 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWei Ye
Generative manufacturing systems using diffusion models and ChatGPT
May 02, 2024
In this study, we introduce Generative Manufacturing Systems (GMS) as a novel approach to effectively manage and coordinate autonomous manufacturing assets, thereby enhancing their responsiveness and flexibility to address a wide array of production objectives and human preferences. Deviating from traditional explicit modeling, GMS employs generative AI, including diffusion models and ChatGPT, for implicit learning from envisioned futures, marking a shift from a model-optimum to a training-sampling decision-making. Through the integration of generative AI, GMS enables complex decision-making through interactive dialogue with humans, allowing manufacturing assets to generate multiple high-quality global decisions that can be iteratively refined based on human feedback. Empirical findings showcase GMS's substantial improvement in system resilience and responsiveness to uncertainties, with decision times reduced from seconds to milliseconds. The study underscores the inherent creativity and diversity in the generated solutions, facilitating human-centric decision-making through seamless and continuous human-machine interactions.
Boosting Model Resilience via Implicit Adversarial Data Augmentation
Apr 25, 2024Data augmentation plays a pivotal role in enhancing and diversifying training data. Nonetheless, consistently improving model performance in varied learning scenarios, especially those with inherent data biases, remains challenging. To address this, we propose to augment the deep features of samples by incorporating their adversarial and anti-adversarial perturbation distributions, enabling adaptive adjustment in the learning difficulty tailored to each sample's specific characteristics. We then theoretically reveal that our augmentation process approximates the optimization of a surrogate loss function as the number of augmented copies increases indefinitely. This insight leads us to develop a meta-learning-based framework for optimizing classifiers with this novel loss, introducing the effects of augmentation while bypassing the explicit augmentation process. We conduct extensive experiments across four common biased learning scenarios: long-tail learning, generalized long-tail learning, noisy label learning, and subpopulation shift learning. The empirical results demonstrate that our method consistently achieves state-of-the-art performance, highlighting its broad adaptability.
FreeEval: A Modular Framework for Trustworthy and Efficient Evaluation of Large Language Models
Apr 09, 2024The rapid development of large language model (LLM) evaluation methodologies and datasets has led to a profound challenge: integrating state-of-the-art evaluation techniques cost-effectively while ensuring reliability, reproducibility, and efficiency. Currently, there is a notable absence of a unified and adaptable framework that seamlessly integrates various evaluation approaches. Moreover, the reliability of evaluation findings is often questionable due to potential data contamination, with the evaluation efficiency commonly overlooked when facing the substantial costs associated with LLM inference. In response to these challenges, we introduce FreeEval, a modular and scalable framework crafted to enable trustworthy and efficient automatic evaluations of LLMs. Firstly, FreeEval's unified abstractions simplify the integration and improve the transparency of diverse evaluation methodologies, encompassing dynamic evaluation that demand sophisticated LLM interactions. Secondly, the framework integrates meta-evaluation techniques like human evaluation and data contamination detection, which, along with dynamic evaluation modules in the platform, enhance the fairness of the evaluation outcomes. Lastly, FreeEval is designed with a high-performance infrastructure, including distributed computation and caching strategies, enabling extensive evaluations across multi-node, multi-GPU clusters for open-source and proprietary LLMs.
CoherentGS: Sparse Novel View Synthesis with Coherent 3D Gaussians
Mar 28, 2024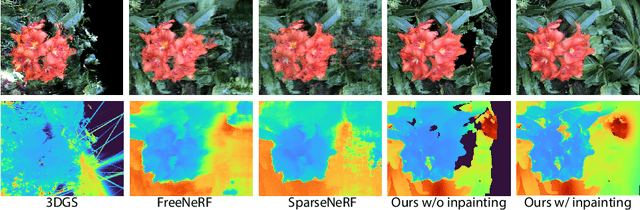
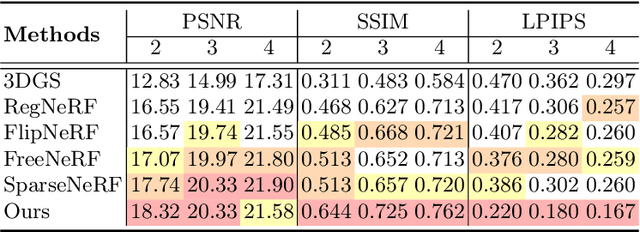

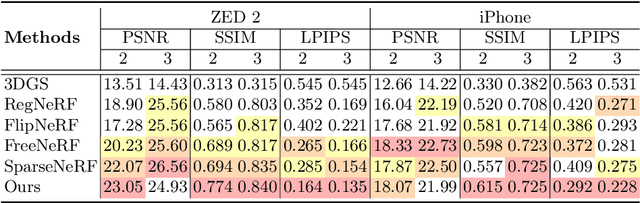
The field of 3D reconstruction from images has rapidly evolved in the past few years, first with the introduction of Neural Radiance Field (NeRF) and more recently with 3D Gaussian Splatting (3DGS). The latter provides a significant edge over NeRF in terms of the training and inference speed, as well as the reconstruction quality. Although 3DGS works well for dense input images, the unstructured point-cloud like representation quickly overfits to the more challenging setup of extremely sparse input images (e.g., 3 images), creating a representation that appears as a jumble of needles from novel views. To address this issue, we propose regularized optimization and depth-based initialization. Our key idea is to introduce a structured Gaussian representation that can be controlled in 2D image space. We then constraint the Gaussians, in particular their position, and prevent them from moving independently during optimization. Specifically, we introduce single and multiview constraints through an implicit convolutional decoder and a total variation loss, respectively. With the coherency introduced to the Gaussians, we further constrain the optimization through a flow-based loss function. To support our regularized optimization, we propose an approach to initialize the Gaussians using monocular depth estimates at each input view. We demonstrate significant improvements compared to the state-of-the-art sparse-view NeRF-based approaches on a variety of scenes.
CodeShell Technical Report
Mar 23, 2024Code large language models mark a pivotal breakthrough in artificial intelligence. They are specifically crafted to understand and generate programming languages, significantly boosting the efficiency of coding development workflows. In this technical report, we present CodeShell-Base, a seven billion-parameter foundation model with 8K context length, showcasing exceptional proficiency in code comprehension. By incorporating Grouped-Query Attention and Rotary Positional Embedding into GPT-2, CodeShell-Base integrates the structural merits of StarCoder and CodeLlama and forms its unique architectural design. We then carefully built a comprehensive data pre-processing process, including similar data deduplication, perplexity-based data filtering, and model-based data filtering. Through this process, We have curated 100 billion high-quality pre-training data from GitHub. Benefiting from the high-quality data, CodeShell-Base outperforms CodeLlama in Humaneval after training on just 500 billion tokens (5 epochs). We have conducted extensive experiments across multiple language datasets, including Python, Java, and C++, and the results indicate that our model possesses robust foundational capabilities in code comprehension and generation.
NightHaze: Nighttime Image Dehazing via Self-Prior Learning
Mar 12, 2024
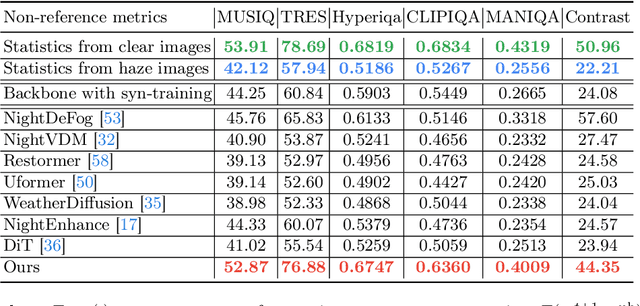
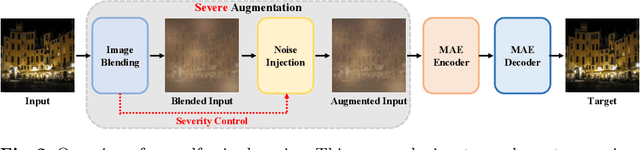
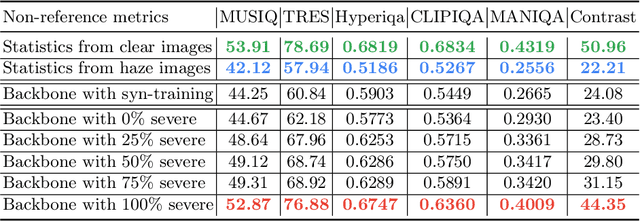
Masked autoencoder (MAE) shows that severe augmentation during training produces robust representations for high-level tasks. This paper brings the MAE-like framework to nighttime image enhancement, demonstrating that severe augmentation during training produces strong network priors that are resilient to real-world night haze degradations. We propose a novel nighttime image dehazing method with self-prior learning. Our main novelty lies in the design of severe augmentation, which allows our model to learn robust priors. Unlike MAE that uses masking, we leverage two key challenging factors of nighttime images as augmentation: light effects and noise. During training, we intentionally degrade clear images by blending them with light effects as well as by adding noise, and subsequently restore the clear images. This enables our model to learn clear background priors. By increasing the noise values to approach as high as the pixel intensity values of the glow and light effect blended images, our augmentation becomes severe, resulting in stronger priors. While our self-prior learning is considerably effective in suppressing glow and revealing details of background scenes, in some cases, there are still some undesired artifacts that remain, particularly in the forms of over-suppression. To address these artifacts, we propose a self-refinement module based on the semi-supervised teacher-student framework. Our NightHaze, especially our MAE-like self-prior learning, shows that models trained with severe augmentation effectively improve the visibility of input haze images, approaching the clarity of clear nighttime images. Extensive experiments demonstrate that our NightHaze achieves state-of-the-art performance, outperforming existing nighttime image dehazing methods by a substantial margin of 15.5% for MUSIQ and 23.5% for ClipIQA.
NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models
Mar 05, 2024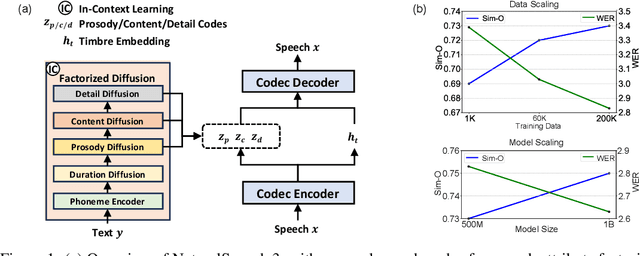
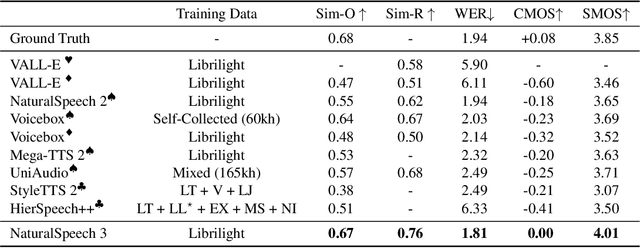
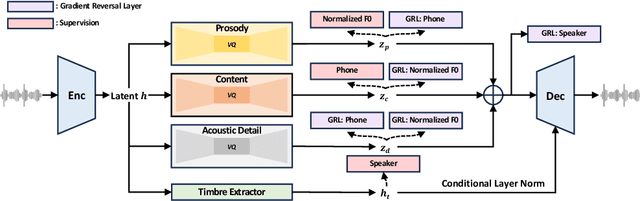
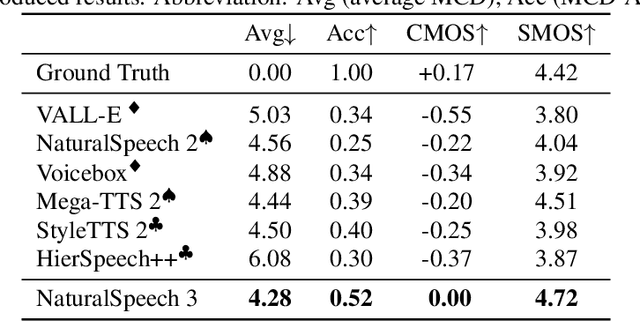
While recent large-scale text-to-speech (TTS) models have achieved significant progress, they still fall short in speech quality, similarity, and prosody. Considering speech intricately encompasses various attributes (e.g., content, prosody, timbre, and acoustic details) that pose significant challenges for generation, a natural idea is to factorize speech into individual subspaces representing different attributes and generate them individually. Motivated by it, we propose NaturalSpeech 3, a TTS system with novel factorized diffusion models to generate natural speech in a zero-shot way. Specifically, 1) we design a neural codec with factorized vector quantization (FVQ) to disentangle speech waveform into subspaces of content, prosody, timbre, and acoustic details; 2) we propose a factorized diffusion model to generate attributes in each subspace following its corresponding prompt. With this factorization design, NaturalSpeech 3 can effectively and efficiently model the intricate speech with disentangled subspaces in a divide-and-conquer way. Experiments show that NaturalSpeech 3 outperforms the state-of-the-art TTS systems on quality, similarity, prosody, and intelligibility. Furthermore, we achieve better performance by scaling to 1B parameters and 200K hours of training data.
Can Large Language Models Recall Reference Location Like Humans?
Feb 26, 2024When completing knowledge-intensive tasks, humans sometimes need not just an answer but also a corresponding reference passage for auxiliary reading. Previous methods required obtaining pre-segmented article chunks through additional retrieval models. This paper explores leveraging the parameterized knowledge stored during the pre-training phase of large language models (LLMs) to independently recall reference passage from any starting position. We propose a two-stage framework that simulates the scenario of humans recalling easily forgotten references. Initially, the LLM is prompted to recall document title identifiers to obtain a coarse-grained document set. Then, based on the acquired coarse-grained document set, it recalls fine-grained passage. In the two-stage recall process, we use constrained decoding to ensure that content outside of the stored documents is not generated. To increase speed, we only recall a short prefix in the second stage, then locate its position to retrieve a complete passage. Experiments on KILT knowledge-sensitive tasks have verified that LLMs can independently recall reference passage location in various task forms, and the obtained reference significantly assist downstream tasks.
Hal-Eval: A Universal and Fine-grained Hallucination Evaluation Framework for Large Vision Language Models
Feb 24, 2024Large Vision Language Models exhibit remarkable capabilities but struggle with hallucinations inconsistencies between images and their descriptions. Previous hallucination evaluation studies on LVLMs have identified hallucinations in terms of objects, attributes, and relations but overlooked complex hallucinations that create an entire narrative around a fictional entity. In this paper, we introduce a refined taxonomy of hallucinations, featuring a new category: Event Hallucination. We then utilize advanced LLMs to generate and filter fine grained hallucinatory data consisting of various types of hallucinations, with a particular focus on event hallucinations, laying the groundwork for integrating discriminative and generative evaluation methods within our universal evaluation framework. The proposed benchmark distinctively assesses LVLMs ability to tackle a broad spectrum of hallucinations, making it a reliable and comprehensive tool for gauging LVLMs efficacy in handling hallucinations. We will release our code and data.
KIEval: A Knowledge-grounded Interactive Evaluation Framework for Large Language Models
Feb 23, 2024Automatic evaluation methods for large language models (LLMs) are hindered by data contamination, leading to inflated assessments of their effectiveness. Existing strategies, which aim to detect contaminated texts, focus on quantifying contamination status instead of accurately gauging model performance. In this paper, we introduce KIEval, a Knowledge-grounded Interactive Evaluation framework, which incorporates an LLM-powered "interactor" role for the first time to accomplish a dynamic contamination-resilient evaluation. Starting with a question in a conventional LLM benchmark involving domain-specific knowledge, KIEval utilizes dynamically generated, multi-round, and knowledge-focused dialogues to determine whether a model's response is merely a recall of benchmark answers or demonstrates a deep comprehension to apply knowledge in more complex conversations. Extensive experiments on seven leading LLMs across five datasets validate KIEval's effectiveness and generalization. We also reveal that data contamination brings no contribution or even negative effect to models' real-world applicability and understanding, and existing contamination detection methods for LLMs can only identify contamination in pre-training but not during supervised fine-tuning.