 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuexin Ma
A Unified Framework for Human-centric Point Cloud Video Understanding
Mar 29, 2024
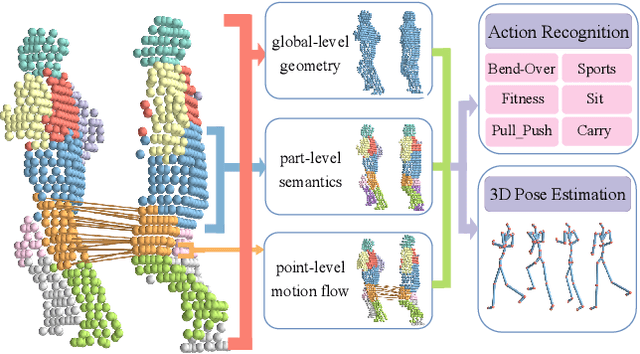

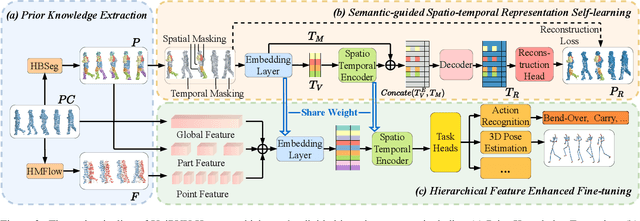

Human-centric Point Cloud Video Understanding (PVU) is an emerging field focused on extracting and interpreting human-related features from sequences of human point clouds, further advancing downstream human-centric tasks and applications. Previous works usually focus on tackling one specific task and rely on huge labeled data, which has poor generalization capability. Considering that human has specific characteristics, including the structural semantics of human body and the dynamics of human motions, we propose a unified framework to make full use of the prior knowledge and explore the inherent features in the data itself for generalized human-centric point cloud video understanding. Extensive experiments demonstrate that our method achieves state-of-the-art performance on various human-related tasks, including action recognition and 3D pose estimation. All datasets and code will be released soon.
RELI11D: A Comprehensive Multimodal Human Motion Dataset and Method
Mar 28, 2024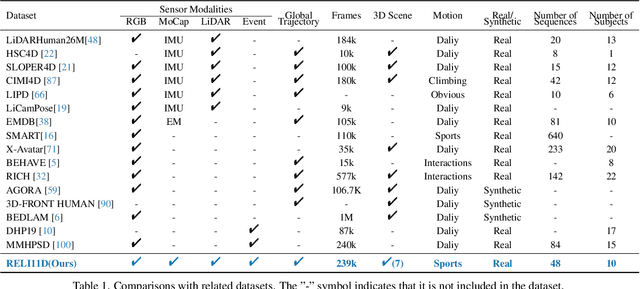

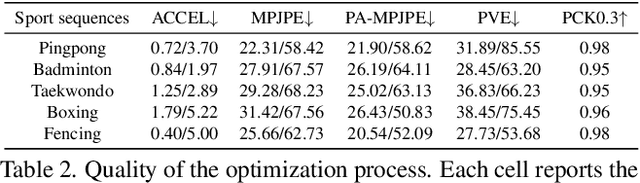

Comprehensive capturing of human motions requires both accurate captures of complex poses and precise localization of the human within scenes. Most of the HPE datasets and methods primarily rely on RGB, LiDAR, or IMU data. However, solely using these modalities or a combination of them may not be adequate for HPE, particularly for complex and fast movements. For holistic human motion understanding, we present RELI11D, a high-quality multimodal human motion dataset involves LiDAR, IMU system, RGB camera, and Event camera. It records the motions of 10 actors performing 5 sports in 7 scenes, including 3.32 hours of synchronized LiDAR point clouds, IMU measurement data, RGB videos and Event steams. Through extensive experiments, we demonstrate that the RELI11D presents considerable challenges and opportunities as it contains many rapid and complex motions that require precise location. To address the challenge of integrating different modalities, we propose LEIR, a multimodal baseline that effectively utilizes LiDAR Point Cloud, Event stream, and RGB through our cross-attention fusion strategy. We show that LEIR exhibits promising results for rapid motions and daily motions and that utilizing the characteristics of multiple modalities can indeed improve HPE performance. Both the dataset and source code will be released publicly to the research community, fostering collaboration and enabling further exploration in this field.
Gaze-guided Hand-Object Interaction Synthesis: Benchmark and Method
Mar 28, 2024Gaze plays a crucial role in revealing human attention and intention, shedding light on the cognitive processes behind human actions. The integration of gaze guidance with the dynamics of hand-object interactions boosts the accuracy of human motion prediction. However, the lack of datasets that capture the intricate relationship and consistency among gaze, hand, and object movements remains a substantial hurdle. In this paper, we introduce the first Gaze-guided Hand-Object Interaction dataset, GazeHOI, and present a novel task for synthesizing gaze-guided hand-object interactions. Our dataset, GazeHOI, features simultaneous 3D modeling of gaze, hand, and object interactions, comprising 479 sequences with an average duration of 19.1 seconds, 812 sub-sequences, and 33 objects of various sizes. We propose a hierarchical framework centered on a gaze-guided hand-object interaction diffusion model, named GHO-Diffusion. In the pre-diffusion phase, we separate gaze conditions into spatial-temporal features and goal pose conditions at different levels of information granularity. During the diffusion phase, two gaze-conditioned diffusion models are stacked to simplify the complex synthesis of hand-object motions. Here, the object motion diffusion model generates sequences of object motions based on gaze conditions, while the hand motion diffusion model produces hand motions based on the generated object motion. To improve fine-grained goal pose alignment, we introduce a Spherical Gaussian constraint to guide the denoising step. In the subsequent post-diffusion phase, we optimize the generated hand motions using contact consistency. Our extensive experiments highlight the uniqueness of our dataset and the effectiveness of our approach.
LaserHuman: Language-guided Scene-aware Human Motion Generation in Free Environment
Mar 21, 2024
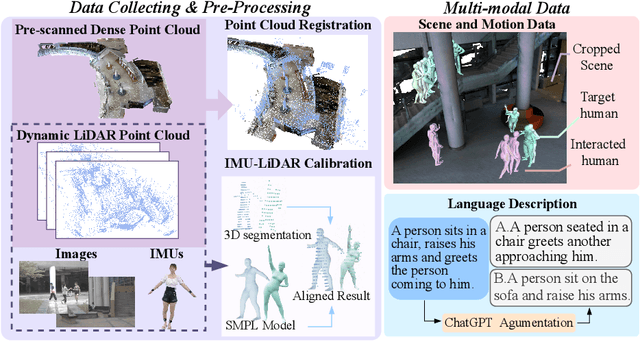
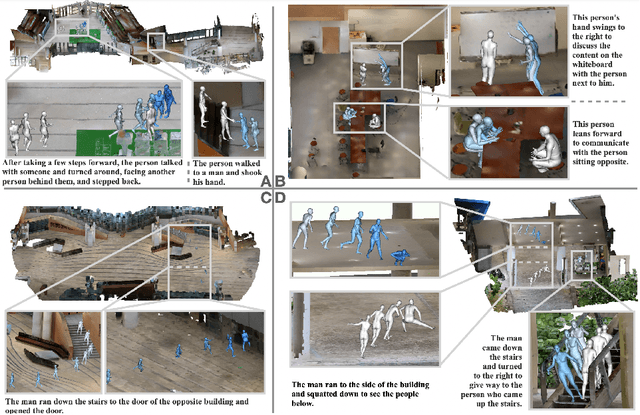
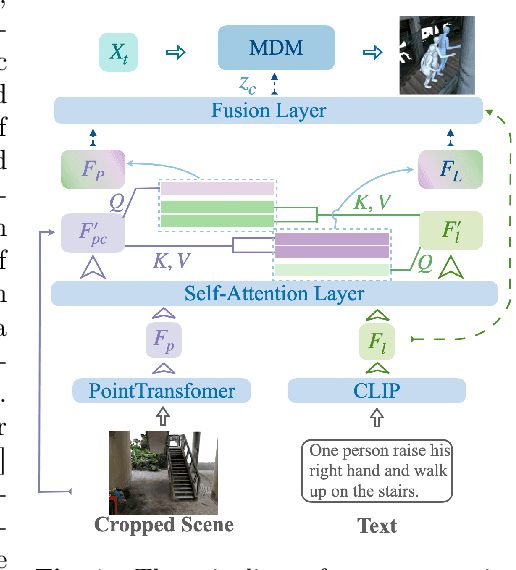
Language-guided scene-aware human motion generation has great significance for entertainment and robotics. In response to the limitations of existing datasets, we introduce LaserHuman, a pioneering dataset engineered to revolutionize Scene-Text-to-Motion research. LaserHuman stands out with its inclusion of genuine human motions within 3D environments, unbounded free-form natural language descriptions, a blend of indoor and outdoor scenarios, and dynamic, ever-changing scenes. Diverse modalities of capture data and rich annotations present great opportunities for the research of conditional motion generation, and can also facilitate the development of real-life applications. Moreover, to generate semantically consistent and physically plausible human motions, we propose a multi-conditional diffusion model, which is simple but effective, achieving state-of-the-art performance on existing datasets.
GeoWizard: Unleashing the Diffusion Priors for 3D Geometry Estimation from a Single Image
Mar 18, 2024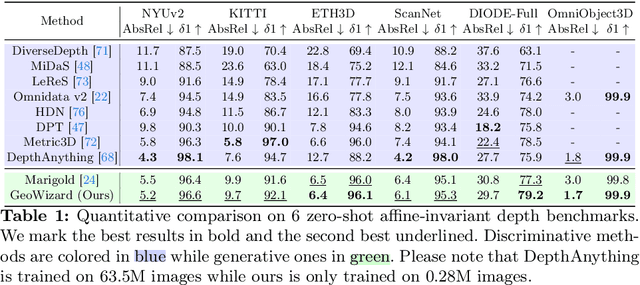
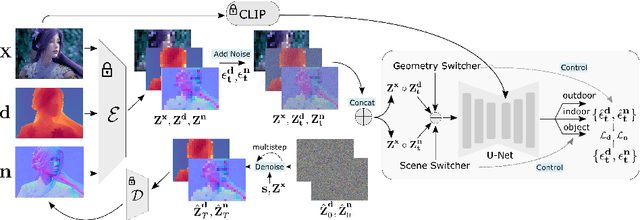

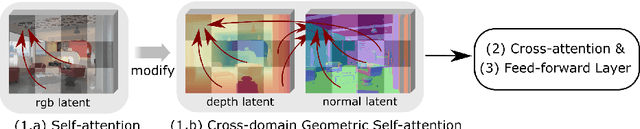
We introduce GeoWizard, a new generative foundation model designed for estimating geometric attributes, e.g., depth and normals, from single images. While significant research has already been conducted in this area, the progress has been substantially limited by the low diversity and poor quality of publicly available datasets. As a result, the prior works either are constrained to limited scenarios or suffer from the inability to capture geometric details. In this paper, we demonstrate that generative models, as opposed to traditional discriminative models (e.g., CNNs and Transformers), can effectively address the inherently ill-posed problem. We further show that leveraging diffusion priors can markedly improve generalization, detail preservation, and efficiency in resource usage. Specifically, we extend the original stable diffusion model to jointly predict depth and normal, allowing mutual information exchange and high consistency between the two representations. More importantly, we propose a simple yet effective strategy to segregate the complex data distribution of various scenes into distinct sub-distributions. This strategy enables our model to recognize different scene layouts, capturing 3D geometry with remarkable fidelity. GeoWizard sets new benchmarks for zero-shot depth and normal prediction, significantly enhancing many downstream applications such as 3D reconstruction, 2D content creation, and novel viewpoint synthesis.
HUNTER: Unsupervised Human-centric 3D Detection via Transferring Knowledge from Synthetic Instances to Real Scenes
Mar 15, 2024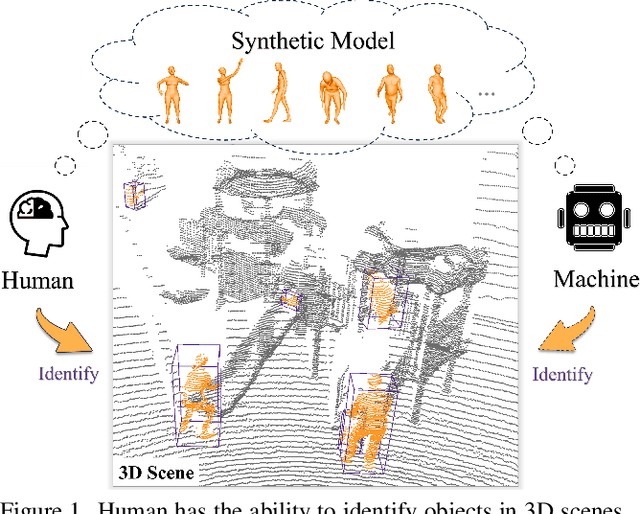

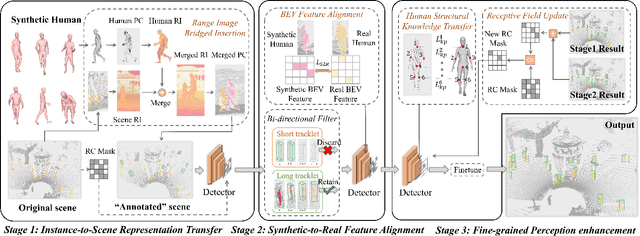

Human-centric 3D scene understanding has recently drawn increasing attention, driven by its critical impact on robotics. However, human-centric real-life scenarios are extremely diverse and complicated, and humans have intricate motions and interactions. With limited labeled data, supervised methods are difficult to generalize to general scenarios, hindering real-life applications. Mimicking human intelligence, we propose an unsupervised 3D detection method for human-centric scenarios by transferring the knowledge from synthetic human instances to real scenes. To bridge the gap between the distinct data representations and feature distributions of synthetic models and real point clouds, we introduce novel modules for effective instance-to-scene representation transfer and synthetic-to-real feature alignment. Remarkably, our method exhibits superior performance compared to current state-of-the-art techniques, achieving 87.8% improvement in mAP and closely approaching the performance of fully supervised methods (62.15 mAP vs. 69.02 mAP) on HuCenLife Dataset.
LiveHPS: LiDAR-based Scene-level Human Pose and Shape Estimation in Free Environment
Feb 27, 2024For human-centric large-scale scenes, fine-grained modeling for 3D human global pose and shape is significant for scene understanding and can benefit many real-world applications. In this paper, we present LiveHPS, a novel single-LiDAR-based approach for scene-level human pose and shape estimation without any limitation of light conditions and wearable devices. In particular, we design a distillation mechanism to mitigate the distribution-varying effect of LiDAR point clouds and exploit the temporal-spatial geometric and dynamic information existing in consecutive frames to solve the occlusion and noise disturbance. LiveHPS, with its efficient configuration and high-quality output, is well-suited for real-world applications. Moreover, we propose a huge human motion dataset, named FreeMotion, which is collected in various scenarios with diverse human poses, shapes and translations. It consists of multi-modal and multi-view acquisition data from calibrated and synchronized LiDARs, cameras, and IMUs. Extensive experiments on our new dataset and other public datasets demonstrate the SOTA performance and robustness of our approach. We will release our code and dataset soon.
GaussianPro: 3D Gaussian Splatting with Progressive Propagation
Feb 22, 2024The advent of 3D Gaussian Splatting (3DGS) has recently brought about a revolution in the field of neural rendering, facilitating high-quality renderings at real-time speed. However, 3DGS heavily depends on the initialized point cloud produced by Structure-from-Motion (SfM) techniques. When tackling with large-scale scenes that unavoidably contain texture-less surfaces, the SfM techniques always fail to produce enough points in these surfaces and cannot provide good initialization for 3DGS. As a result, 3DGS suffers from difficult optimization and low-quality renderings. In this paper, inspired by classical multi-view stereo (MVS) techniques, we propose GaussianPro, a novel method that applies a progressive propagation strategy to guide the densification of the 3D Gaussians. Compared to the simple split and clone strategies used in 3DGS, our method leverages the priors of the existing reconstructed geometries of the scene and patch matching techniques to produce new Gaussians with accurate positions and orientations. Experiments on both large-scale and small-scale scenes validate the effectiveness of our method, where our method significantly surpasses 3DGS on the Waymo dataset, exhibiting an improvement of 1.15dB in terms of PSNR.
RealDex: Towards Human-like Grasping for Robotic Dexterous Hand
Feb 21, 2024In this paper, we introduce RealDex, a pioneering dataset capturing authentic dexterous hand grasping motions infused with human behavioral patterns, enriched by multi-view and multimodal visual data. Utilizing a teleoperation system, we seamlessly synchronize human-robot hand poses in real time. This collection of human-like motions is crucial for training dexterous hands to mimic human movements more naturally and precisely. RealDex holds immense promise in advancing humanoid robot for automated perception, cognition, and manipulation in real-world scenarios. Moreover, we introduce a cutting-edge dexterous grasping motion generation framework, which aligns with human experience and enhances real-world applicability through effectively utilizing Multimodal Large Language Models. Extensive experiments have demonstrated the superior performance of our method on RealDex and other open datasets. The complete dataset and code will be made available upon the publication of this work.