 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZiyi Wang
From ChatGPT, DALL-E 3 to Sora: How has Generative AI Changed Digital Humanities Research and Services?
Apr 29, 2024
Generative large-scale language models create the fifth paradigm of scientific research, organically combine data science and computational intelligence, transform the research paradigm of natural language processing and multimodal information processing, promote the new trend of AI-enabled social science research, and provide new ideas for digital humanities research and application. This article profoundly explores the application of large-scale language models in digital humanities research, revealing their significant potential in ancient book protection, intelligent processing, and academic innovation. The article first outlines the importance of ancient book resources and the necessity of digital preservation, followed by a detailed introduction to developing large-scale language models, such as ChatGPT, and their applications in document management, content understanding, and cross-cultural research. Through specific cases, the article demonstrates how AI can assist in the organization, classification, and content generation of ancient books. Then, it explores the prospects of AI applications in artistic innovation and cultural heritage preservation. Finally, the article explores the challenges and opportunities in the interaction of technology, information, and society in the digital humanities triggered by AI technologies.
FCNCP: A Coupled Nonnegative CANDECOMP/PARAFAC Decomposition Based on Federated Learning
Apr 18, 2024In the field of brain science, data sharing across servers is becoming increasingly challenging due to issues such as industry competition, privacy security, and administrative procedure policies and regulations. Therefore, there is an urgent need to develop new methods for data analysis and processing that enable scientific collaboration without data sharing. In view of this, this study proposes to study and develop a series of efficient non-negative coupled tensor decomposition algorithm frameworks based on federated learning called FCNCP for the EEG data arranged on different servers. It combining the good discriminative performance of tensor decomposition in high-dimensional data representation and decomposition, the advantages of coupled tensor decomposition in cross-sample tensor data analysis, and the features of federated learning for joint modelling in distributed servers. The algorithm utilises federation learning to establish coupling constraints for data distributed across different servers. In the experiments, firstly, simulation experiments are carried out using simulated data, and stable and consistent decomposition results are obtained, which verify the effectiveness of the proposed algorithms in this study. Then the FCNCP algorithm was utilised to decompose the fifth-order event-related potential (ERP) tensor data collected by applying proprioceptive stimuli on the left and right hands. It was found that contralateral stimulation induced more symmetrical components in the activation areas of the left and right hemispheres. The conclusions drawn are consistent with the interpretations of related studies in cognitive neuroscience, demonstrating that the method can efficiently process higher-order EEG data and that some key hidden information can be preserved.
RecDiffusion: Rectangling for Image Stitching with Diffusion Models
Mar 28, 2024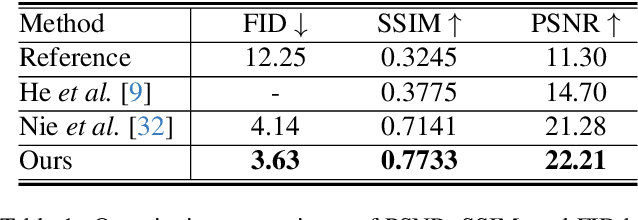

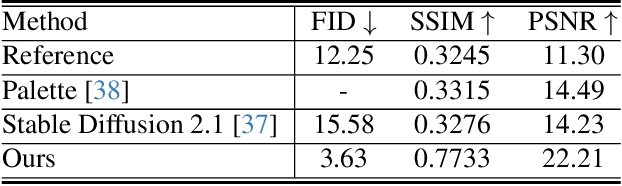
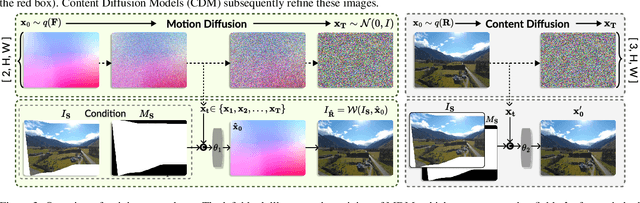
Image stitching from different captures often results in non-rectangular boundaries, which is often considered unappealing. To solve non-rectangular boundaries, current solutions involve cropping, which discards image content, inpainting, which can introduce unrelated content, or warping, which can distort non-linear features and introduce artifacts. To overcome these issues, we introduce a novel diffusion-based learning framework, \textbf{RecDiffusion}, for image stitching rectangling. This framework combines Motion Diffusion Models (MDM) to generate motion fields, effectively transitioning from the stitched image's irregular borders to a geometrically corrected intermediary. Followed by Content Diffusion Models (CDM) for image detail refinement. Notably, our sampling process utilizes a weighted map to identify regions needing correction during each iteration of CDM. Our RecDiffusion ensures geometric accuracy and overall visual appeal, surpassing all previous methods in both quantitative and qualitative measures when evaluated on public benchmarks. Code is released at https://github.com/lhaippp/RecDiffusion.
InternLM2 Technical Report
Mar 26, 2024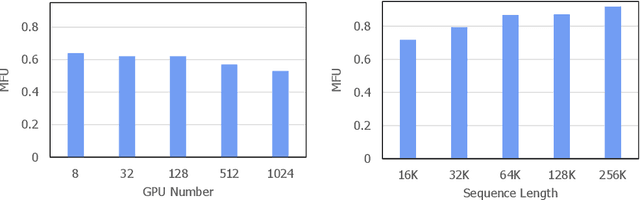


The evolution of Large Language Models (LLMs) like ChatGPT and GPT-4 has sparked discussions on the advent of Artificial General Intelligence (AGI). However, replicating such advancements in open-source models has been challenging. This paper introduces InternLM2, an open-source LLM that outperforms its predecessors in comprehensive evaluations across 6 dimensions and 30 benchmarks, long-context modeling, and open-ended subjective evaluations through innovative pre-training and optimization techniques. The pre-training process of InternLM2 is meticulously detailed, highlighting the preparation of diverse data types including text, code, and long-context data. InternLM2 efficiently captures long-term dependencies, initially trained on 4k tokens before advancing to 32k tokens in pre-training and fine-tuning stages, exhibiting remarkable performance on the 200k ``Needle-in-a-Haystack" test. InternLM2 is further aligned using Supervised Fine-Tuning (SFT) and a novel Conditional Online Reinforcement Learning from Human Feedback (COOL RLHF) strategy that addresses conflicting human preferences and reward hacking. By releasing InternLM2 models in different training stages and model sizes, we provide the community with insights into the model's evolution.
LaserHuman: Language-guided Scene-aware Human Motion Generation in Free Environment
Mar 21, 2024
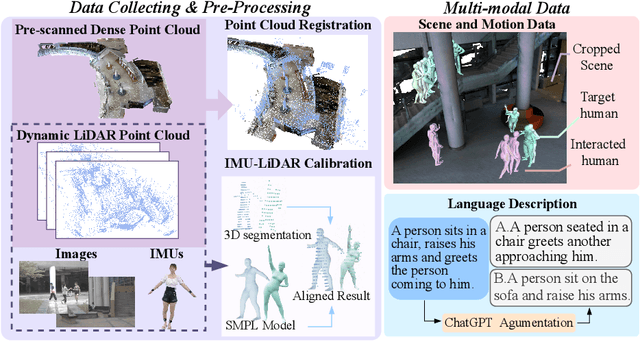
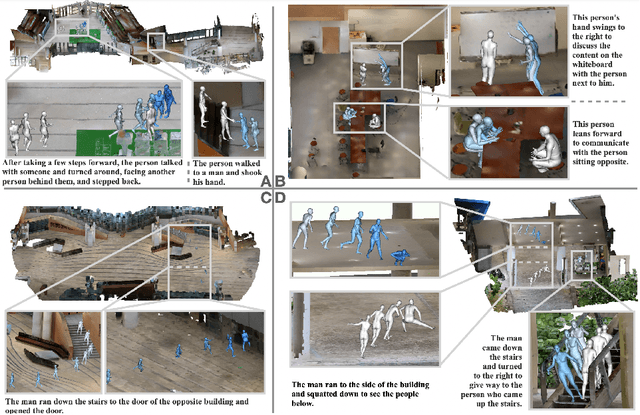
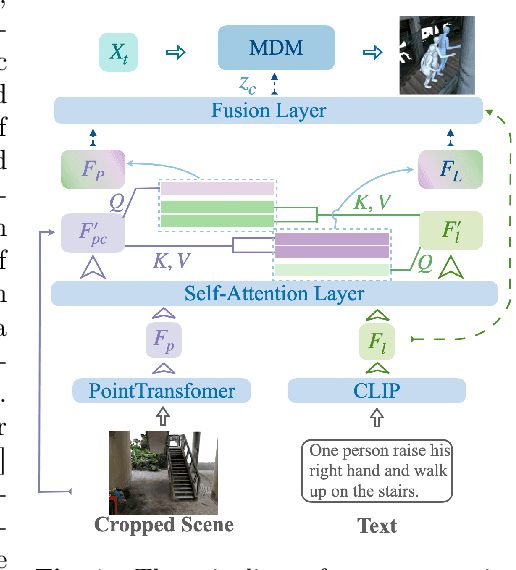
Language-guided scene-aware human motion generation has great significance for entertainment and robotics. In response to the limitations of existing datasets, we introduce LaserHuman, a pioneering dataset engineered to revolutionize Scene-Text-to-Motion research. LaserHuman stands out with its inclusion of genuine human motions within 3D environments, unbounded free-form natural language descriptions, a blend of indoor and outdoor scenarios, and dynamic, ever-changing scenes. Diverse modalities of capture data and rich annotations present great opportunities for the research of conditional motion generation, and can also facilitate the development of real-life applications. Moreover, to generate semantically consistent and physically plausible human motions, we propose a multi-conditional diffusion model, which is simple but effective, achieving state-of-the-art performance on existing datasets.
SelectIT: Selective Instruction Tuning for Large Language Models via Uncertainty-Aware Self-Reflection
Feb 26, 2024Instruction tuning (IT) is crucial to tailoring large language models (LLMs) towards human-centric interactions. Recent advancements have shown that the careful selection of a small, high-quality subset of IT data can significantly enhance the performance of LLMs. Despite this, common approaches often rely on additional models or data sets, which increases costs and limits widespread adoption. In this work, we propose a novel approach, termed SelectIT, that capitalizes on the foundational capabilities of the LLM itself. Specifically, we exploit the intrinsic uncertainty present in LLMs to more effectively select high-quality IT data, without the need for extra resources. Furthermore, we introduce a novel IT dataset, the Selective Alpaca, created by applying SelectIT to the Alpaca-GPT4 dataset. Empirical results demonstrate that IT using Selective Alpaca leads to substantial model ability enhancement. The robustness of SelectIT has also been corroborated in various foundation models and domain-specific tasks. Our findings suggest that longer and more computationally intensive IT data may serve as superior sources of IT, offering valuable insights for future research in this area. Data, code, and scripts are freely available at https://github.com/Blue-Raincoat/SelectIT.
InternLM-Math: Open Math Large Language Models Toward Verifiable Reasoning
Feb 09, 2024The math abilities of large language models can represent their abstract reasoning ability. In this paper, we introduce and open-source our math reasoning LLMs InternLM-Math which is continue pre-trained from InternLM2. We unify chain-of-thought reasoning, reward modeling, formal reasoning, data augmentation, and code interpreter in a unified seq2seq format and supervise our model to be a versatile math reasoner, verifier, prover, and augmenter. These abilities can be used to develop the next math LLMs or self-iteration. InternLM-Math obtains open-sourced state-of-the-art performance under the setting of in-context learning, supervised fine-tuning, and code-assisted reasoning in various informal and formal benchmarks including GSM8K, MATH, Hungary math exam, MathBench-ZH, and MiniF2F. Our pre-trained model achieves 30.3 on the MiniF2F test set without fine-tuning. We further explore how to use LEAN to solve math problems and study its performance under the setting of multi-task learning which shows the possibility of using LEAN as a unified platform for solving and proving in math. Our models, codes, and data are released at \url{https://github.com/InternLM/InternLM-Math}.
Enabling Mammography with Co-Robotic Ultrasound
Dec 16, 2023Ultrasound (US) imaging is a vital adjunct to mammography in breast cancer screening and diagnosis, but its reliance on hand-held transducers often lacks repeatability and heavily depends on sonographers' skills. Integrating US systems from different vendors further complicates clinical standards and workflows. This research introduces a co-robotic US platform for repeatable, accurate, and vendor-independent breast US image acquisition. The platform can autonomously perform 3D volume scans or swiftly acquire real-time 2D images of suspicious lesions. Utilizing a Universal Robot UR5 with an RGB camera, a force sensor, and an L7-4 linear array transducer, the system achieves autonomous navigation, motion control, and image acquisition. The calibrations, including camera-mammogram, robot-camera, and robot-US, were rigorously conducted and validated. Governed by a PID force control, the robot-held transducer maintains a constant contact force with the compression plate during the scan for safety and patient comfort. The framework was validated on a lesion-mimicking phantom. Our results indicate that the developed co-robotic US platform promises to enhance the precision and repeatability of breast cancer screening and diagnosis. Additionally, the platform offers straightforward integration into most mammographic devices to ensure vendor-independence.
GDN: A Stacking Network Used for Skin Cancer Diagnosis
Dec 05, 2023Skin cancer, the primary type of cancer that can be identified by visual recognition, requires an automatic identification system that can accurately classify different types of lesions. This paper presents GoogLe-Dense Network (GDN), which is an image-classification model to identify two types of skin cancer, Basal Cell Carcinoma, and Melanoma. GDN uses stacking of different networks to enhance the model performance. Specifically, GDN consists of two sequential levels in its structure. The first level performs basic classification tasks accomplished by GoogLeNet and DenseNet, which are trained in parallel to enhance efficiency. To avoid low accuracy and long training time, the second level takes the output of the GoogLeNet and DenseNet as the input for a logistic regression model. We compare our method with four baseline networks including ResNet, VGGNet, DenseNet, and GoogLeNet on the dataset, in which GoogLeNet and DenseNet significantly outperform ResNet and VGGNet. In the second level, different stacking methods such as perceptron, logistic regression, SVM, decision trees and K-neighbor are studied in which Logistic Regression shows the best prediction result among all. The results prove that GDN, compared to a single network structure, has higher accuracy in optimizing skin cancer detection.
Enhancing Low-Precision Sampling via Stochastic Gradient Hamiltonian Monte Carlo
Oct 25, 2023Low-precision training has emerged as a promising low-cost technique to enhance the training efficiency of deep neural networks without sacrificing much accuracy. Its Bayesian counterpart can further provide uncertainty quantification and improved generalization accuracy. This paper investigates low-precision sampling via Stochastic Gradient Hamiltonian Monte Carlo (SGHMC) with low-precision and full-precision gradient accumulators for both strongly log-concave and non-log-concave distributions. Theoretically, our results show that, to achieve $\epsilon$-error in the 2-Wasserstein distance for non-log-concave distributions, low-precision SGHMC achieves quadratic improvement ($\widetilde{\mathbf{O}}\left({\epsilon^{-2}{\mu^*}^{-2}\log^2\left({\epsilon^{-1}}\right)}\right)$) compared to the state-of-the-art low-precision sampler, Stochastic Gradient Langevin Dynamics (SGLD) ($\widetilde{\mathbf{O}}\left({{\epsilon}^{-4}{\lambda^{*}}^{-1}\log^5\left({\epsilon^{-1}}\right)}\right)$). Moreover, we prove that low-precision SGHMC is more robust to the quantization error compared to low-precision SGLD due to the robustness of the momentum-based update w.r.t. gradient noise. Empirically, we conduct experiments on synthetic data, and {MNIST, CIFAR-10 \& CIFAR-100} datasets, which validate our theoretical findings. Our study highlights the potential of low-precision SGHMC as an efficient and accurate sampling method for large-scale and resource-limited machine learning.