 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSendong Zhao
AS-ES Learning: Towards Efficient CoT Learning in Small Models
Mar 04, 2024
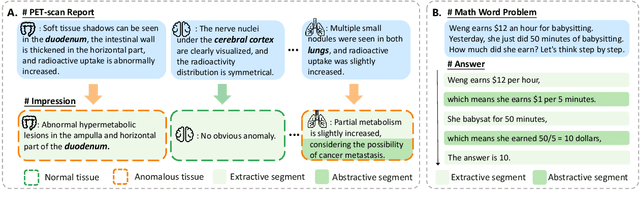
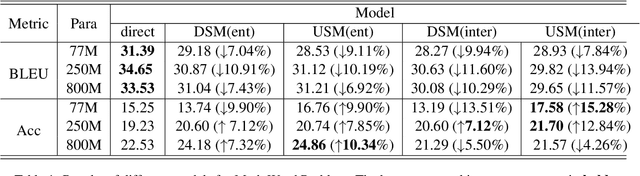
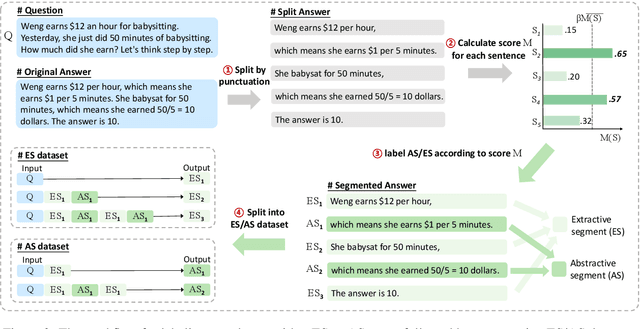

Chain-of-Thought (CoT) serves as a critical emerging ability in LLMs, especially when it comes to logical reasoning. Attempts have been made to induce such ability in small models as well by distilling from the data with CoT generated by Large Language Models (LLMs). However, existing methods often simply generate and incorporate more data from LLMs and fail to note the importance of efficiently utilizing existing CoT data. We here propose a new training paradigm AS-ES (Abstractive Segments - Extractive Segments) learning, which exploits the inherent information in CoT for iterative generation. Experiments show that our methods surpass the direct seq2seq training on CoT-extensive tasks like MWP and PET summarization, without data augmentation or altering the model itself. Furthermore, we explore the reason behind the inefficiency of small models in learning CoT and provide an explanation of why AS-ES learning works, giving insights into the underlying mechanism of CoT.
Beyond the Answers: Reviewing the Rationality of Multiple Choice Question Answering for the Evaluation of Large Language Models
Feb 02, 2024In the field of natural language processing (NLP), Large Language Models (LLMs) have precipitated a paradigm shift, markedly enhancing performance in natural language generation tasks. Despite these advancements, the comprehensive evaluation of LLMs remains an inevitable challenge for the community. Recently, the utilization of Multiple Choice Question Answering (MCQA) as a benchmark for LLMs has gained considerable traction. This study investigates the rationality of MCQA as an evaluation method for LLMs. If LLMs genuinely understand the semantics of questions, their performance should exhibit consistency across the varied configurations derived from the same questions. Contrary to this expectation, our empirical findings suggest a notable disparity in the consistency of LLM responses, which we define as REsponse VAriability Syndrome (REVAS) of the LLMs, indicating that current MCQA-based benchmarks may not adequately capture the true capabilities of LLMs, which underscores the need for more robust evaluation mechanisms in assessing the performance of LLMs.
Beyond Direct Diagnosis: LLM-based Multi-Specialist Agent Consultation for Automatic Diagnosis
Jan 29, 2024Automatic diagnosis is a significant application of AI in healthcare, where diagnoses are generated based on the symptom description of patients. Previous works have approached this task directly by modeling the relationship between the normalized symptoms and all possible diseases. However, in the clinical diagnostic process, patients are initially consulted by a general practitioner and, if necessary, referred to specialists in specific domains for a more comprehensive evaluation. The final diagnosis often emerges from a collaborative consultation among medical specialist groups. Recently, large language models have shown impressive capabilities in natural language understanding. In this study, we adopt tuning-free LLM-based agents as medical practitioners and propose the Agent-derived Multi-Specialist Consultation (AMSC) framework to model the diagnosis process in the real world by adaptively fusing probability distributions of agents over potential diseases. Experimental results demonstrate the superiority of our approach compared with baselines. Notably, our approach requires significantly less parameter updating and training time, enhancing efficiency and practical utility. Furthermore, we delve into a novel perspective on the role of implicit symptoms within the context of automatic diagnosis.
MolTailor: Tailoring Chemical Molecular Representation to Specific Tasks via Text Prompts
Jan 21, 2024Deep learning is now widely used in drug discovery, providing significant acceleration and cost reduction. As the most fundamental building block, molecular representation is essential for predicting molecular properties to enable various downstream applications. Most existing methods attempt to incorporate more information to learn better representations. However, not all features are equally important for a specific task. Ignoring this would potentially compromise the training efficiency and predictive accuracy. To address this issue, we propose a novel approach, which treats language models as an agent and molecular pretraining models as a knowledge base. The agent accentuates task-relevant features in the molecular representation by understanding the natural language description of the task, just as a tailor customizes clothes for clients. Thus, we call this approach MolTailor. Evaluations demonstrate MolTailor's superior performance over baselines, validating the efficacy of enhancing relevance for molecular representation learning. This illustrates the potential of language model guided optimization to better exploit and unleash the capabilities of existing powerful molecular representation methods. Our codes and appendix are available at https://github.com/SCIR-HI/MolTailor.
Analyzing the Inherent Response Tendency of LLMs: Real-World Instructions-Driven Jailbreak
Dec 07, 2023Extensive work has been devoted to improving the safety mechanism of Large Language Models (LLMs). However, in specific scenarios, LLMs still generate harmful responses when faced with malicious instructions, a phenomenon referred to as "Jailbreak Attack". In our research, we introduce a novel jailbreak attack method (\textbf{RADIAL}), which consists of two steps: 1) Inherent Response Tendency Analysis: we analyze the inherent affirmation and rejection tendency of LLMs to react to real-world instructions. 2) Real-World Instructions-Driven Jailbreak: based on our analysis, we strategically choose several real-world instructions and embed malicious instructions into them to amplify the LLM's potential to generate harmful responses. On three open-source human-aligned LLMs, our method achieves excellent jailbreak attack performance for both Chinese and English malicious instructions. Besides, we guided detailed ablation experiments and verified the effectiveness of our core idea "Inherent Response Tendency Analysis". Our exploration also exposes the vulnerability of LLMs to being induced into generating more detailed harmful responses in subsequent rounds of dialogue.
Make Your Decision Convincing! A Unified Two-Stage Framework: Self-Attribution and Decision-Making
Oct 20, 2023Explaining black-box model behavior with natural language has achieved impressive results in various NLP tasks. Recent research has explored the utilization of subsequences from the input text as a rationale, providing users with evidence to support the model decision. Although existing frameworks excel in generating high-quality rationales while achieving high task performance, they neglect to account for the unreliable link between the generated rationale and model decision. In simpler terms, a model may make correct decisions while attributing wrong rationales, or make poor decisions while attributing correct rationales. To mitigate this issue, we propose a unified two-stage framework known as Self-Attribution and Decision-Making (SADM). Through extensive experiments on five reasoning datasets from the ERASER benchmark, we demonstrate that our framework not only establishes a more reliable link between the generated rationale and model decision but also achieves competitive results in task performance and the quality of rationale. Furthermore, we explore the potential of our framework in semi-supervised scenarios.
The CALLA Dataset: Probing LLMs' Interactive Knowledge Acquisition from Chinese Medical Literature
Sep 12, 2023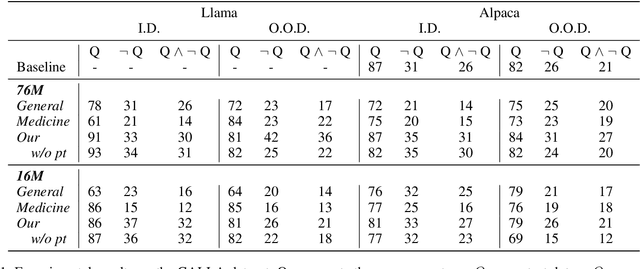

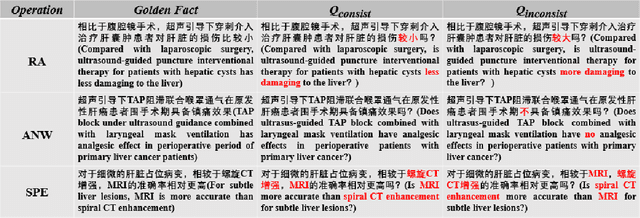
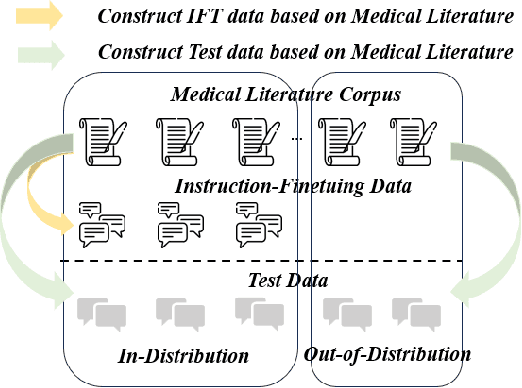
The application of Large Language Models (LLMs) to the medical domain has stimulated the interest of researchers. Recent studies have focused on constructing Instruction Fine-Tuning (IFT) data through medical knowledge graphs to enrich the interactive medical knowledge of LLMs. However, the medical literature serving as a rich source of medical knowledge remains unexplored. Our work introduces the CALLA dataset to probe LLMs' interactive knowledge acquisition from Chinese medical literature. It assesses the proficiency of LLMs in mastering medical knowledge through a free-dialogue fact-checking task. We identify a phenomenon called the ``fact-following response``, where LLMs tend to affirm facts mentioned in questions and display a reluctance to challenge them. To eliminate the inaccurate evaluation caused by this phenomenon, for the golden fact, we artificially construct test data from two perspectives: one consistent with the fact and one inconsistent with the fact. Drawing from the probing experiment on the CALLA dataset, we conclude that IFT data highly correlated with the medical literature corpus serves as a potent catalyst for LLMs, enabling themselves to skillfully employ the medical knowledge acquired during the pre-training phase within interactive scenarios, enhancing accuracy. Furthermore, we design a framework for automatically constructing IFT data based on medical literature and discuss some real-world applications.
From Artificially Real to Real: Leveraging Pseudo Data from Large Language Models for Low-Resource Molecule Discovery
Sep 11, 2023
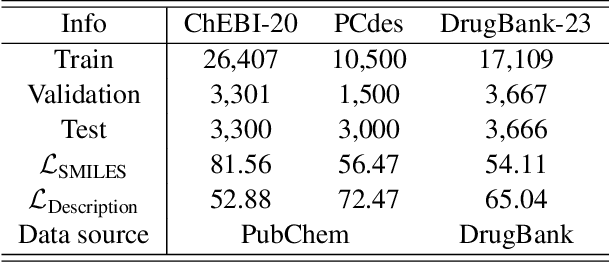
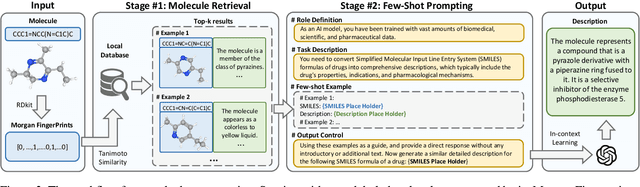
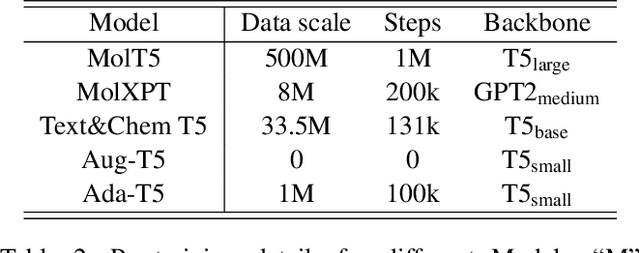
Molecule discovery serves as a cornerstone in numerous scientific domains, fueling the development of new materials and innovative drug designs. Recent developments of in-silico molecule discovery have highlighted the promising results of cross-modal techniques, which bridge molecular structures with their descriptive annotations. However, these cross-modal methods frequently encounter the issue of data scarcity, hampering their performance and application. In this paper, we address the low-resource challenge by utilizing artificially-real data generated by Large Language Models (LLMs). We first introduce a retrieval-based prompting strategy to construct high-quality pseudo data, then explore the optimal method to effectively leverage this pseudo data. Experiments show that using pseudo data for domain adaptation outperforms all existing methods, while also requiring a smaller model scale, reduced data size and lower training cost, highlighting its efficiency. Furthermore, our method shows a sustained improvement as the volume of pseudo data increases, revealing the great potential of pseudo data in advancing low-resource cross-modal molecule discovery.
GLS-CSC: A Simple but Effective Strategy to Mitigate Chinese STM Models' Over-Reliance on Superficial Clue
Sep 08, 2023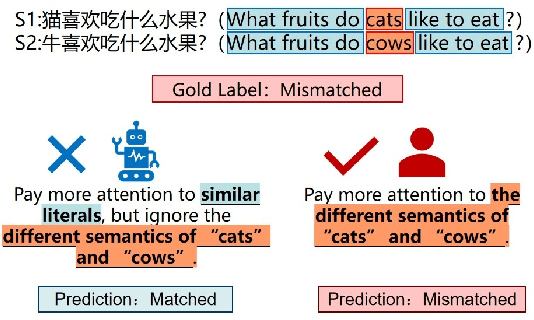
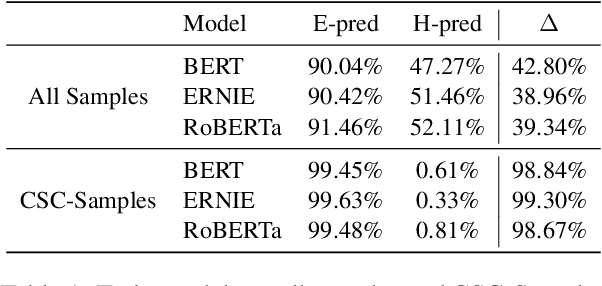
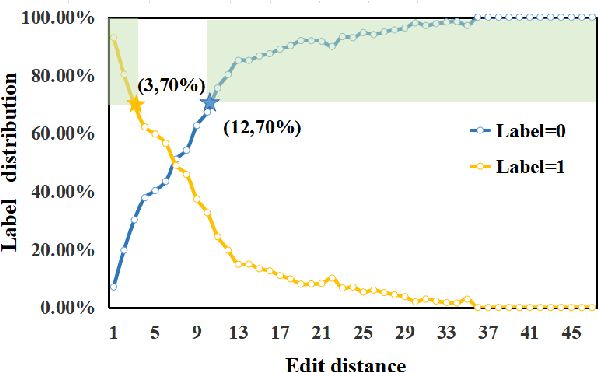
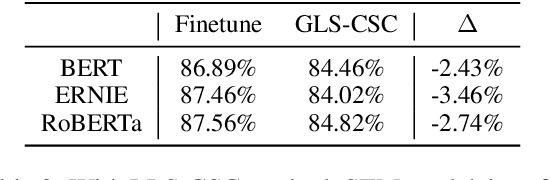
Pre-trained models have achieved success in Chinese Short Text Matching (STM) tasks, but they often rely on superficial clues, leading to a lack of robust predictions. To address this issue, it is crucial to analyze and mitigate the influence of superficial clues on STM models. Our study aims to investigate their over-reliance on the edit distance feature, commonly used to measure the semantic similarity of Chinese text pairs, which can be considered a superficial clue. To mitigate STM models' over-reliance on superficial clues, we propose a novel resampling training strategy called Gradually Learn Samples Containing Superficial Clue (GLS-CSC). Through comprehensive evaluations of In-Domain (I.D.), Robustness (Rob.), and Out-Of-Domain (O.O.D.) test sets, we demonstrate that GLS-CSC outperforms existing methods in terms of enhancing the robustness and generalization of Chinese STM models. Moreover, we conduct a detailed analysis of existing methods and reveal their commonality.
Manifold-based Verbalizer Space Re-embedding for Tuning-free Prompt-based Classification
Sep 08, 2023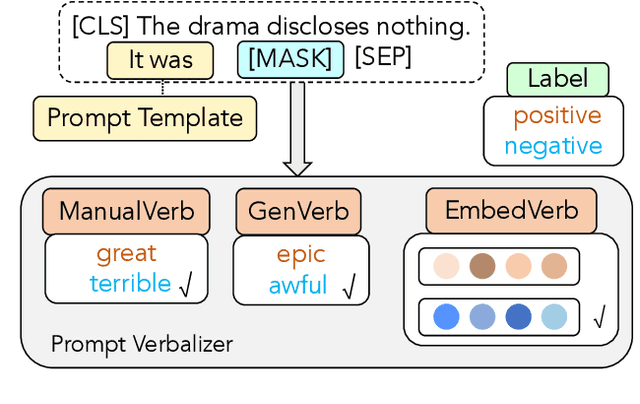
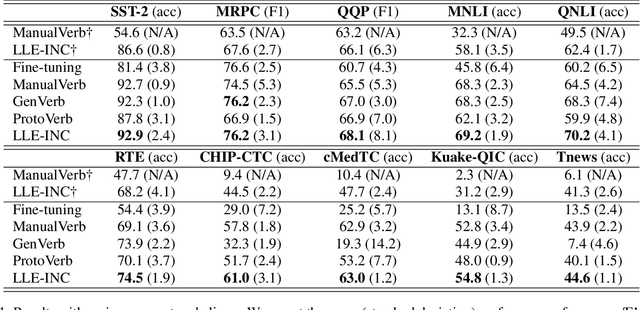
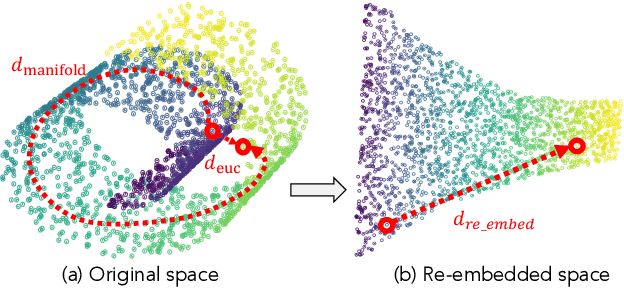
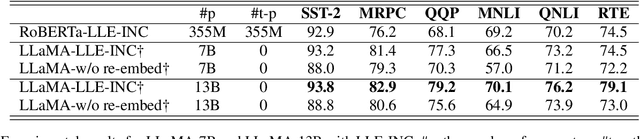
Prompt-based classification adapts tasks to a cloze question format utilizing the [MASK] token and the filled tokens are then mapped to labels through pre-defined verbalizers. Recent studies have explored the use of verbalizer embeddings to reduce labor in this process. However, all existing studies require a tuning process for either the pre-trained models or additional trainable embeddings. Meanwhile, the distance between high-dimensional verbalizer embeddings should not be measured by Euclidean distance due to the potential for non-linear manifolds in the representation space. In this study, we propose a tuning-free manifold-based space re-embedding method called Locally Linear Embedding with Intra-class Neighborhood Constraint (LLE-INC) for verbalizer embeddings, which preserves local properties within the same class as guidance for classification. Experimental results indicate that even without tuning any parameters, our LLE-INC is on par with automated verbalizers with parameter tuning. And with the parameter updating, our approach further enhances prompt-based tuning by up to 3.2%. Furthermore, experiments with the LLaMA-7B&13B indicate that LLE-INC is an efficient tuning-free classification approach for the hyper-scale language models.