 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAng Lv
Interpreting Key Mechanisms of Factual Recall in Transformer-Based Language Models
Apr 09, 2024
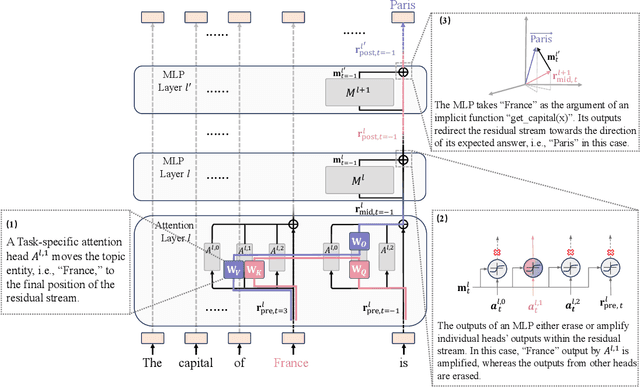

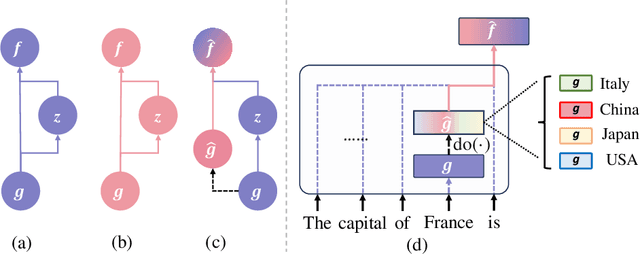

In this paper, we deeply explore the mechanisms employed by Transformer-based language models in factual recall tasks. In zero-shot scenarios, given a prompt like "The capital of France is," task-specific attention heads extract the topic entity, such as "France," from the context and pass it to subsequent MLPs to recall the required answer such as "Paris." We introduce a novel analysis method aimed at decomposing the outputs of the MLP into components understandable by humans. Through this method, we quantify the function of the MLP layer following these task-specific heads. In the residual stream, it either erases or amplifies the information originating from individual heads. Moreover, it generates a component that redirects the residual stream towards the direction of its expected answer. These zero-shot mechanisms are also employed in few-shot scenarios. Additionally, we observed a widely existent anti-overconfidence mechanism in the final layer of models, which suppresses correct predictions. We mitigate this suppression by leveraging our interpretation to improve factual recall performance. Our interpretations have been evaluated across various language models, from the GPT-2 families to 1.3B OPT, and across tasks covering different domains of factual knowledge.
Masked Thought: Simply Masking Partial Reasoning Steps Can Improve Mathematical Reasoning Learning of Language Models
Mar 04, 2024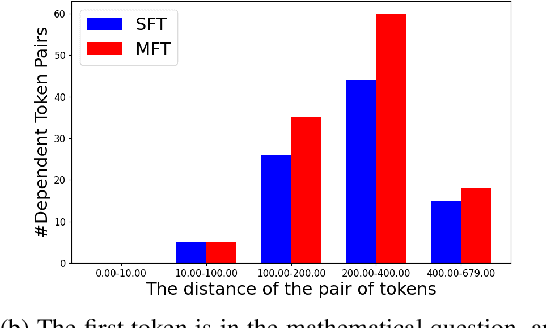
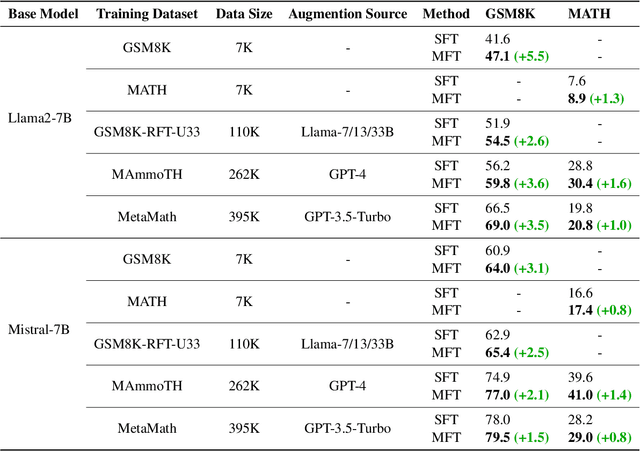
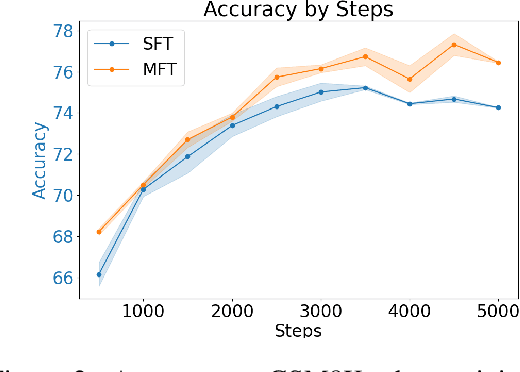
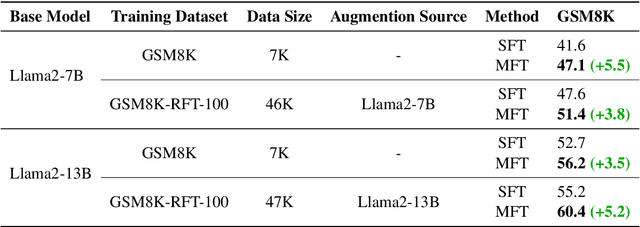
In reasoning tasks, even a minor error can cascade into inaccurate results, leading to suboptimal performance of large language models in such domains. Earlier fine-tuning approaches sought to mitigate this by leveraging more precise supervisory signals from human labeling, larger models, or self-sampling, although at a high cost. Conversely, we develop a method that avoids external resources, relying instead on introducing perturbations to the input. Our training approach randomly masks certain tokens within the chain of thought, a technique we found to be particularly effective for reasoning tasks. When applied to fine-tuning with GSM8K, this method achieved a 5% improvement in accuracy over standard supervised fine-tuning with a few codes modified and no additional labeling effort. Furthermore, it is complementary to existing methods. When integrated with related data augmentation methods, it leads to an average improvement of 3% improvement in GSM8K accuracy and 1% improvement in MATH accuracy across five datasets of various quality and size, as well as two base models. We further investigate the mechanisms behind this improvement through case studies and quantitative analysis, suggesting that our approach may provide superior support for the model in capturing long-distance dependencies, especially those related to questions. This enhancement could deepen understanding of premises in questions and prior steps. Our code is available at Github.
Batch-ICL: Effective, Efficient, and Order-Agnostic In-Context Learning
Jan 12, 2024In this paper, by treating in-context learning (ICL) as a meta-optimization process, we explain why LLMs are sensitive to the order of ICL examples. This understanding leads us to the development of Batch-ICL, an effective, efficient, and order-agnostic inference algorithm for ICL. Differing from the standard N-shot learning approach, Batch-ICL employs $N$ separate 1-shot forward computations and aggregates the resulting meta-gradients. These aggregated meta-gradients are then applied to a zero-shot learning to generate the final prediction. This batch processing approach renders the LLM agnostic to the order of ICL examples. Through extensive experiments and analysis, we demonstrate that Batch-ICL consistently outperforms most permutations of example sequences. In some cases, it even exceeds the performance of the optimal order for standard ICL, all while reducing the computational resources required. Furthermore, we develop a novel variant of Batch-ICL featuring multiple "epochs" of meta-optimization. This variant implicitly explores permutations of ICL examples, further enhancing ICL performance.
Fortify the Shortest Stave in Attention: Enhancing Context Awareness of Large Language Models for Effective Tool Use
Dec 07, 2023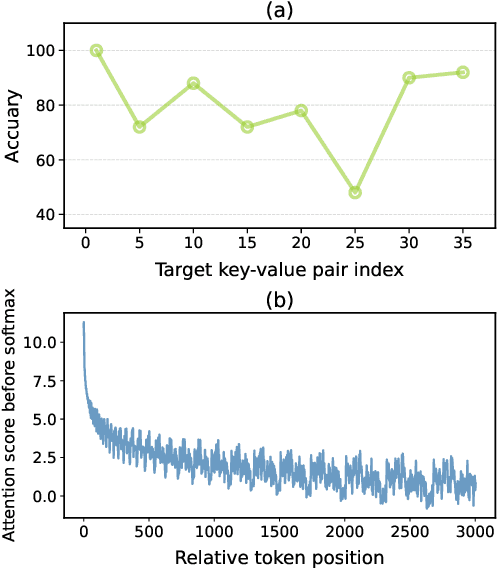
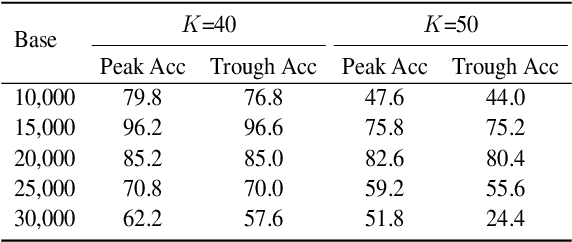


Recent advancements in large language models (LLMs) have significantly expanded their functionality and skills as tool agents. In this paper, we argue that a waveform pattern in the model's attention allocation has an impact on the tool use performance, which degrades when the position of essential information hits the trough zone. To address this issue, we propose a novel inference method named Attention Buckets. This approach enables LLMs to handle context by conducting parallel processes, each featuring a unique RoPE angle base that shapes the attention waveform. Attention Buckets ensures that an attention trough of a particular process can be compensated with an attention peak of another run, reducing the risk of the LLM missing essential information residing within the attention trough. Our extensive experiments on the widely recognized tool use benchmark demonstrate the efficacy of our approach, where a 7B-parameter open-source model enhanced by Attention Buckets achieves SOTA performance on par with GPT-4.
Are We Falling in a Middle-Intelligence Trap? An Analysis and Mitigation of the Reversal Curse
Nov 16, 2023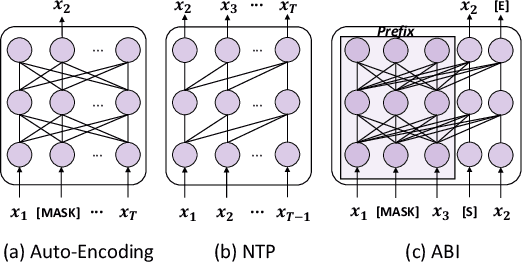
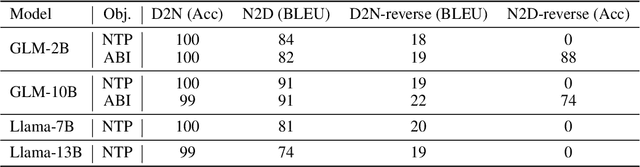
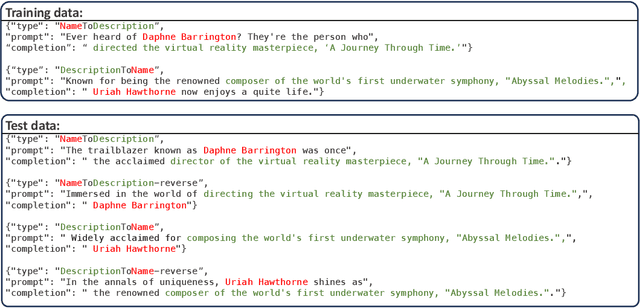

Recent studies have highlighted a phenomenon in large language models (LLMs) known as "the reversal curse," in which the order of knowledge entities in the training data biases the models' comprehension. For example, if a model is trained on sentences where entity A consistently appears before entity B, it can respond to queries about A by providing B as the answer. However, it may encounter confusion when presented with questions concerning B. We contend that the reversal curse is partially a result of specific model training objectives, particularly evident in the prevalent use of the next-token prediction within most causal language models. For the next-token prediction, models solely focus on a token's preceding context, resulting in a restricted comprehension of the input. In contrast, we illustrate that the GLM, trained using the autoregressive blank infilling objective where tokens to be predicted have access to the entire context, exhibits better resilience against the reversal curse. We propose a novel training method, BIdirectional Casual language modeling Optimization (BICO), designed to mitigate the reversal curse when fine-tuning pretrained causal language models on new data. BICO modifies the causal attention mechanism to function bidirectionally and employs a mask denoising optimization. In the task designed to assess the reversal curse, our approach improves Llama's accuracy from the original 0% to around 70%. We hope that more attention can be focused on exploring and addressing these inherent weaknesses of the current LLMs, in order to achieve a higher level of intelligence.
DialoGPS: Dialogue Path Sampling in Continuous Semantic Space for Data Augmentation in Multi-Turn Conversations
Jun 29, 2023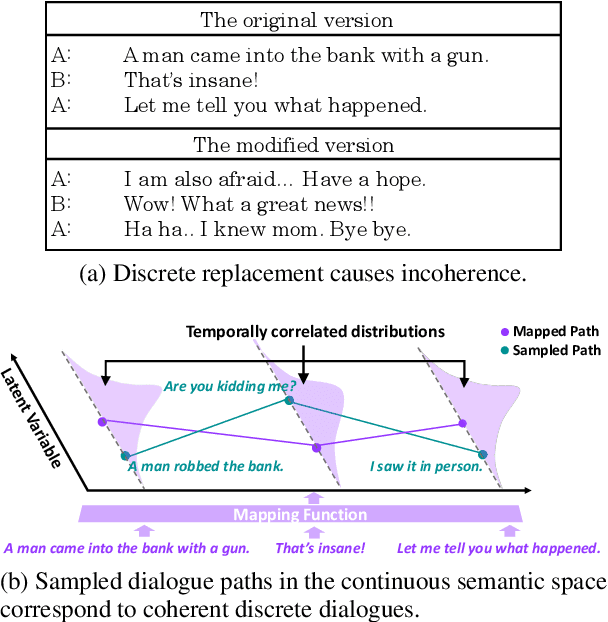
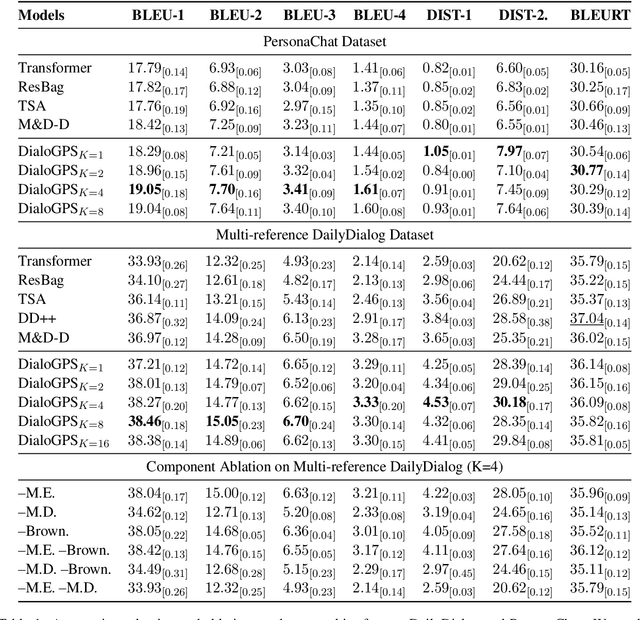
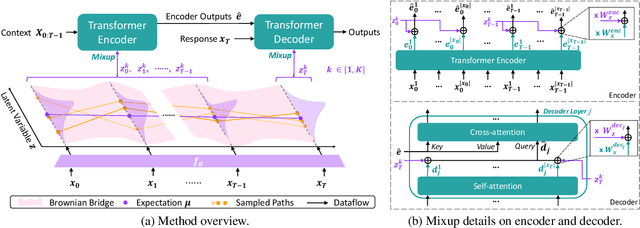

In open-domain dialogue generation tasks, contexts and responses in most datasets are one-to-one mapped, violating an important many-to-many characteristic: a context leads to various responses, and a response answers multiple contexts. Without such patterns, models poorly generalize and prefer responding safely. Many attempts have been made in either multi-turn settings from a one-to-many perspective or in a many-to-many perspective but limited to single-turn settings. The major challenge to many-to-many augment multi-turn dialogues is that discretely replacing each turn with semantic similarity breaks fragile context coherence. In this paper, we propose DialoGue Path Sampling (DialoGPS) method in continuous semantic space, the first many-to-many augmentation method for multi-turn dialogues. Specifically, we map a dialogue to our extended Brownian Bridge, a special Gaussian process. We sample latent variables to form coherent dialogue paths in the continuous space. A dialogue path corresponds to a new multi-turn dialogue and is used as augmented training data. We show the effect of DialoGPS with both automatic and human evaluation.
GETMusic: Generating Any Music Tracks with a Unified Representation and Diffusion Framework
May 18, 2023



Symbolic music generation aims to create musical notes, which can help users compose music, such as generating target instrumental tracks from scratch, or based on user-provided source tracks. Considering the diverse and flexible combination between source and target tracks, a unified model capable of generating any arbitrary tracks is of crucial necessity. Previous works fail to address this need due to inherent constraints in music representations and model architectures. To address this need, we propose a unified representation and diffusion framework named GETMusic (`GET' stands for GEnerate music Tracks), which includes a novel music representation named GETScore, and a diffusion model named GETDiff. GETScore represents notes as tokens and organizes them in a 2D structure, with tracks stacked vertically and progressing horizontally over time. During training, tracks are randomly selected as either the target or source. In the forward process, target tracks are corrupted by masking their tokens, while source tracks remain as ground truth. In the denoising process, GETDiff learns to predict the masked target tokens, conditioning on the source tracks. With separate tracks in GETScore and the non-autoregressive behavior of the model, GETMusic can explicitly control the generation of any target tracks from scratch or conditioning on source tracks. We conduct experiments on music generation involving six instrumental tracks, resulting in a total of 665 combinations. GETMusic provides high-quality results across diverse combinations and surpasses prior works proposed for some specific combinations.
Re-creation of Creations: A New Paradigm for Lyric-to-Melody Generation
Aug 18, 2022



Lyric-to-melody generation is an important task in songwriting, and is also quite challenging due to its distinctive characteristics: the generated melodies should not only follow good musical patterns, but also align with features in lyrics such as rhythms and structures. These characteristics cannot be well handled by neural generation models that learn lyric-to-melody mapping in an end-to-end way, due to several issues: (1) lack of aligned lyric-melody training data to sufficiently learn lyric-melody feature alignment; (2) lack of controllability in generation to explicitly guarantee the lyric-melody feature alignment. In this paper, we propose Re-creation of Creations (ROC), a new paradigm for lyric-to-melody generation that addresses the above issues through a generation-retrieval pipeline. Specifically, our paradigm has two stages: (1) creation stage, where a huge amount of music pieces are generated by a neural-based melody language model and indexed in a database through several key features (e.g., chords, tonality, rhythm, and structural information including chorus or verse); (2) re-creation stage, where melodies are recreated by retrieving music pieces from the database according to the key features from lyrics and concatenating best music pieces based on composition guidelines and melody language model scores. Our new paradigm has several advantages: (1) It only needs unpaired melody data to train melody language model, instead of paired lyric-melody data in previous models. (2) It achieves good lyric-melody feature alignment in lyric-to-melody generation. Experiments on English and Chinese datasets demonstrate that ROC outperforms previous neural based lyric-to-melody generation models on both objective and subjective metrics.