 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuhan Chen
Interpreting Key Mechanisms of Factual Recall in Transformer-Based Language Models
Apr 09, 2024
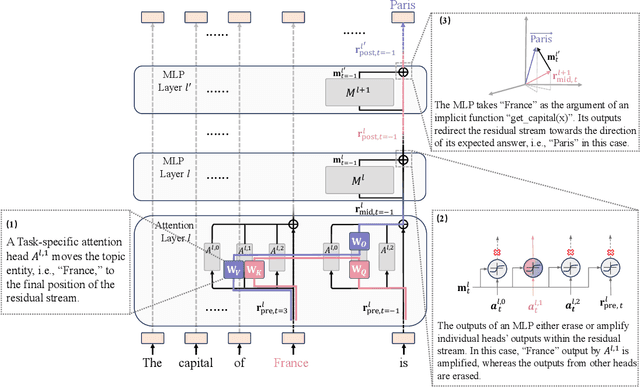

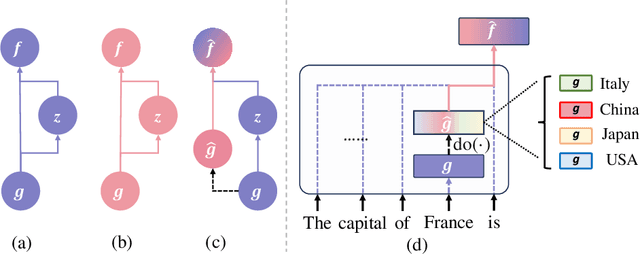

In this paper, we deeply explore the mechanisms employed by Transformer-based language models in factual recall tasks. In zero-shot scenarios, given a prompt like "The capital of France is," task-specific attention heads extract the topic entity, such as "France," from the context and pass it to subsequent MLPs to recall the required answer such as "Paris." We introduce a novel analysis method aimed at decomposing the outputs of the MLP into components understandable by humans. Through this method, we quantify the function of the MLP layer following these task-specific heads. In the residual stream, it either erases or amplifies the information originating from individual heads. Moreover, it generates a component that redirects the residual stream towards the direction of its expected answer. These zero-shot mechanisms are also employed in few-shot scenarios. Additionally, we observed a widely existent anti-overconfidence mechanism in the final layer of models, which suppresses correct predictions. We mitigate this suppression by leveraging our interpretation to improve factual recall performance. Our interpretations have been evaluated across various language models, from the GPT-2 families to 1.3B OPT, and across tasks covering different domains of factual knowledge.
CausalChaos! Dataset for Comprehensive Causal Action Question Answering Over Longer Causal Chains Grounded in Dynamic Visual Scenes
Apr 01, 2024Causal video question answering (QA) has garnered increasing interest, yet existing datasets often lack depth in causal reasoning analysis. To address this gap, we capitalize on the unique properties of cartoons and construct CausalChaos!, a novel, challenging causal Why-QA dataset built upon the iconic "Tom and Jerry" cartoon series. With thoughtful questions and multi-level answers, our dataset contains much longer causal chains embedded in dynamic interactions and visuals, at the same time principles of animation allows animators to create well-defined, unambiguous causal relationships. These factors allow models to solve more challenging, yet well-defined causal relationships. We also introduce hard negative mining, including CausalConfusion version. While models perform well, there is much room for improvement, especially, on open-ended answers. We identify more advanced/explicit causal relationship modeling and joint modeling of vision and language as the immediate areas for future efforts to focus upon. Along with the other complementary datasets, our new challenging dataset will pave the way for these developments in the field. We will release our dataset, codes, and models to help future efforts in this domain.
AS-ES Learning: Towards Efficient CoT Learning in Small Models
Mar 04, 2024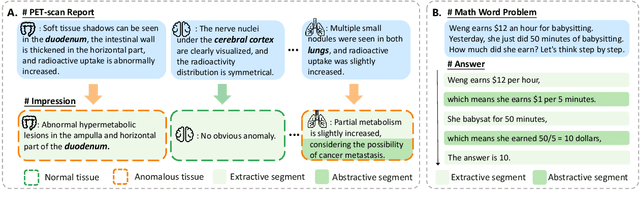
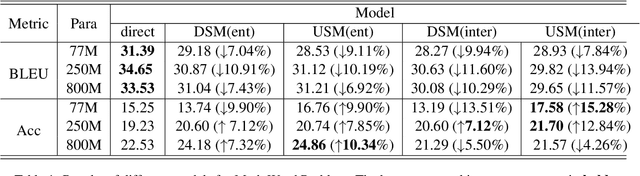
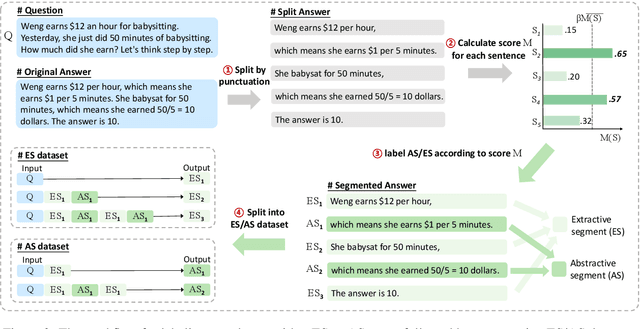

Chain-of-Thought (CoT) serves as a critical emerging ability in LLMs, especially when it comes to logical reasoning. Attempts have been made to induce such ability in small models as well by distilling from the data with CoT generated by Large Language Models (LLMs). However, existing methods often simply generate and incorporate more data from LLMs and fail to note the importance of efficiently utilizing existing CoT data. We here propose a new training paradigm AS-ES (Abstractive Segments - Extractive Segments) learning, which exploits the inherent information in CoT for iterative generation. Experiments show that our methods surpass the direct seq2seq training on CoT-extensive tasks like MWP and PET summarization, without data augmentation or altering the model itself. Furthermore, we explore the reason behind the inefficiency of small models in learning CoT and provide an explanation of why AS-ES learning works, giving insights into the underlying mechanism of CoT.
PirateNets: Physics-informed Deep Learning with Residual Adaptive Networks
Feb 05, 2024While physics-informed neural networks (PINNs) have become a popular deep learning framework for tackling forward and inverse problems governed by partial differential equations (PDEs), their performance is known to degrade when larger and deeper neural network architectures are employed. Our study identifies that the root of this counter-intuitive behavior lies in the use of multi-layer perceptron (MLP) architectures with non-suitable initialization schemes, which result in poor trainablity for the network derivatives, and ultimately lead to an unstable minimization of the PDE residual loss. To address this, we introduce Physics-informed Residual Adaptive Networks (PirateNets), a novel architecture that is designed to facilitate stable and efficient training of deep PINN models. PirateNets leverage a novel adaptive residual connection, which allows the networks to be initialized as shallow networks that progressively deepen during training. We also show that the proposed initialization scheme allows us to encode appropriate inductive biases corresponding to a given PDE system into the network architecture. We provide comprehensive empirical evidence showing that PirateNets are easier to optimize and can gain accuracy from considerably increased depth, ultimately achieving state-of-the-art results across various benchmarks. All code and data accompanying this manuscript will be made publicly available at \url{https://github.com/PredictiveIntelligenceLab/jaxpi}.
LCVO: An Efficient Pretraining-Free Framework for Visual Question Answering Grounding
Jan 29, 2024In this paper, the LCVO modular method is proposed for the Visual Question Answering (VQA) Grounding task in the vision-language multimodal domain. This approach relies on a frozen large language model (LLM) as intermediate mediator between the off-the-shelf VQA model and the off-the-shelf Open-Vocabulary Object Detection (OVD) model, where the LLM transforms and conveys textual information between the two modules based on a designed prompt. LCVO establish an integrated plug-and-play framework without the need for any pre-training process. This framework can be deployed for VQA Grounding tasks under low computational resources. The modularized model within the framework allows application with various state-of-the-art pre-trained models, exhibiting significant potential to be advance with the times. Experimental implementations were conducted under constrained computational and memory resources, evaluating the proposed method's performance on benchmark datasets including GQA, CLEVR, and VizWiz-VQA-Grounding. Comparative analyses with baseline methods demonstrate the robust competitiveness of LCVO.
Batch-ICL: Effective, Efficient, and Order-Agnostic In-Context Learning
Jan 12, 2024In this paper, by treating in-context learning (ICL) as a meta-optimization process, we explain why LLMs are sensitive to the order of ICL examples. This understanding leads us to the development of Batch-ICL, an effective, efficient, and order-agnostic inference algorithm for ICL. Differing from the standard N-shot learning approach, Batch-ICL employs $N$ separate 1-shot forward computations and aggregates the resulting meta-gradients. These aggregated meta-gradients are then applied to a zero-shot learning to generate the final prediction. This batch processing approach renders the LLM agnostic to the order of ICL examples. Through extensive experiments and analysis, we demonstrate that Batch-ICL consistently outperforms most permutations of example sequences. In some cases, it even exceeds the performance of the optimal order for standard ICL, all while reducing the computational resources required. Furthermore, we develop a novel variant of Batch-ICL featuring multiple "epochs" of meta-optimization. This variant implicitly explores permutations of ICL examples, further enhancing ICL performance.
Fortify the Shortest Stave in Attention: Enhancing Context Awareness of Large Language Models for Effective Tool Use
Dec 07, 2023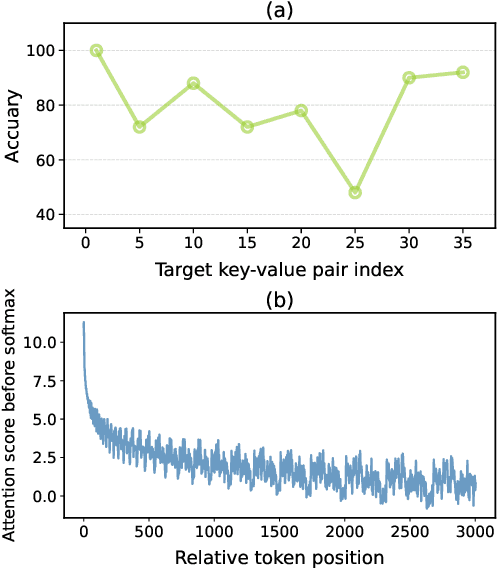
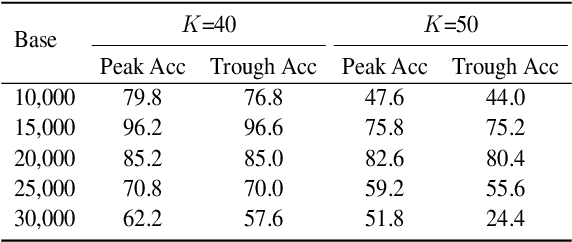


Recent advancements in large language models (LLMs) have significantly expanded their functionality and skills as tool agents. In this paper, we argue that a waveform pattern in the model's attention allocation has an impact on the tool use performance, which degrades when the position of essential information hits the trough zone. To address this issue, we propose a novel inference method named Attention Buckets. This approach enables LLMs to handle context by conducting parallel processes, each featuring a unique RoPE angle base that shapes the attention waveform. Attention Buckets ensures that an attention trough of a particular process can be compensated with an attention peak of another run, reducing the risk of the LLM missing essential information residing within the attention trough. Our extensive experiments on the widely recognized tool use benchmark demonstrate the efficacy of our approach, where a 7B-parameter open-source model enhanced by Attention Buckets achieves SOTA performance on par with GPT-4.
Analyzing the Inherent Response Tendency of LLMs: Real-World Instructions-Driven Jailbreak
Dec 07, 2023Extensive work has been devoted to improving the safety mechanism of Large Language Models (LLMs). However, in specific scenarios, LLMs still generate harmful responses when faced with malicious instructions, a phenomenon referred to as "Jailbreak Attack". In our research, we introduce a novel jailbreak attack method (\textbf{RADIAL}), which consists of two steps: 1) Inherent Response Tendency Analysis: we analyze the inherent affirmation and rejection tendency of LLMs to react to real-world instructions. 2) Real-World Instructions-Driven Jailbreak: based on our analysis, we strategically choose several real-world instructions and embed malicious instructions into them to amplify the LLM's potential to generate harmful responses. On three open-source human-aligned LLMs, our method achieves excellent jailbreak attack performance for both Chinese and English malicious instructions. Besides, we guided detailed ablation experiments and verified the effectiveness of our core idea "Inherent Response Tendency Analysis". Our exploration also exposes the vulnerability of LLMs to being induced into generating more detailed harmful responses in subsequent rounds of dialogue.
Are We Falling in a Middle-Intelligence Trap? An Analysis and Mitigation of the Reversal Curse
Nov 16, 2023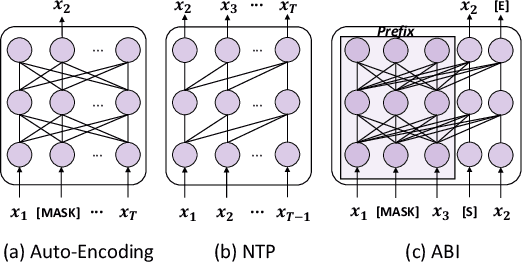
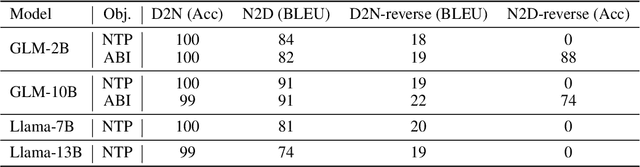
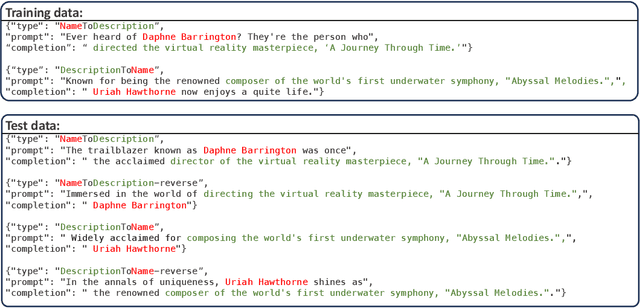

Recent studies have highlighted a phenomenon in large language models (LLMs) known as "the reversal curse," in which the order of knowledge entities in the training data biases the models' comprehension. For example, if a model is trained on sentences where entity A consistently appears before entity B, it can respond to queries about A by providing B as the answer. However, it may encounter confusion when presented with questions concerning B. We contend that the reversal curse is partially a result of specific model training objectives, particularly evident in the prevalent use of the next-token prediction within most causal language models. For the next-token prediction, models solely focus on a token's preceding context, resulting in a restricted comprehension of the input. In contrast, we illustrate that the GLM, trained using the autoregressive blank infilling objective where tokens to be predicted have access to the entire context, exhibits better resilience against the reversal curse. We propose a novel training method, BIdirectional Casual language modeling Optimization (BICO), designed to mitigate the reversal curse when fine-tuning pretrained causal language models on new data. BICO modifies the causal attention mechanism to function bidirectionally and employs a mask denoising optimization. In the task designed to assess the reversal curse, our approach improves Llama's accuracy from the original 0% to around 70%. We hope that more attention can be focused on exploring and addressing these inherent weaknesses of the current LLMs, in order to achieve a higher level of intelligence.
Make Your Decision Convincing! A Unified Two-Stage Framework: Self-Attribution and Decision-Making
Oct 20, 2023Explaining black-box model behavior with natural language has achieved impressive results in various NLP tasks. Recent research has explored the utilization of subsequences from the input text as a rationale, providing users with evidence to support the model decision. Although existing frameworks excel in generating high-quality rationales while achieving high task performance, they neglect to account for the unreliable link between the generated rationale and model decision. In simpler terms, a model may make correct decisions while attributing wrong rationales, or make poor decisions while attributing correct rationales. To mitigate this issue, we propose a unified two-stage framework known as Self-Attribution and Decision-Making (SADM). Through extensive experiments on five reasoning datasets from the ERASER benchmark, we demonstrate that our framework not only establishes a more reliable link between the generated rationale and model decision but also achieves competitive results in task performance and the quality of rationale. Furthermore, we explore the potential of our framework in semi-supervised scenarios.