 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeihua Du
HAZARD Challenge: Embodied Decision Making in Dynamically Changing Environments
Jan 23, 2024
Recent advances in high-fidelity virtual environments serve as one of the major driving forces for building intelligent embodied agents to perceive, reason and interact with the physical world. Typically, these environments remain unchanged unless agents interact with them. However, in real-world scenarios, agents might also face dynamically changing environments characterized by unexpected events and need to rapidly take action accordingly. To remedy this gap, we propose a new simulated embodied benchmark, called HAZARD, specifically designed to assess the decision-making abilities of embodied agents in dynamic situations. HAZARD consists of three unexpected disaster scenarios, including fire, flood, and wind, and specifically supports the utilization of large language models (LLMs) to assist common sense reasoning and decision-making. This benchmark enables us to evaluate autonomous agents' decision-making capabilities across various pipelines, including reinforcement learning (RL), rule-based, and search-based methods in dynamically changing environments. As a first step toward addressing this challenge using large language models, we further develop an LLM-based agent and perform an in-depth analysis of its promise and challenge of solving these challenging tasks. HAZARD is available at https://vis-www.cs.umass.edu/hazard/.
T-Eval: Evaluating the Tool Utilization Capability of Large Language Models Step by Step
Jan 15, 2024Large language models (LLM) have achieved remarkable performance on various NLP tasks and are augmented by tools for broader applications. Yet, how to evaluate and analyze the tool-utilization capability of LLMs is still under-explored. In contrast to previous works that evaluate models holistically, we comprehensively decompose the tool utilization into multiple sub-processes, including instruction following, planning, reasoning, retrieval, understanding, and review. Based on that, we further introduce T-Eval to evaluate the tool utilization capability step by step. T-Eval disentangles the tool utilization evaluation into several sub-domains along model capabilities, facilitating the inner understanding of both holistic and isolated competency of LLMs. We conduct extensive experiments on T-Eval and in-depth analysis of various LLMs. T-Eval not only exhibits consistency with the outcome-oriented evaluation but also provides a more fine-grained analysis of the capabilities of LLMs, providing a new perspective in LLM evaluation on tool-utilization ability. The benchmark will be available at https://github.com/open-compass/T-Eval.
Iteratively Learn Diverse Strategies with State Distance Information
Oct 23, 2023
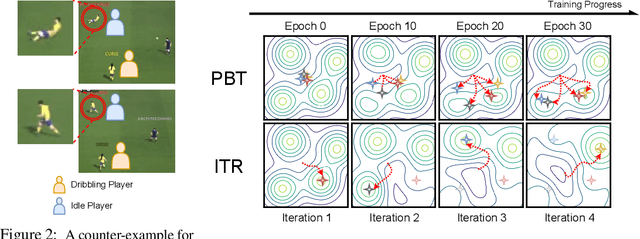
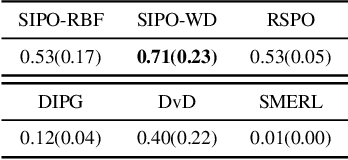
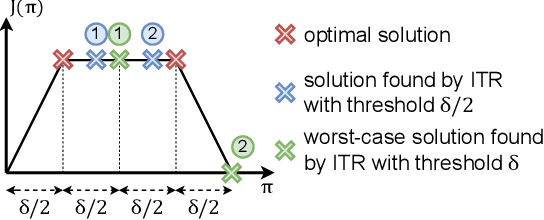
In complex reinforcement learning (RL) problems, policies with similar rewards may have substantially different behaviors. It remains a fundamental challenge to optimize rewards while also discovering as many diverse strategies as possible, which can be crucial in many practical applications. Our study examines two design choices for tackling this challenge, i.e., diversity measure and computation framework. First, we find that with existing diversity measures, visually indistinguishable policies can still yield high diversity scores. To accurately capture the behavioral difference, we propose to incorporate the state-space distance information into the diversity measure. In addition, we examine two common computation frameworks for this problem, i.e., population-based training (PBT) and iterative learning (ITR). We show that although PBT is the precise problem formulation, ITR can achieve comparable diversity scores with higher computation efficiency, leading to improved solution quality in practice. Based on our analysis, we further combine ITR with two tractable realizations of the state-distance-based diversity measures and develop a novel diversity-driven RL algorithm, State-based Intrinsic-reward Policy Optimization (SIPO), with provable convergence properties. We empirically examine SIPO across three domains from robot locomotion to multi-agent games. In all of our testing environments, SIPO consistently produces strategically diverse and human-interpretable policies that cannot be discovered by existing baselines.
Building Cooperative Embodied Agents Modularly with Large Language Models
Jul 05, 2023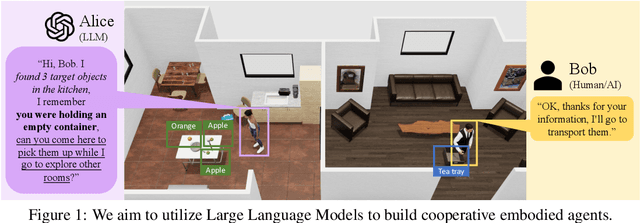

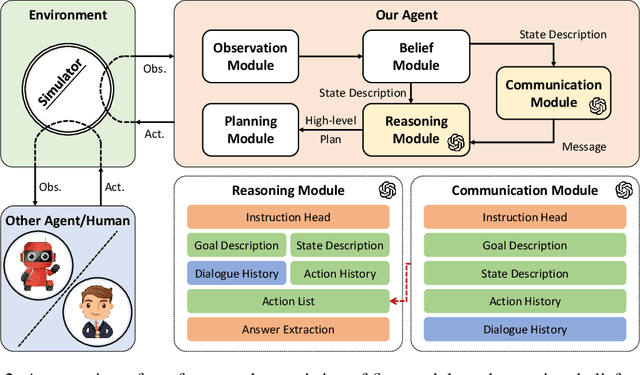
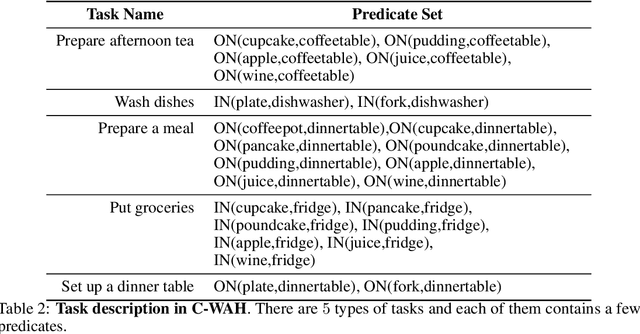
Large Language Models (LLMs) have demonstrated impressive planning abilities in single-agent embodied tasks across various domains. However, their capacity for planning and communication in multi-agent cooperation remains unclear, even though these are crucial skills for intelligent embodied agents. In this paper, we present a novel framework that utilizes LLMs for multi-agent cooperation and tests it in various embodied environments. Our framework enables embodied agents to plan, communicate, and cooperate with other embodied agents or humans to accomplish long-horizon tasks efficiently. We demonstrate that recent LLMs, such as GPT-4, can surpass strong planning-based methods and exhibit emergent effective communication using our framework without requiring fine-tuning or few-shot prompting. We also discover that LLM-based agents that communicate in natural language can earn more trust and cooperate more effectively with humans. Our research underscores the potential of LLMs for embodied AI and lays the foundation for future research in multi-agent cooperation. Videos can be found on the project website https://vis-www.cs.umass.edu/Co-LLM-Agents/.
Automatic Truss Design with Reinforcement Learning
Jun 27, 2023



Truss layout design, namely finding a lightweight truss layout satisfying all the physical constraints, is a fundamental problem in the building industry. Generating the optimal layout is a challenging combinatorial optimization problem, which can be extremely expensive to solve by exhaustive search. Directly applying end-to-end reinforcement learning (RL) methods to truss layout design is infeasible either, since only a tiny portion of the entire layout space is valid under the physical constraints, leading to particularly sparse rewards for RL training. In this paper, we develop AutoTruss, a two-stage framework to efficiently generate both lightweight and valid truss layouts. AutoTruss first adopts Monte Carlo tree search to discover a diverse collection of valid layouts. Then RL is applied to iteratively refine the valid solutions. We conduct experiments and ablation studies in popular truss layout design test cases in both 2D and 3D settings. AutoTruss outperforms the best-reported layouts by 25.1% in the most challenging 3D test cases, resulting in the first effective deep-RL-based approach in the truss layout design literature.