 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuchuan Wu
A Survey on Self-Evolution of Large Language Models
Apr 22, 2024
Large language models (LLMs) have significantly advanced in various fields and intelligent agent applications. However, current LLMs that learn from human or external model supervision are costly and may face performance ceilings as task complexity and diversity increase. To address this issue, self-evolution approaches that enable LLM to autonomously acquire, refine, and learn from experiences generated by the model itself are rapidly growing. This new training paradigm inspired by the human experiential learning process offers the potential to scale LLMs towards superintelligence. In this work, we present a comprehensive survey of self-evolution approaches in LLMs. We first propose a conceptual framework for self-evolution and outline the evolving process as iterative cycles composed of four phases: experience acquisition, experience refinement, updating, and evaluation. Second, we categorize the evolution objectives of LLMs and LLM-based agents; then, we summarize the literature and provide taxonomy and insights for each module. Lastly, we pinpoint existing challenges and propose future directions to improve self-evolution frameworks, equipping researchers with critical insights to fast-track the development of self-evolving LLMs.
Semantically-Shifted Incremental Adapter-Tuning is A Continual ViTransformer
Mar 29, 2024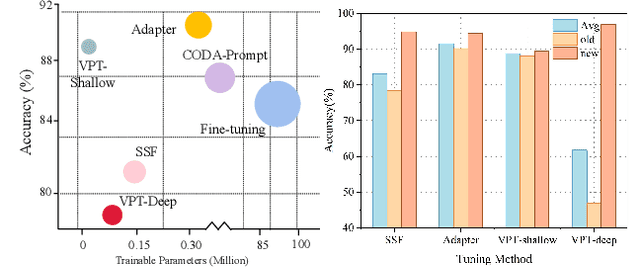
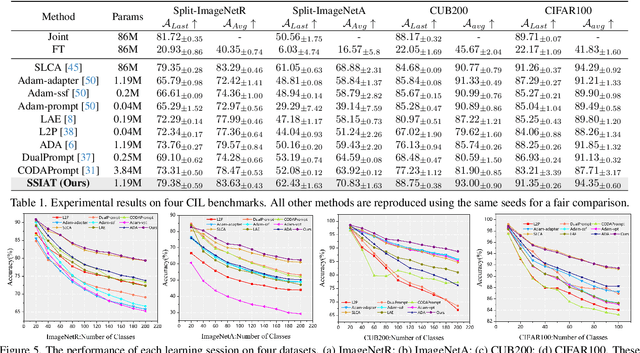
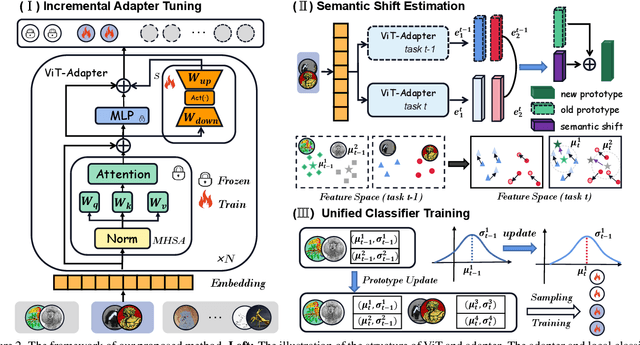
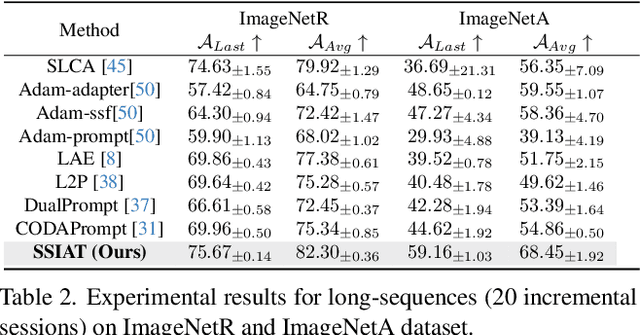
Class-incremental learning (CIL) aims to enable models to continuously learn new classes while overcoming catastrophic forgetting. The introduction of pre-trained models has brought new tuning paradigms to CIL. In this paper, we revisit different parameter-efficient tuning (PET) methods within the context of continual learning. We observe that adapter tuning demonstrates superiority over prompt-based methods, even without parameter expansion in each learning session. Motivated by this, we propose incrementally tuning the shared adapter without imposing parameter update constraints, enhancing the learning capacity of the backbone. Additionally, we employ feature sampling from stored prototypes to retrain a unified classifier, further improving its performance. We estimate the semantic shift of old prototypes without access to past samples and update stored prototypes session by session. Our proposed method eliminates model expansion and avoids retaining any image samples. It surpasses previous pre-trained model-based CIL methods and demonstrates remarkable continual learning capabilities. Experimental results on five CIL benchmarks validate the effectiveness of our approach, achieving state-of-the-art (SOTA) performance.
Enhancing the General Agent Capabilities of Low-Parameter LLMs through Tuning and Multi-Branch Reasoning
Mar 29, 2024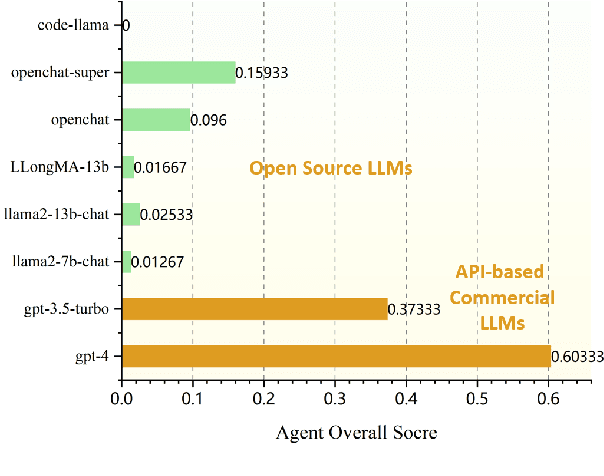
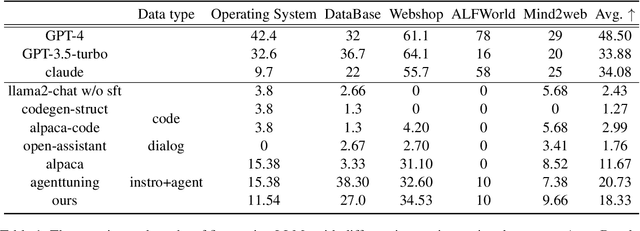

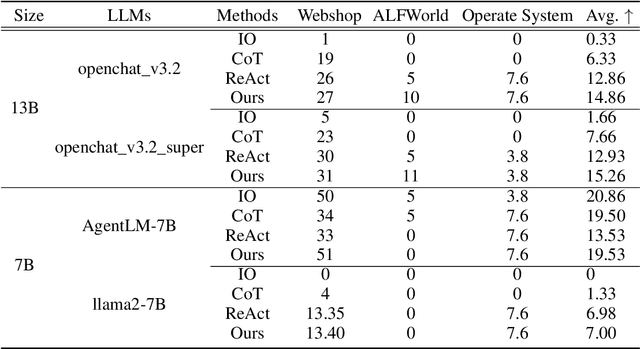
Open-source pre-trained Large Language Models (LLMs) exhibit strong language understanding and generation capabilities, making them highly successful in a variety of tasks. However, when used as agents for dealing with complex problems in the real world, their performance is far inferior to large commercial models such as ChatGPT and GPT-4. As intelligent agents, LLMs need to have the capabilities of task planning, long-term memory, and the ability to leverage external tools to achieve satisfactory performance. Various methods have been proposed to enhance the agent capabilities of LLMs. On the one hand, methods involve constructing agent-specific data and fine-tuning the models. On the other hand, some methods focus on designing prompts that effectively activate the reasoning abilities of the LLMs. We explore both strategies on the 7B and 13B models. We propose a comprehensive method for constructing agent-specific data using GPT-4. Through supervised fine-tuning with constructed data, we find that for these models with a relatively small number of parameters, supervised fine-tuning can significantly reduce hallucination outputs and formatting errors in agent tasks. Furthermore, techniques such as multi-path reasoning and task decomposition can effectively decrease problem complexity and enhance the performance of LLMs as agents. We evaluate our method on five agent tasks of AgentBench and achieve satisfactory results.
Masked Thought: Simply Masking Partial Reasoning Steps Can Improve Mathematical Reasoning Learning of Language Models
Mar 04, 2024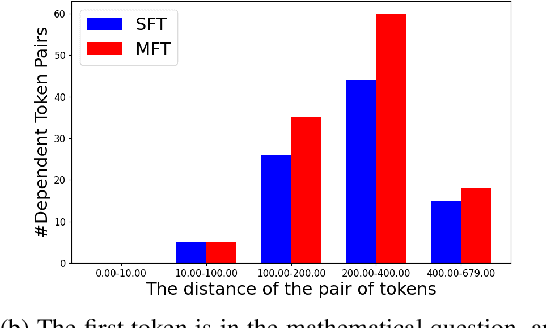
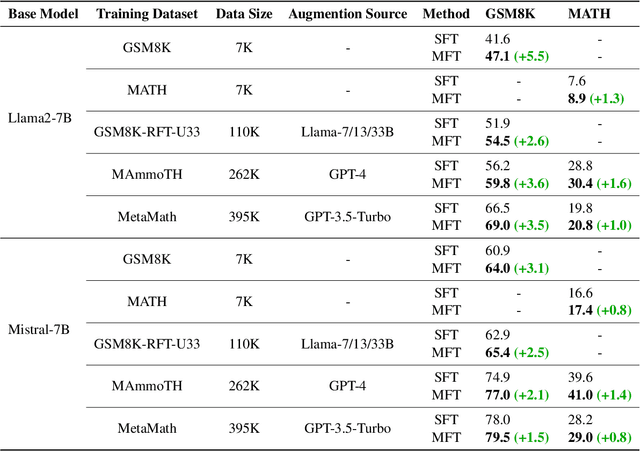
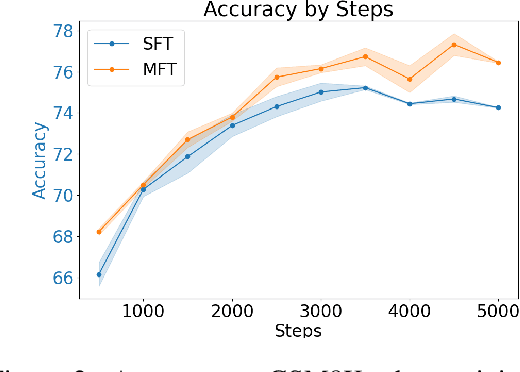
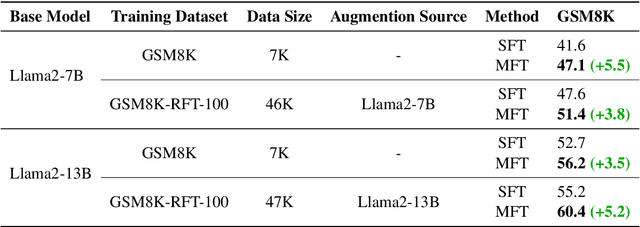
In reasoning tasks, even a minor error can cascade into inaccurate results, leading to suboptimal performance of large language models in such domains. Earlier fine-tuning approaches sought to mitigate this by leveraging more precise supervisory signals from human labeling, larger models, or self-sampling, although at a high cost. Conversely, we develop a method that avoids external resources, relying instead on introducing perturbations to the input. Our training approach randomly masks certain tokens within the chain of thought, a technique we found to be particularly effective for reasoning tasks. When applied to fine-tuning with GSM8K, this method achieved a 5% improvement in accuracy over standard supervised fine-tuning with a few codes modified and no additional labeling effort. Furthermore, it is complementary to existing methods. When integrated with related data augmentation methods, it leads to an average improvement of 3% improvement in GSM8K accuracy and 1% improvement in MATH accuracy across five datasets of various quality and size, as well as two base models. We further investigate the mechanisms behind this improvement through case studies and quantitative analysis, suggesting that our approach may provide superior support for the model in capturing long-distance dependencies, especially those related to questions. This enhancement could deepen understanding of premises in questions and prior steps. Our code is available at Github.
Fortify the Shortest Stave in Attention: Enhancing Context Awareness of Large Language Models for Effective Tool Use
Dec 07, 2023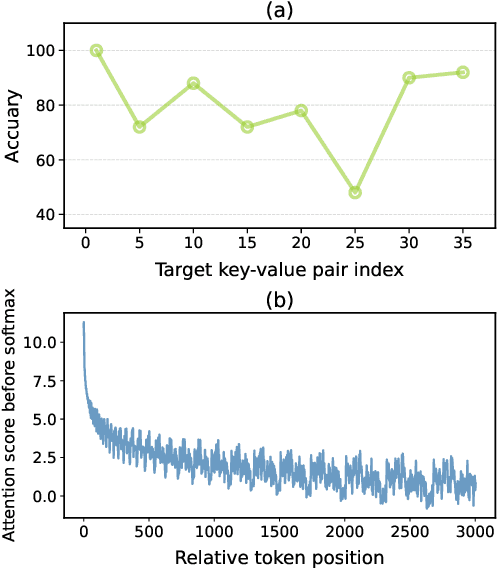
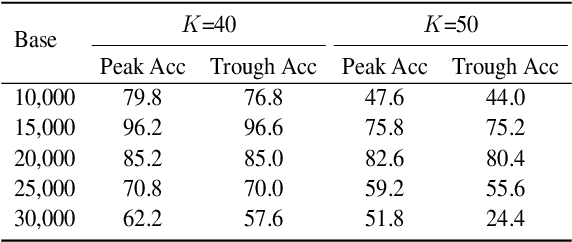


Recent advancements in large language models (LLMs) have significantly expanded their functionality and skills as tool agents. In this paper, we argue that a waveform pattern in the model's attention allocation has an impact on the tool use performance, which degrades when the position of essential information hits the trough zone. To address this issue, we propose a novel inference method named Attention Buckets. This approach enables LLMs to handle context by conducting parallel processes, each featuring a unique RoPE angle base that shapes the attention waveform. Attention Buckets ensures that an attention trough of a particular process can be compensated with an attention peak of another run, reducing the risk of the LLM missing essential information residing within the attention trough. Our extensive experiments on the widely recognized tool use benchmark demonstrate the efficacy of our approach, where a 7B-parameter open-source model enhanced by Attention Buckets achieves SOTA performance on par with GPT-4.
Improving Factual Consistency of Text Summarization by Adversarially Decoupling Comprehension and Embellishment Abilities of LLMs
Nov 01, 2023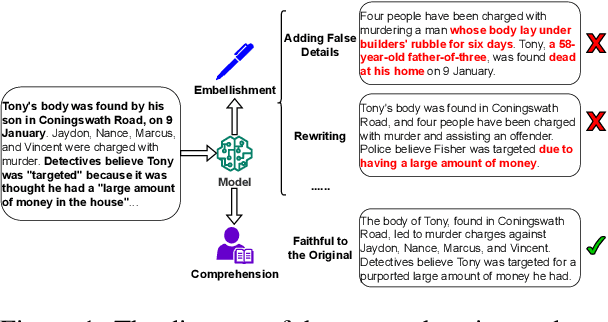
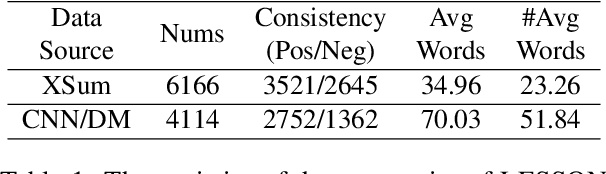
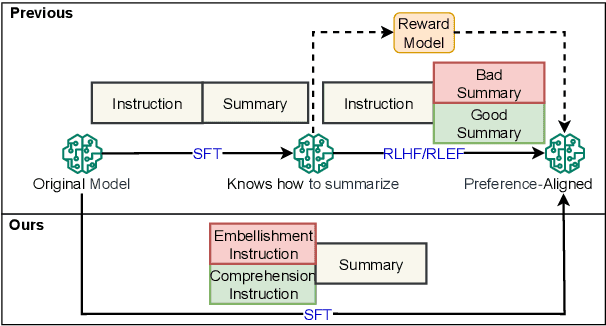
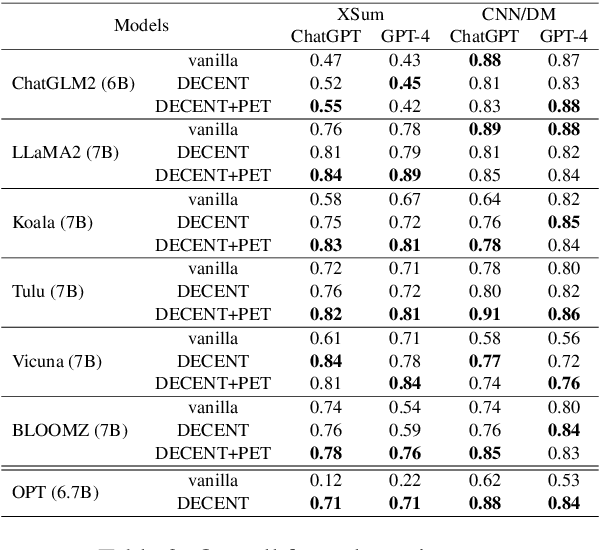
Despite the recent progress in text summarization made by large language models (LLMs), they often generate summaries that are factually inconsistent with original articles, known as "hallucinations" in text generation. Unlike previous small models (e.g., BART, T5), current LLMs make fewer silly mistakes but more sophisticated ones, such as imposing cause and effect, adding false details, and overgeneralizing, etc. These hallucinations are challenging to detect through traditional methods, which poses great challenges for improving the factual consistency of text summarization. In this paper, we propose an adversarially DEcoupling method to disentangle the Comprehension and EmbellishmeNT abilities of LLMs (DECENT). Furthermore, we adopt a probing-based parameter-efficient technique to cover the shortage of sensitivity for true and false in the training process of LLMs. In this way, LLMs are less confused about embellishing and understanding, thus can execute the instructions more accurately and have enhanced abilities to distinguish hallucinations. Experimental results show that DECENT significantly improves the reliability of text summarization based on LLMs.
Constructive Large Language Models Alignment with Diverse Feedback
Oct 11, 2023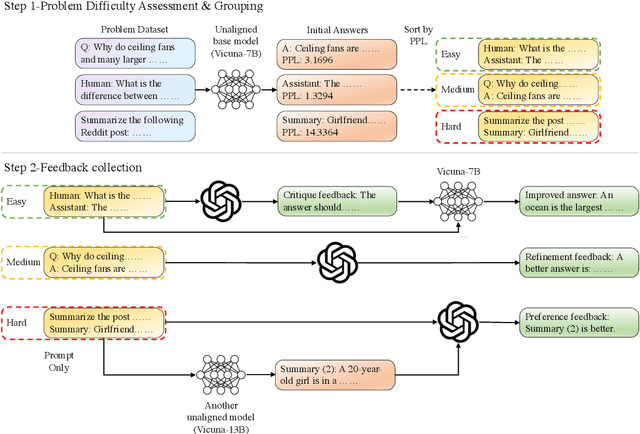
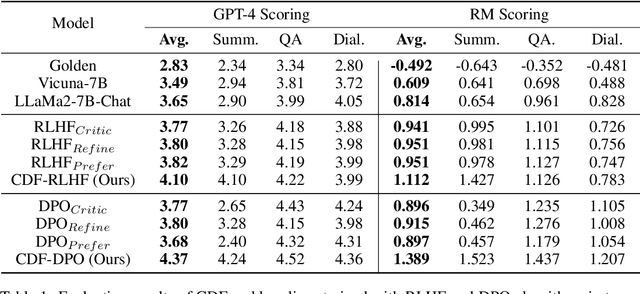
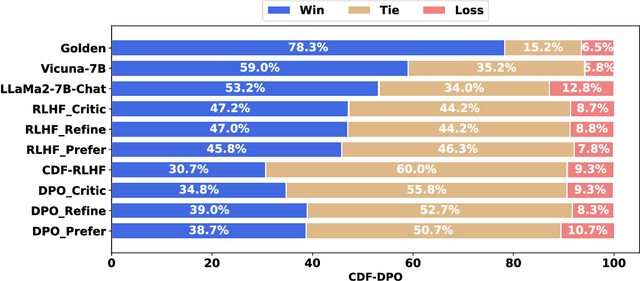

In recent research on large language models (LLMs), there has been a growing emphasis on aligning these models with human values to reduce the impact of harmful content. However, current alignment methods often rely solely on singular forms of human feedback, such as preferences, annotated labels, or natural language critiques, overlooking the potential advantages of combining these feedback types. This limitation leads to suboptimal performance, even when ample training data is available. In this paper, we introduce Constructive and Diverse Feedback (CDF) as a novel method to enhance LLM alignment, inspired by constructivist learning theory. Our approach involves collecting three distinct types of feedback tailored to problems of varying difficulty levels within the training dataset. Specifically, we exploit critique feedback for easy problems, refinement feedback for medium problems, and preference feedback for hard problems. By training our model with this diversified feedback, we achieve enhanced alignment performance while using less training data. To assess the effectiveness of CDF, we evaluate it against previous methods in three downstream tasks: question answering, dialog generation, and text summarization. Experimental results demonstrate that CDF achieves superior performance even with a smaller training dataset.
Self-Explanation Prompting Improves Dialogue Understanding in Large Language Models
Sep 22, 2023

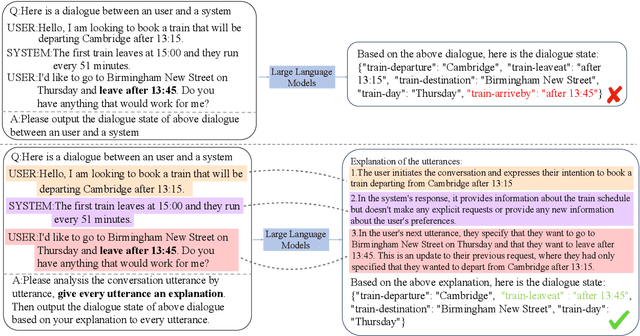
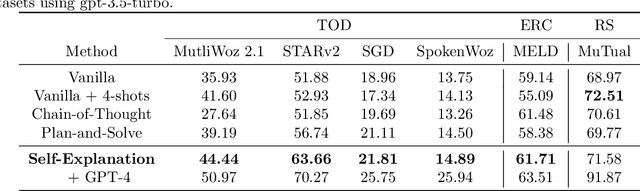
Task-oriented dialogue (TOD) systems facilitate users in executing various activities via multi-turn dialogues, but Large Language Models (LLMs) often struggle to comprehend these intricate contexts. In this study, we propose a novel "Self-Explanation" prompting strategy to enhance the comprehension abilities of LLMs in multi-turn dialogues. This task-agnostic approach requires the model to analyze each dialogue utterance before task execution, thereby improving performance across various dialogue-centric tasks. Experimental results from six benchmark datasets confirm that our method consistently outperforms other zero-shot prompts and matches or exceeds the efficacy of few-shot prompts, demonstrating its potential as a powerful tool in enhancing LLMs' comprehension in complex dialogue tasks.
UniPCM: Universal Pre-trained Conversation Model with Task-aware Automatic Prompt
Sep 20, 2023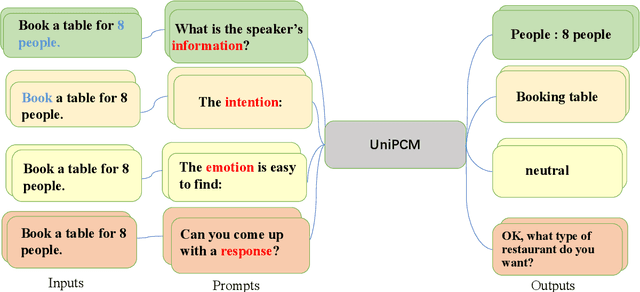
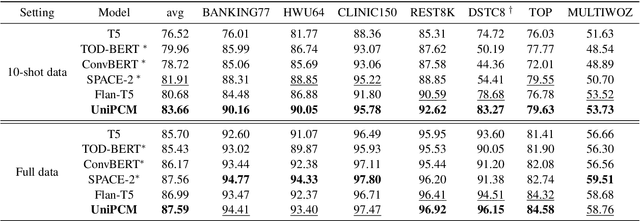

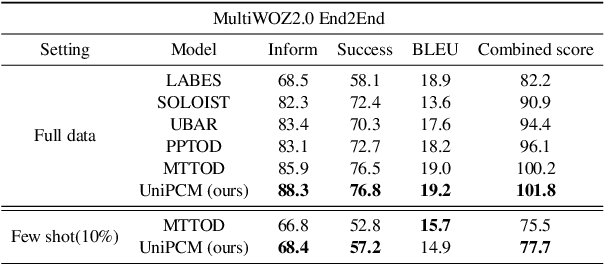
Recent research has shown that multi-task pre-training greatly improves the model's robustness and transfer ability, which is crucial for building a high-quality dialog system. However, most previous works on multi-task pre-training rely heavily on human-defined input format or prompt, which is not optimal in quality and quantity. In this work, we propose to use Task-based Automatic Prompt generation (TAP) to automatically generate high-quality prompts. Using the high-quality prompts generated, we scale the corpus of the pre-trained conversation model to 122 datasets from 15 dialog-related tasks, resulting in Universal Pre-trained Conversation Model (UniPCM), a powerful foundation model for various conversational tasks and different dialog systems. Extensive experiments have shown that UniPCM is robust to input prompts and capable of various dialog-related tasks. Moreover, UniPCM has strong transfer ability and excels at low resource scenarios, achieving SOTA results on 9 different datasets ranging from task-oriented dialog to open-domain conversation. Furthermore, we are amazed to find that TAP can generate prompts on par with those collected with crowdsourcing. The code is released with the paper.
UniSA: Unified Generative Framework for Sentiment Analysis
Sep 04, 2023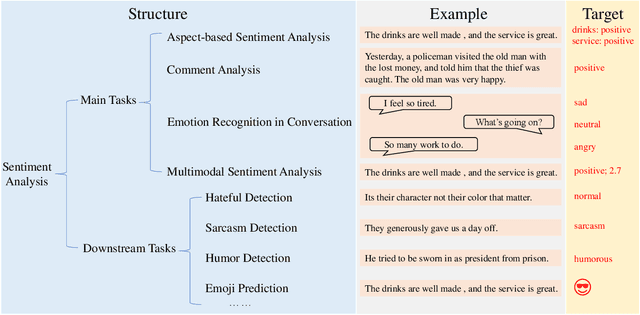
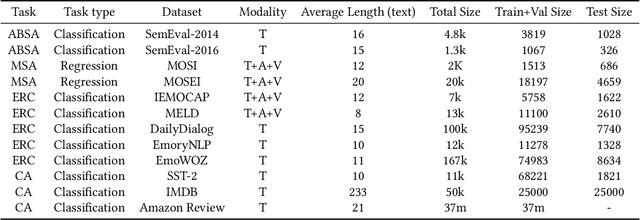
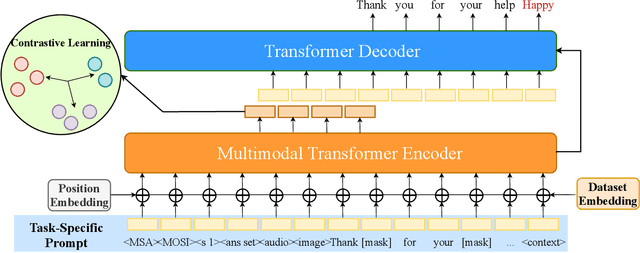

Sentiment analysis is a crucial task that aims to understand people's emotional states and predict emotional categories based on multimodal information. It consists of several subtasks, such as emotion recognition in conversation (ERC), aspect-based sentiment analysis (ABSA), and multimodal sentiment analysis (MSA). However, unifying all subtasks in sentiment analysis presents numerous challenges, including modality alignment, unified input/output forms, and dataset bias. To address these challenges, we propose a Task-Specific Prompt method to jointly model subtasks and introduce a multimodal generative framework called UniSA. Additionally, we organize the benchmark datasets of main subtasks into a new Sentiment Analysis Evaluation benchmark, SAEval. We design novel pre-training tasks and training methods to enable the model to learn generic sentiment knowledge among subtasks to improve the model's multimodal sentiment perception ability. Our experimental results show that UniSA performs comparably to the state-of-the-art on all subtasks and generalizes well to various subtasks in sentiment analysis.