 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhiwei Lin
Co-Speech Gesture Video Generation via Motion-Decoupled Diffusion Model
Apr 02, 2024
Co-speech gestures, if presented in the lively form of videos, can achieve superior visual effects in human-machine interaction. While previous works mostly generate structural human skeletons, resulting in the omission of appearance information, we focus on the direct generation of audio-driven co-speech gesture videos in this work. There are two main challenges: 1) A suitable motion feature is needed to describe complex human movements with crucial appearance information. 2) Gestures and speech exhibit inherent dependencies and should be temporally aligned even of arbitrary length. To solve these problems, we present a novel motion-decoupled framework to generate co-speech gesture videos. Specifically, we first introduce a well-designed nonlinear TPS transformation to obtain latent motion features preserving essential appearance information. Then a transformer-based diffusion model is proposed to learn the temporal correlation between gestures and speech, and performs generation in the latent motion space, followed by an optimal motion selection module to produce long-term coherent and consistent gesture videos. For better visual perception, we further design a refinement network focusing on missing details of certain areas. Extensive experimental results show that our proposed framework significantly outperforms existing approaches in both motion and video-related evaluations. Our code, demos, and more resources are available at https://github.com/thuhcsi/S2G-MDDiffusion.
RCBEVDet: Radar-camera Fusion in Bird's Eye View for 3D Object Detection
Mar 25, 2024Three-dimensional object detection is one of the key tasks in autonomous driving. To reduce costs in practice, low-cost multi-view cameras for 3D object detection are proposed to replace the expansive LiDAR sensors. However, relying solely on cameras is difficult to achieve highly accurate and robust 3D object detection. An effective solution to this issue is combining multi-view cameras with the economical millimeter-wave radar sensor to achieve more reliable multi-modal 3D object detection. In this paper, we introduce RCBEVDet, a radar-camera fusion 3D object detection method in the bird's eye view (BEV). Specifically, we first design RadarBEVNet for radar BEV feature extraction. RadarBEVNet consists of a dual-stream radar backbone and a Radar Cross-Section (RCS) aware BEV encoder. In the dual-stream radar backbone, a point-based encoder and a transformer-based encoder are proposed to extract radar features, with an injection and extraction module to facilitate communication between the two encoders. The RCS-aware BEV encoder takes RCS as the object size prior to scattering the point feature in BEV. Besides, we present the Cross-Attention Multi-layer Fusion module to automatically align the multi-modal BEV feature from radar and camera with the deformable attention mechanism, and then fuse the feature with channel and spatial fusion layers. Experimental results show that RCBEVDet achieves new state-of-the-art radar-camera fusion results on nuScenes and view-of-delft (VoD) 3D object detection benchmarks. Furthermore, RCBEVDet achieves better 3D detection results than all real-time camera-only and radar-camera 3D object detectors with a faster inference speed at 21~28 FPS. The source code will be released at https://github.com/VDIGPKU/RCBEVDet.
Few-Shot Adversarial Prompt Learning on Vision-Language Models
Mar 21, 2024The vulnerability of deep neural networks to imperceptible adversarial perturbations has attracted widespread attention. Inspired by the success of vision-language foundation models, previous efforts achieved zero-shot adversarial robustness by aligning adversarial visual features with text supervision. However, in practice, they are still unsatisfactory due to several issues, including heavy adaptation cost, suboptimal text supervision, and uncontrolled natural generalization capacity. In this paper, to address these issues, we propose a few-shot adversarial prompt framework where adapting input sequences with limited data makes significant adversarial robustness improvement. Specifically, we achieve this by providing adversarially correlated text supervision that is end-to-end learned from adversarial examples. We also propose a novel training objective that enhances the consistency of multi-modal features while encourages differentiated uni-modal features between natural and adversarial examples. The proposed framework gives access to learn adversarial text supervision, which provides superior cross-modal adversarial alignment and matches state-of-the-art zero-shot adversarial robustness with only 1% training data.
GALA3D: Towards Text-to-3D Complex Scene Generation via Layout-guided Generative Gaussian Splatting
Feb 11, 2024We present GALA3D, generative 3D GAussians with LAyout-guided control, for effective compositional text-to-3D generation. We first utilize large language models (LLMs) to generate the initial layout and introduce a layout-guided 3D Gaussian representation for 3D content generation with adaptive geometric constraints. We then propose an object-scene compositional optimization mechanism with conditioned diffusion to collaboratively generate realistic 3D scenes with consistent geometry, texture, scale, and accurate interactions among multiple objects while simultaneously adjusting the coarse layout priors extracted from the LLMs to align with the generated scene. Experiments show that GALA3D is a user-friendly, end-to-end framework for state-of-the-art scene-level 3D content generation and controllable editing while ensuring the high fidelity of object-level entities within the scene. Source codes and models will be available at https://gala3d.github.io/.
LCVO: An Efficient Pretraining-Free Framework for Visual Question Answering Grounding
Jan 29, 2024In this paper, the LCVO modular method is proposed for the Visual Question Answering (VQA) Grounding task in the vision-language multimodal domain. This approach relies on a frozen large language model (LLM) as intermediate mediator between the off-the-shelf VQA model and the off-the-shelf Open-Vocabulary Object Detection (OVD) model, where the LLM transforms and conveys textual information between the two modules based on a designed prompt. LCVO establish an integrated plug-and-play framework without the need for any pre-training process. This framework can be deployed for VQA Grounding tasks under low computational resources. The modularized model within the framework allows application with various state-of-the-art pre-trained models, exhibiting significant potential to be advance with the times. Experimental implementations were conducted under constrained computational and memory resources, evaluating the proposed method's performance on benchmark datasets including GQA, CLEVR, and VizWiz-VQA-Grounding. Comparative analyses with baseline methods demonstrate the robust competitiveness of LCVO.
Multi-view MidiVAE: Fusing Track- and Bar-view Representations for Long Multi-track Symbolic Music Generation
Jan 15, 2024Variational Autoencoders (VAEs) constitute a crucial component of neural symbolic music generation, among which some works have yielded outstanding results and attracted considerable attention. Nevertheless, previous VAEs still encounter issues with overly long feature sequences and generated results lack contextual coherence, thus the challenge of modeling long multi-track symbolic music still remains unaddressed. To this end, we propose Multi-view MidiVAE, as one of the pioneers in VAE methods that effectively model and generate long multi-track symbolic music. The Multi-view MidiVAE utilizes the two-dimensional (2-D) representation, OctupleMIDI, to capture relationships among notes while reducing the feature sequences length. Moreover, we focus on instrumental characteristics and harmony as well as global and local information about the musical composition by employing a hybrid variational encoding-decoding strategy to integrate both Track- and Bar-view MidiVAE features. Objective and subjective experimental results on the CocoChorales dataset demonstrate that, compared to the baseline, Multi-view MidiVAE exhibits significant improvements in terms of modeling long multi-track symbolic music.
DrivingGaussian: Composite Gaussian Splatting for Surrounding Dynamic Autonomous Driving Scenes
Dec 13, 2023We present DrivingGaussian, an efficient and effective framework for surrounding dynamic autonomous driving scenes. For complex scenes with moving objects, we first sequentially and progressively model the static background of the entire scene with incremental static 3D Gaussians. We then leverage a composite dynamic Gaussian graph to handle multiple moving objects, individually reconstructing each object and restoring their accurate positions and occlusion relationships within the scene. We further use a LiDAR prior for Gaussian Splatting to reconstruct scenes with greater details and maintain panoramic consistency. DrivingGaussian outperforms existing methods in driving scene reconstruction and enables photorealistic surround-view synthesis with high-fidelity and multi-camera consistency. The source code and trained models will be released.
SAMPLING: Scene-adaptive Hierarchical Multiplane Images Representation for Novel View Synthesis from a Single Image
Sep 13, 2023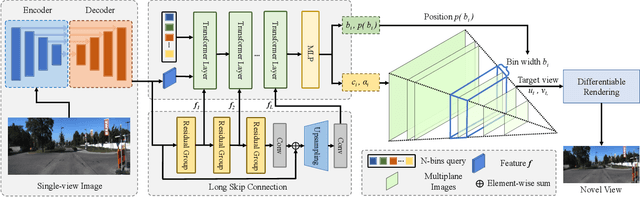
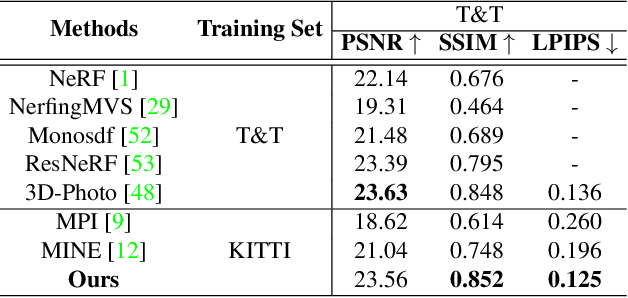
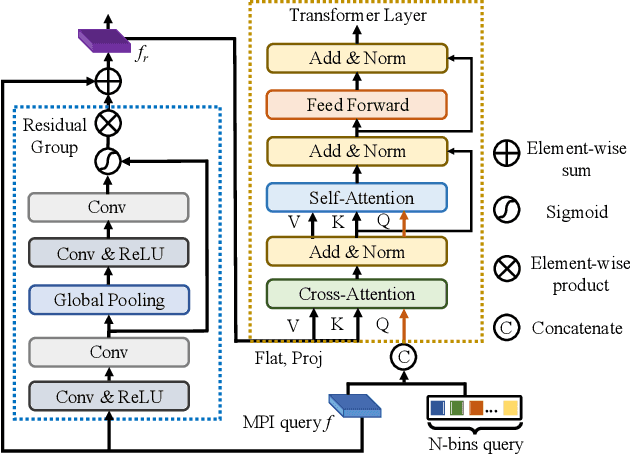
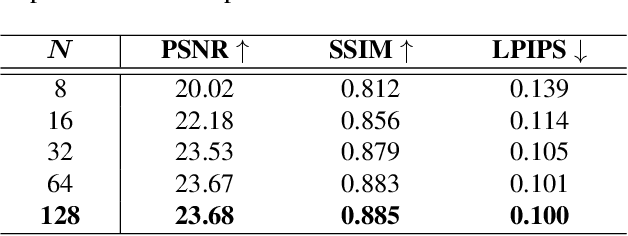
Recent novel view synthesis methods obtain promising results for relatively small scenes, e.g., indoor environments and scenes with a few objects, but tend to fail for unbounded outdoor scenes with a single image as input. In this paper, we introduce SAMPLING, a Scene-adaptive Hierarchical Multiplane Images Representation for Novel View Synthesis from a Single Image based on improved multiplane images (MPI). Observing that depth distribution varies significantly for unbounded outdoor scenes, we employ an adaptive-bins strategy for MPI to arrange planes in accordance with each scene image. To represent intricate geometry and multi-scale details, we further introduce a hierarchical refinement branch, which results in high-quality synthesized novel views. Our method demonstrates considerable performance gains in synthesizing large-scale unbounded outdoor scenes using a single image on the KITTI dataset and generalizes well to the unseen Tanks and Temples dataset.The code and models will soon be made available.
BEV-MAE: Bird's Eye View Masked Autoencoders for Outdoor Point Cloud Pre-training
Dec 12, 2022
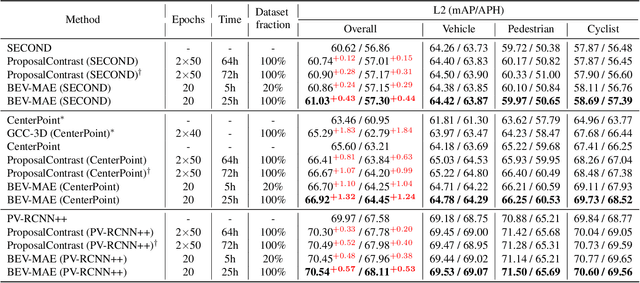
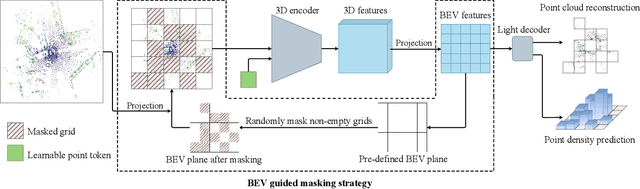

Current outdoor LiDAR-based 3D object detection methods mainly adopt the training-from-scratch paradigm. Unfortunately, this paradigm heavily relies on large-scale labeled data, whose collection can be expensive and time-consuming. Self-supervised pre-training is an effective and desirable way to alleviate this dependence on extensive annotated data. Recently, masked modeling has become a successful self-supervised learning approach for point clouds. However, current works mainly focus on synthetic or indoor datasets. When applied to large-scale and sparse outdoor point clouds, they fail to yield satisfactory results. In this work, we present BEV-MAE, a simple masked autoencoder pre-training framework for 3D object detection on outdoor point clouds. Specifically, we first propose a bird's eye view (BEV) guided masking strategy to guide the 3D encoder learning feature representation in a BEV perspective and avoid complex decoder design during pre-training. Besides, we introduce a learnable point token to maintain a consistent receptive field size of the 3D encoder with fine-tuning for masked point cloud inputs. Finally, based on the property of outdoor point clouds, i.e., the point clouds of distant objects are more sparse, we propose point density prediction to enable the 3D encoder to learn location information, which is essential for object detection. Experimental results show that BEV-MAE achieves new state-of-the-art self-supervised results on both Waymo and nuScenes with diverse 3D object detectors. Furthermore, with only 20% data and 7% training cost during pre-training, BEV-MAE achieves comparable performance with the state-of-the-art method ProposalContrast. The source code and pre-trained models will be made publicly available.
Foreground Guidance and Multi-Layer Feature Fusion for Unsupervised Object Discovery with Transformers
Oct 24, 2022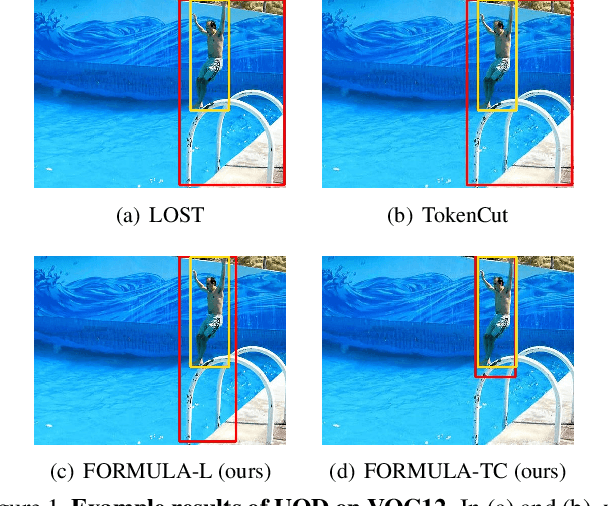
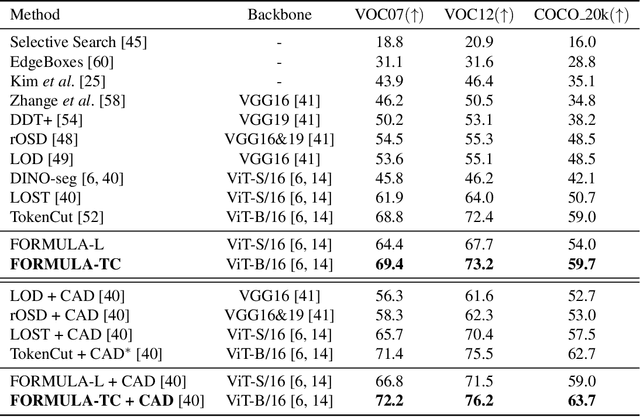


Unsupervised object discovery (UOD) has recently shown encouraging progress with the adoption of pre-trained Transformer features. However, current methods based on Transformers mainly focus on designing the localization head (e.g., seed selection-expansion and normalized cut) and overlook the importance of improving Transformer features. In this work, we handle UOD task from the perspective of feature enhancement and propose FOReground guidance and MUlti-LAyer feature fusion for unsupervised object discovery, dubbed FORMULA. Firstly, we present a foreground guidance strategy with an off-the-shelf UOD detector to highlight the foreground regions on the feature maps and then refine object locations in an iterative fashion. Moreover, to solve the scale variation issues in object detection, we design a multi-layer feature fusion module that aggregates features responding to objects at different scales. The experiments on VOC07, VOC12, and COCO 20k show that the proposed FORMULA achieves new state-of-the-art results on unsupervised object discovery. The code will be released at https://github.com/VDIGPKU/FORMULA.