 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaofei Wu
Co-Speech Gesture Video Generation via Motion-Decoupled Diffusion Model
Apr 02, 2024
Co-speech gestures, if presented in the lively form of videos, can achieve superior visual effects in human-machine interaction. While previous works mostly generate structural human skeletons, resulting in the omission of appearance information, we focus on the direct generation of audio-driven co-speech gesture videos in this work. There are two main challenges: 1) A suitable motion feature is needed to describe complex human movements with crucial appearance information. 2) Gestures and speech exhibit inherent dependencies and should be temporally aligned even of arbitrary length. To solve these problems, we present a novel motion-decoupled framework to generate co-speech gesture videos. Specifically, we first introduce a well-designed nonlinear TPS transformation to obtain latent motion features preserving essential appearance information. Then a transformer-based diffusion model is proposed to learn the temporal correlation between gestures and speech, and performs generation in the latent motion space, followed by an optimal motion selection module to produce long-term coherent and consistent gesture videos. For better visual perception, we further design a refinement network focusing on missing details of certain areas. Extensive experimental results show that our proposed framework significantly outperforms existing approaches in both motion and video-related evaluations. Our code, demos, and more resources are available at https://github.com/thuhcsi/S2G-MDDiffusion.
VastGaussian: Vast 3D Gaussians for Large Scene Reconstruction
Feb 27, 2024Existing NeRF-based methods for large scene reconstruction often have limitations in visual quality and rendering speed. While the recent 3D Gaussian Splatting works well on small-scale and object-centric scenes, scaling it up to large scenes poses challenges due to limited video memory, long optimization time, and noticeable appearance variations. To address these challenges, we present VastGaussian, the first method for high-quality reconstruction and real-time rendering on large scenes based on 3D Gaussian Splatting. We propose a progressive partitioning strategy to divide a large scene into multiple cells, where the training cameras and point cloud are properly distributed with an airspace-aware visibility criterion. These cells are merged into a complete scene after parallel optimization. We also introduce decoupled appearance modeling into the optimization process to reduce appearance variations in the rendered images. Our approach outperforms existing NeRF-based methods and achieves state-of-the-art results on multiple large scene datasets, enabling fast optimization and high-fidelity real-time rendering.
RealDex: Towards Human-like Grasping for Robotic Dexterous Hand
Feb 21, 2024In this paper, we introduce RealDex, a pioneering dataset capturing authentic dexterous hand grasping motions infused with human behavioral patterns, enriched by multi-view and multimodal visual data. Utilizing a teleoperation system, we seamlessly synchronize human-robot hand poses in real time. This collection of human-like motions is crucial for training dexterous hands to mimic human movements more naturally and precisely. RealDex holds immense promise in advancing humanoid robot for automated perception, cognition, and manipulation in real-world scenarios. Moreover, we introduce a cutting-edge dexterous grasping motion generation framework, which aligns with human experience and enhances real-world applicability through effectively utilizing Multimodal Large Language Models. Extensive experiments have demonstrated the superior performance of our method on RealDex and other open datasets. The complete dataset and code will be made available upon the publication of this work.
YAYI 2: Multilingual Open-Source Large Language Models
Dec 22, 2023As the latest advancements in natural language processing, large language models (LLMs) have achieved human-level language understanding and generation abilities in many real-world tasks, and even have been regarded as a potential path to the artificial general intelligence. To better facilitate research on LLMs, many open-source LLMs, such as Llama 2 and Falcon, have recently been proposed and gained comparable performances to proprietary models. However, these models are primarily designed for English scenarios and exhibit poor performances in Chinese contexts. In this technical report, we propose YAYI 2, including both base and chat models, with 30 billion parameters. YAYI 2 is pre-trained from scratch on a multilingual corpus which contains 2.65 trillion tokens filtered by our pre-training data processing pipeline. The base model is aligned with human values through supervised fine-tuning with millions of instructions and reinforcement learning from human feedback. Extensive experiments on multiple benchmarks, such as MMLU and CMMLU, consistently demonstrate that the proposed YAYI 2 outperforms other similar sized open-source models.
Semantics-aware Motion Retargeting with Vision-Language Models
Dec 04, 2023Capturing and preserving motion semantics is essential to motion retargeting between animation characters. However, most of the previous works neglect the semantic information or rely on human-designed joint-level representations. Here, we present a novel Semantics-aware Motion reTargeting (SMT) method with the advantage of vision-language models to extract and maintain meaningful motion semantics. We utilize a differentiable module to render 3D motions. Then the high-level motion semantics are incorporated into the motion retargeting process by feeding the vision-language model with the rendered images and aligning the extracted semantic embeddings. To ensure the preservation of fine-grained motion details and high-level semantics, we adopt a two-stage pipeline consisting of skeleton-aware pre-training and fine-tuning with semantics and geometry constraints. Experimental results show the effectiveness of the proposed method in producing high-quality motion retargeting results while accurately preserving motion semantics. Project page can be found at https://sites.google.com/view/smtnet.
A unified consensus-based parallel ADMM algorithm for high-dimensional regression with combined regularizations
Nov 21, 2023
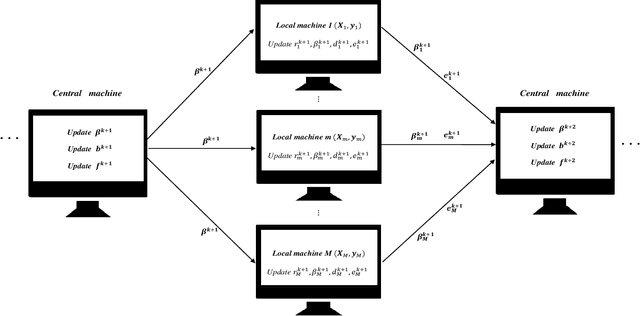

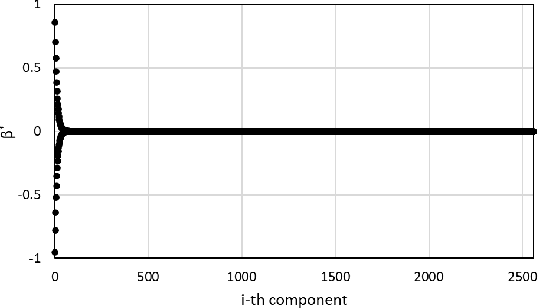
The parallel alternating direction method of multipliers (ADMM) algorithm is widely recognized for its effectiveness in handling large-scale datasets stored in a distributed manner, making it a popular choice for solving statistical learning models. However, there is currently limited research on parallel algorithms specifically designed for high-dimensional regression with combined (composite) regularization terms. These terms, such as elastic-net, sparse group lasso, sparse fused lasso, and their nonconvex variants, have gained significant attention in various fields due to their ability to incorporate prior information and promote sparsity within specific groups or fused variables. The scarcity of parallel algorithms for combined regularizations can be attributed to the inherent nonsmoothness and complexity of these terms, as well as the absence of closed-form solutions for certain proximal operators associated with them. In this paper, we propose a unified constrained optimization formulation based on the consensus problem for these types of convex and nonconvex regression problems and derive the corresponding parallel ADMM algorithms. Furthermore, we prove that the proposed algorithm not only has global convergence but also exhibits linear convergence rate. Extensive simulation experiments, along with a financial example, serve to demonstrate the reliability, stability, and scalability of our algorithm. The R package for implementing the proposed algorithms can be obtained at https://github.com/xfwu1016/CPADMM.
UnifiedGesture: A Unified Gesture Synthesis Model for Multiple Skeletons
Sep 13, 2023The automatic co-speech gesture generation draws much attention in computer animation. Previous works designed network structures on individual datasets, which resulted in a lack of data volume and generalizability across different motion capture standards. In addition, it is a challenging task due to the weak correlation between speech and gestures. To address these problems, we present UnifiedGesture, a novel diffusion model-based speech-driven gesture synthesis approach, trained on multiple gesture datasets with different skeletons. Specifically, we first present a retargeting network to learn latent homeomorphic graphs for different motion capture standards, unifying the representations of various gestures while extending the dataset. We then capture the correlation between speech and gestures based on a diffusion model architecture using cross-local attention and self-attention to generate better speech-matched and realistic gestures. To further align speech and gesture and increase diversity, we incorporate reinforcement learning on the discrete gesture units with a learned reward function. Extensive experiments show that UnifiedGesture outperforms recent approaches on speech-driven gesture generation in terms of CCA, FGD, and human-likeness. All code, pre-trained models, databases, and demos are available to the public at https://github.com/YoungSeng/UnifiedGesture.
The DiffuseStyleGesture+ entry to the GENEA Challenge 2023
Aug 26, 2023
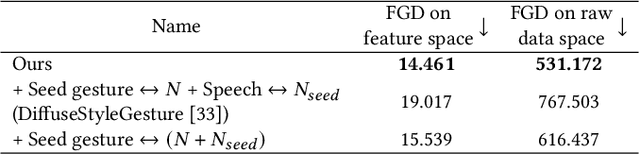
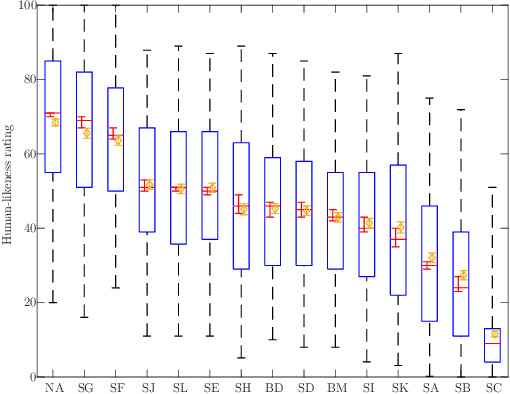
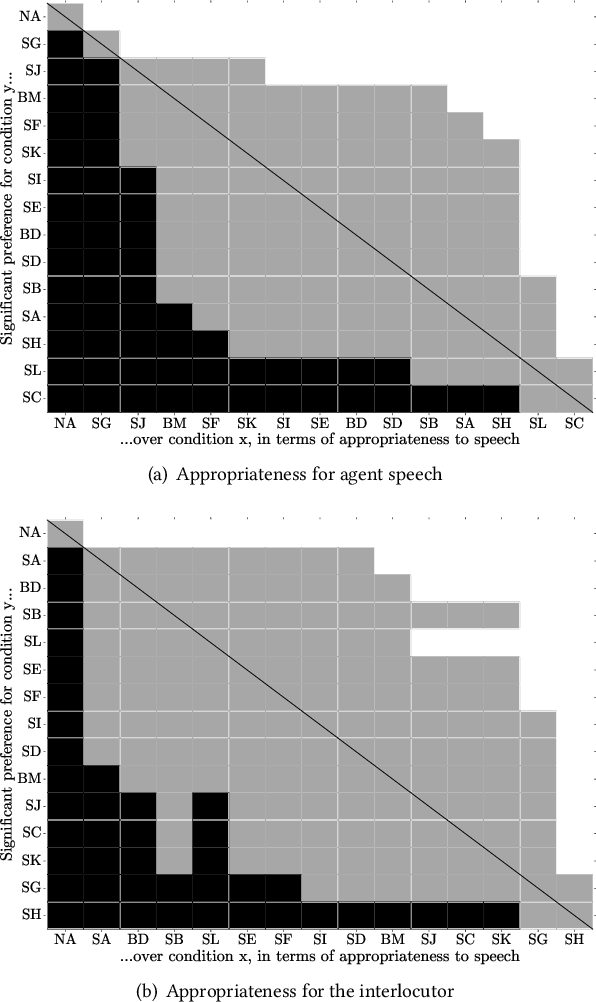
In this paper, we introduce the DiffuseStyleGesture+, our solution for the Generation and Evaluation of Non-verbal Behavior for Embodied Agents (GENEA) Challenge 2023, which aims to foster the development of realistic, automated systems for generating conversational gestures. Participants are provided with a pre-processed dataset and their systems are evaluated through crowdsourced scoring. Our proposed model, DiffuseStyleGesture+, leverages a diffusion model to generate gestures automatically. It incorporates a variety of modalities, including audio, text, speaker ID, and seed gestures. These diverse modalities are mapped to a hidden space and processed by a modified diffusion model to produce the corresponding gesture for a given speech input. Upon evaluation, the DiffuseStyleGesture+ demonstrated performance on par with the top-tier models in the challenge, showing no significant differences with those models in human-likeness, appropriateness for the interlocutor, and achieving competitive performance with the best model on appropriateness for agent speech. This indicates that our model is competitive and effective in generating realistic and appropriate gestures for given speech. The code, pre-trained models, and demos are available at https://github.com/YoungSeng/DiffuseStyleGesture/tree/DiffuseStyleGesturePlus/BEAT-TWH-main.
High-Order Residual Network for Light Field Super-Resolution
Mar 29, 2020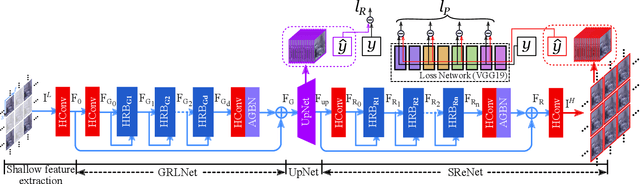
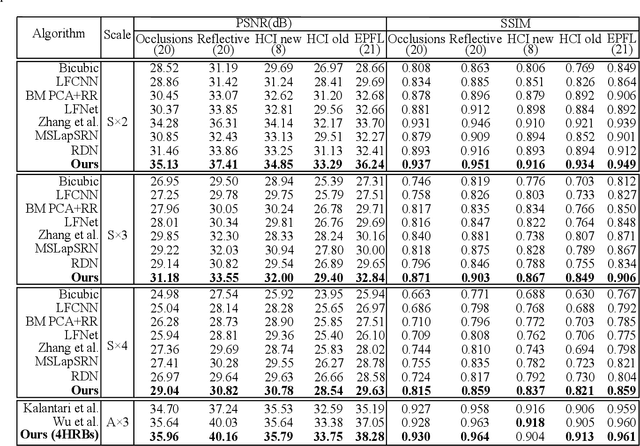
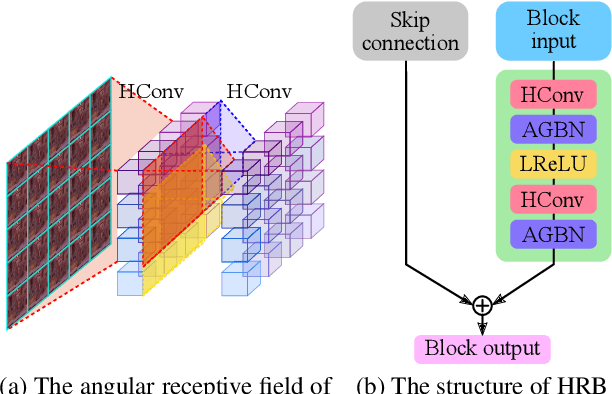
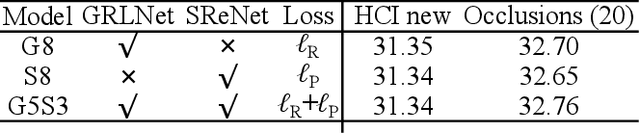
Plenoptic cameras usually sacrifice the spatial resolution of their SAIs to acquire geometry information from different viewpoints. Several methods have been proposed to mitigate such spatio-angular trade-off, but seldom make use of the structural properties of the light field (LF) data efficiently. In this paper, we propose a novel high-order residual network to learn the geometric features hierarchically from the LF for reconstruction. An important component in the proposed network is the high-order residual block (HRB), which learns the local geometric features by considering the information from all input views. After fully obtaining the local features learned from each HRB, our model extracts the representative geometric features for spatio-angular upsampling through the global residual learning. Additionally, a refinement network is followed to further enhance the spatial details by minimizing a perceptual loss. Compared with previous work, our model is tailored to the rich structure inherent in the LF, and therefore can reduce the artifacts near non-Lambertian and occlusion regions. Experimental results show that our approach enables high-quality reconstruction even in challenging regions and outperforms state-of-the-art single image or LF reconstruction methods with both quantitative measurements and visual evaluation.