guided self-supervised learning technique is proposed to allow for fully exploiting point priors, even in student models.Extensive experiments on representative nuScenes dataset demonstrate our Point-DETR3D obtains significant improvements compared to previous works. Notably, with only 5% of labeled data, Point-DETR3D achieves over 90% performance of its fully supervised counterpart.
Agent-FLAN: Designing Data and Methods of Effective Agent Tuning for Large Language Models
Mar 19, 2024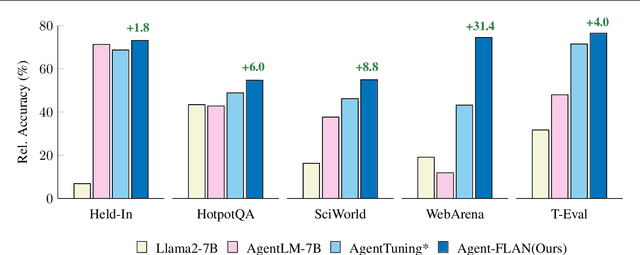
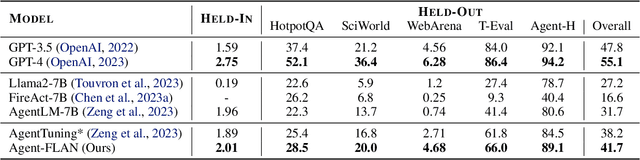
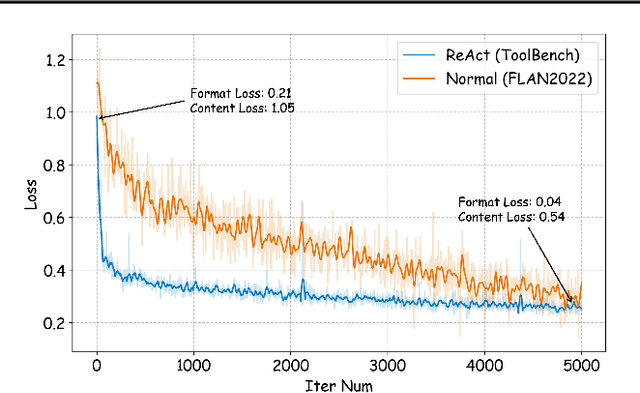
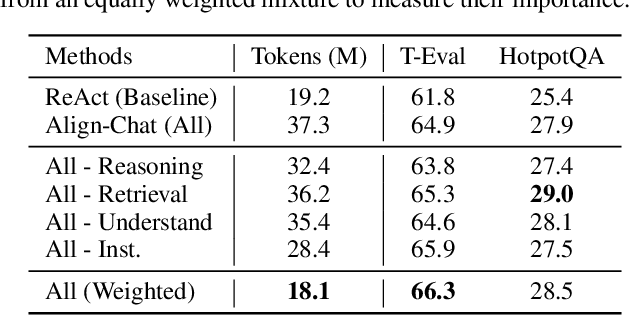
Open-sourced Large Language Models (LLMs) have achieved great success in various NLP tasks, however, they are still far inferior to API-based models when acting as agents. How to integrate agent ability into general LLMs becomes a crucial and urgent problem. This paper first delivers three key observations: (1) the current agent training corpus is entangled with both formats following and agent reasoning, which significantly shifts from the distribution of its pre-training data; (2) LLMs exhibit different learning speeds on the capabilities required by agent tasks; and (3) current approaches have side-effects when improving agent abilities by introducing hallucinations. Based on the above findings, we propose Agent-FLAN to effectively Fine-tune LANguage models for Agents. Through careful decomposition and redesign of the training corpus, Agent-FLAN enables Llama2-7B to outperform prior best works by 3.5\% across various agent evaluation datasets. With comprehensively constructed negative samples, Agent-FLAN greatly alleviates the hallucination issues based on our established evaluation benchmark. Besides, it consistently improves the agent capability of LLMs when scaling model sizes while slightly enhancing the general capability of LLMs. The code will be available at https://github.com/InternLM/Agent-FLAN.
A Vanilla Multi-Task Framework for Dense Visual Prediction Solution to 1st VCL Challenge -- Multi-Task Robustness Track
Feb 27, 2024In this report, we present our solution to the multi-task robustness track of the 1st Visual Continual Learning (VCL) Challenge at ICCV 2023 Workshop. We propose a vanilla framework named UniNet that seamlessly combines various visual perception algorithms into a multi-task model. Specifically, we choose DETR3D, Mask2Former, and BinsFormer for 3D object detection, instance segmentation, and depth estimation tasks, respectively. The final submission is a single model with InternImage-L backbone, and achieves a 49.6 overall score (29.5 Det mAP, 80.3 mTPS, 46.4 Seg mAP, and 7.93 silog) on SHIFT validation set. Besides, we provide some interesting observations in our experiments which may facilitate the development of multi-task learning in dense visual prediction.
Stream Query Denoising for Vectorized HD Map Construction
Jan 18, 2024To enhance perception performance in complex and extensive scenarios within the realm of autonomous driving, there has been a noteworthy focus on temporal modeling, with a particular emphasis on streaming methods. The prevailing trend in streaming models involves the utilization of stream queries for the propagation of temporal information. Despite the prevalence of this approach, the direct application of the streaming paradigm to the construction of vectorized high-definition maps (HD-maps) fails to fully harness the inherent potential of temporal information. This paper introduces the Stream Query Denoising (SQD) strategy as a novel approach for temporal modeling in high-definition map (HD-map) construction. SQD is designed to facilitate the learning of temporal consistency among map elements within the streaming model. The methodology involves denoising the queries that have been perturbed by the addition of noise to the ground-truth information from the preceding frame. This denoising process aims to reconstruct the ground-truth information for the current frame, thereby simulating the prediction process inherent in stream queries. The SQD strategy can be applied to those streaming methods (e.g., StreamMapNet) to enhance the temporal modeling. The proposed SQD-MapNet is the StreamMapNet equipped with SQD. Extensive experiments on nuScenes and Argoverse2 show that our method is remarkably superior to other existing methods across all settings of close range and long range. The code will be available soon.
T-Eval: Evaluating the Tool Utilization Capability of Large Language Models Step by Step
Jan 15, 2024Large language models (LLM) have achieved remarkable performance on various NLP tasks and are augmented by tools for broader applications. Yet, how to evaluate and analyze the tool-utilization capability of LLMs is still under-explored. In contrast to previous works that evaluate models holistically, we comprehensively decompose the tool utilization into multiple sub-processes, including instruction following, planning, reasoning, retrieval, understanding, and review. Based on that, we further introduce T-Eval to evaluate the tool utilization capability step by step. T-Eval disentangles the tool utilization evaluation into several sub-domains along model capabilities, facilitating the inner understanding of both holistic and isolated competency of LLMs. We conduct extensive experiments on T-Eval and in-depth analysis of various LLMs. T-Eval not only exhibits consistency with the outcome-oriented evaluation but also provides a more fine-grained analysis of the capabilities of LLMs, providing a new perspective in LLM evaluation on tool-utilization ability. The benchmark will be available at https://github.com/open-compass/T-Eval.
LiDAR-LLM: Exploring the Potential of Large Language Models for 3D LiDAR Understanding
Dec 21, 2023Recently, Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) have shown promise in instruction following and 2D image understanding. While these models are powerful, they have not yet been developed to comprehend the more challenging 3D physical scenes, especially when it comes to the sparse outdoor LiDAR data. In this paper, we introduce LiDAR-LLM, which takes raw LiDAR data as input and harnesses the remarkable reasoning capabilities of LLMs to gain a comprehensive understanding of outdoor 3D scenes. The central insight of our LiDAR-LLM is the reformulation of 3D outdoor scene cognition as a language modeling problem, encompassing tasks such as 3D captioning, 3D grounding, 3D question answering, etc. Specifically, due to the scarcity of 3D LiDAR-text pairing data, we introduce a three-stage training strategy and generate relevant datasets, progressively aligning the 3D modality with the language embedding space of LLM. Furthermore, we design a View-Aware Transformer (VAT) to connect the 3D encoder with the LLM, which effectively bridges the modality gap and enhances the LLM's spatial orientation comprehension of visual features. Our experiments show that LiDAR-LLM possesses favorable capabilities to comprehend various instructions regarding 3D scenes and engage in complex spatial reasoning. LiDAR-LLM attains a 40.9 BLEU-1 on the 3D captioning task and achieves a 63.1\% classification accuracy and a 14.3\% BEV mIoU on the 3D grounding task. Web page: https://sites.google.com/view/lidar-llm
Adaptive Distribution Masked Autoencoders for Continual Test-Time Adaptation
Dec 19, 2023Continual Test-Time Adaptation (CTTA) is proposed to migrate a source pre-trained model to continually changing target distributions, addressing real-world dynamism. Existing CTTA methods mainly rely on entropy minimization or teacher-student pseudo-labeling schemes for knowledge extraction in unlabeled target domains. However, dynamic data distributions cause miscalibrated predictions and noisy pseudo-labels in existing self-supervised learning methods, hindering the effective mitigation of error accumulation and catastrophic forgetting problems during the continual adaptation process. To tackle these issues, we propose a continual self-supervised method, Adaptive Distribution Masked Autoencoders (ADMA), which enhances the extraction of target domain knowledge while mitigating the accumulation of distribution shifts. Specifically, we propose a Distribution-aware Masking (DaM) mechanism to adaptively sample masked positions, followed by establishing consistency constraints between the masked target samples and the original target samples. Additionally, for masked tokens, we utilize an efficient decoder to reconstruct a hand-crafted feature descriptor (e.g., Histograms of Oriented Gradients), leveraging its invariant properties to boost task-relevant representations. Through conducting extensive experiments on four widely recognized benchmarks, our proposed method attains state-of-the-art performance in both classification and segmentation CTTA tasks.