 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiangning Liu
InternLM2 Technical Report
Mar 26, 2024
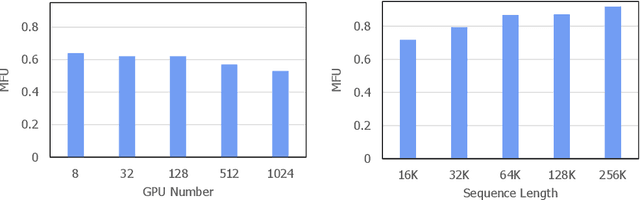
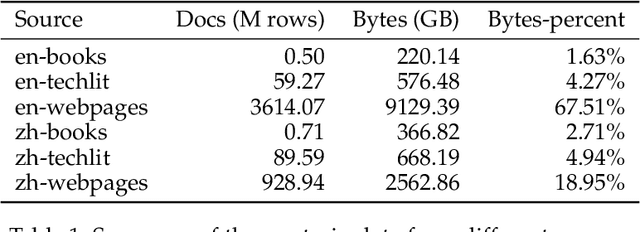


The evolution of Large Language Models (LLMs) like ChatGPT and GPT-4 has sparked discussions on the advent of Artificial General Intelligence (AGI). However, replicating such advancements in open-source models has been challenging. This paper introduces InternLM2, an open-source LLM that outperforms its predecessors in comprehensive evaluations across 6 dimensions and 30 benchmarks, long-context modeling, and open-ended subjective evaluations through innovative pre-training and optimization techniques. The pre-training process of InternLM2 is meticulously detailed, highlighting the preparation of diverse data types including text, code, and long-context data. InternLM2 efficiently captures long-term dependencies, initially trained on 4k tokens before advancing to 32k tokens in pre-training and fine-tuning stages, exhibiting remarkable performance on the 200k ``Needle-in-a-Haystack" test. InternLM2 is further aligned using Supervised Fine-Tuning (SFT) and a novel Conditional Online Reinforcement Learning from Human Feedback (COOL RLHF) strategy that addresses conflicting human preferences and reward hacking. By releasing InternLM2 models in different training stages and model sizes, we provide the community with insights into the model's evolution.
Agent-FLAN: Designing Data and Methods of Effective Agent Tuning for Large Language Models
Mar 19, 2024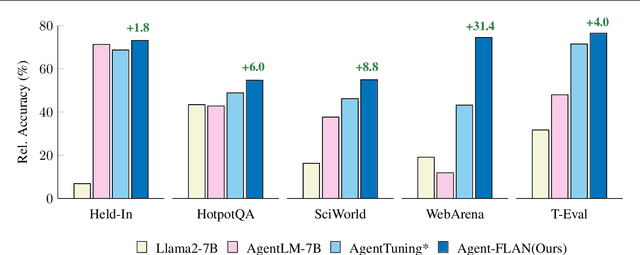
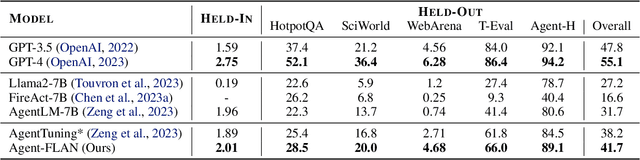
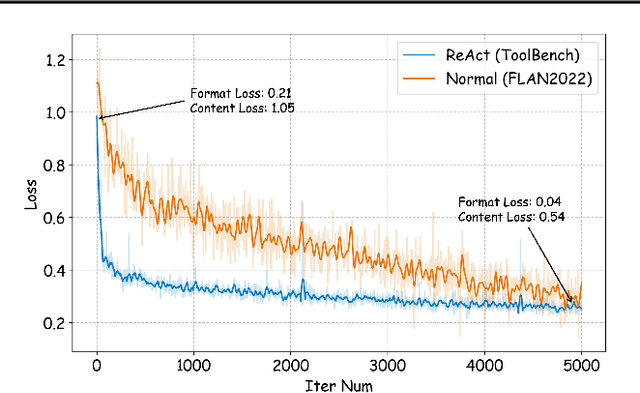
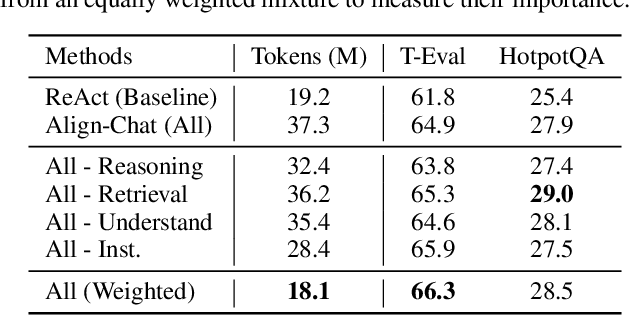
Open-sourced Large Language Models (LLMs) have achieved great success in various NLP tasks, however, they are still far inferior to API-based models when acting as agents. How to integrate agent ability into general LLMs becomes a crucial and urgent problem. This paper first delivers three key observations: (1) the current agent training corpus is entangled with both formats following and agent reasoning, which significantly shifts from the distribution of its pre-training data; (2) LLMs exhibit different learning speeds on the capabilities required by agent tasks; and (3) current approaches have side-effects when improving agent abilities by introducing hallucinations. Based on the above findings, we propose Agent-FLAN to effectively Fine-tune LANguage models for Agents. Through careful decomposition and redesign of the training corpus, Agent-FLAN enables Llama2-7B to outperform prior best works by 3.5\% across various agent evaluation datasets. With comprehensively constructed negative samples, Agent-FLAN greatly alleviates the hallucination issues based on our established evaluation benchmark. Besides, it consistently improves the agent capability of LLMs when scaling model sizes while slightly enhancing the general capability of LLMs. The code will be available at https://github.com/InternLM/Agent-FLAN.
T-Eval: Evaluating the Tool Utilization Capability of Large Language Models Step by Step
Jan 15, 2024Large language models (LLM) have achieved remarkable performance on various NLP tasks and are augmented by tools for broader applications. Yet, how to evaluate and analyze the tool-utilization capability of LLMs is still under-explored. In contrast to previous works that evaluate models holistically, we comprehensively decompose the tool utilization into multiple sub-processes, including instruction following, planning, reasoning, retrieval, understanding, and review. Based on that, we further introduce T-Eval to evaluate the tool utilization capability step by step. T-Eval disentangles the tool utilization evaluation into several sub-domains along model capabilities, facilitating the inner understanding of both holistic and isolated competency of LLMs. We conduct extensive experiments on T-Eval and in-depth analysis of various LLMs. T-Eval not only exhibits consistency with the outcome-oriented evaluation but also provides a more fine-grained analysis of the capabilities of LLMs, providing a new perspective in LLM evaluation on tool-utilization ability. The benchmark will be available at https://github.com/open-compass/T-Eval.
Action based Network for Conversation Question Reformulation
Nov 29, 2021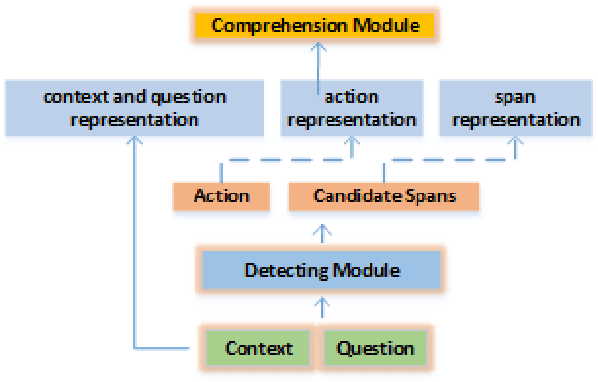
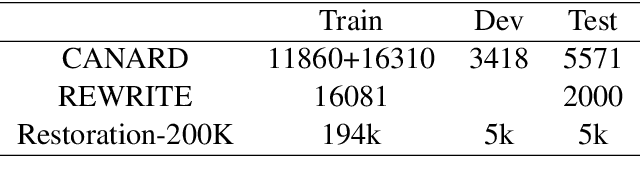

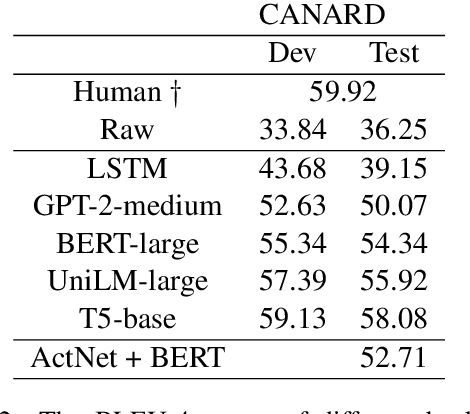
Conversation question answering requires the ability to interpret a question correctly. Current models, however, are still unsatisfactory due to the difficulty of understanding the co-references and ellipsis in daily conversation. Even though generative approaches achieved remarkable progress, they are still trapped by semantic incompleteness. This paper presents an action-based approach to recover the complete expression of the question. Specifically, we first locate the positions of co-reference or ellipsis in the question while assigning the corresponding action to each candidate span. We then look for matching phrases related to the candidate clues in the conversation context. Finally, according to the predicted action, we decide whether to replace the co-reference or supplement the ellipsis with the matched information. We demonstrate the effectiveness of our method on both English and Chinese utterance rewrite tasks, improving the state-of-the-art EM (exact match) by 3.9\% and ROUGE-L by 1.0\% respectively on the Restoration-200K dataset.