 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYidong Wang
FreeEval: A Modular Framework for Trustworthy and Efficient Evaluation of Large Language Models
Apr 09, 2024
The rapid development of large language model (LLM) evaluation methodologies and datasets has led to a profound challenge: integrating state-of-the-art evaluation techniques cost-effectively while ensuring reliability, reproducibility, and efficiency. Currently, there is a notable absence of a unified and adaptable framework that seamlessly integrates various evaluation approaches. Moreover, the reliability of evaluation findings is often questionable due to potential data contamination, with the evaluation efficiency commonly overlooked when facing the substantial costs associated with LLM inference. In response to these challenges, we introduce FreeEval, a modular and scalable framework crafted to enable trustworthy and efficient automatic evaluations of LLMs. Firstly, FreeEval's unified abstractions simplify the integration and improve the transparency of diverse evaluation methodologies, encompassing dynamic evaluation that demand sophisticated LLM interactions. Secondly, the framework integrates meta-evaluation techniques like human evaluation and data contamination detection, which, along with dynamic evaluation modules in the platform, enhance the fairness of the evaluation outcomes. Lastly, FreeEval is designed with a high-performance infrastructure, including distributed computation and caching strategies, enabling extensive evaluations across multi-node, multi-GPU clusters for open-source and proprietary LLMs.
Apollo: An Lightweight Multilingual Medical LLM towards Democratizing Medical AI to 6B People
Mar 09, 2024
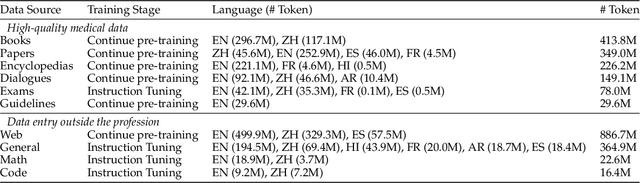

Despite the vast repository of global medical knowledge predominantly being in English, local languages are crucial for delivering tailored healthcare services, particularly in areas with limited medical resources. To extend the reach of medical AI advancements to a broader population, we aim to develop medical LLMs across the six most widely spoken languages, encompassing a global population of 6.1 billion. This effort culminates in the creation of the ApolloCorpora multilingual medical dataset and the XMedBench benchmark. In the multilingual medical benchmark, the released Apollo models, at various relatively-small sizes (i.e., 0.5B, 1.8B, 2B, 6B, and 7B), achieve the best performance among models of equivalent size. Especially, Apollo-7B is the state-of-the-art multilingual medical LLMs up to 70B. Additionally, these lite models could be used to improve the multi-lingual medical capabilities of larger models without fine-tuning in a proxy-tuning fashion. We will open-source training corpora, code, model weights and evaluation benchmark.
KIEval: A Knowledge-grounded Interactive Evaluation Framework for Large Language Models
Feb 23, 2024Automatic evaluation methods for large language models (LLMs) are hindered by data contamination, leading to inflated assessments of their effectiveness. Existing strategies, which aim to detect contaminated texts, focus on quantifying contamination status instead of accurately gauging model performance. In this paper, we introduce KIEval, a Knowledge-grounded Interactive Evaluation framework, which incorporates an LLM-powered "interactor" role for the first time to accomplish a dynamic contamination-resilient evaluation. Starting with a question in a conventional LLM benchmark involving domain-specific knowledge, KIEval utilizes dynamically generated, multi-round, and knowledge-focused dialogues to determine whether a model's response is merely a recall of benchmark answers or demonstrates a deep comprehension to apply knowledge in more complex conversations. Extensive experiments on seven leading LLMs across five datasets validate KIEval's effectiveness and generalization. We also reveal that data contamination brings no contribution or even negative effect to models' real-world applicability and understanding, and existing contamination detection methods for LLMs can only identify contamination in pre-training but not during supervised fine-tuning.
A General Framework for Learning from Weak Supervision
Feb 02, 2024Weakly supervised learning generally faces challenges in applicability to various scenarios with diverse weak supervision and in scalability due to the complexity of existing algorithms, thereby hindering the practical deployment. This paper introduces a general framework for learning from weak supervision (GLWS) with a novel algorithm. Central to GLWS is an Expectation-Maximization (EM) formulation, adeptly accommodating various weak supervision sources, including instance partial labels, aggregate statistics, pairwise observations, and unlabeled data. We further present an advanced algorithm that significantly simplifies the EM computational demands using a Non-deterministic Finite Automaton (NFA) along with a forward-backward algorithm, which effectively reduces time complexity from quadratic or factorial often required in existing solutions to linear scale. The problem of learning from arbitrary weak supervision is therefore converted to the NFA modeling of them. GLWS not only enhances the scalability of machine learning models but also demonstrates superior performance and versatility across 11 weak supervision scenarios. We hope our work paves the way for further advancements and practical deployment in this field.
Supervised Knowledge Makes Large Language Models Better In-context Learners
Dec 26, 2023Large Language Models (LLMs) exhibit emerging in-context learning abilities through prompt engineering. The recent progress in large-scale generative models has further expanded their use in real-world language applications. However, the critical challenge of improving the generalizability and factuality of LLMs in natural language understanding and question answering remains under-explored. While previous in-context learning research has focused on enhancing models to adhere to users' specific instructions and quality expectations, and to avoid undesired outputs, little to no work has explored the use of task-Specific fine-tuned Language Models (SLMs) to improve LLMs' in-context learning during the inference stage. Our primary contribution is the establishment of a simple yet effective framework that enhances the reliability of LLMs as it: 1) generalizes out-of-distribution data, 2) elucidates how LLMs benefit from discriminative models, and 3) minimizes hallucinations in generative tasks. Using our proposed plug-in method, enhanced versions of Llama 2 and ChatGPT surpass their original versions regarding generalizability and factuality. We offer a comprehensive suite of resources, including 16 curated datasets, prompts, model checkpoints, and LLM outputs across 9 distinct tasks. Our empirical analysis sheds light on the advantages of incorporating discriminative models into LLMs and highlights the potential of our methodology in fostering more reliable LLMs.
Survey on Factuality in Large Language Models: Knowledge, Retrieval and Domain-Specificity
Oct 18, 2023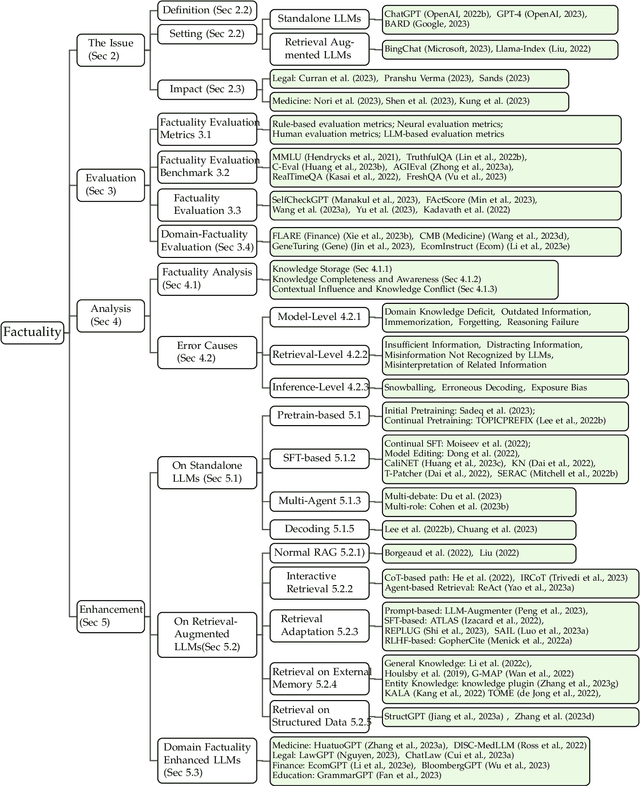
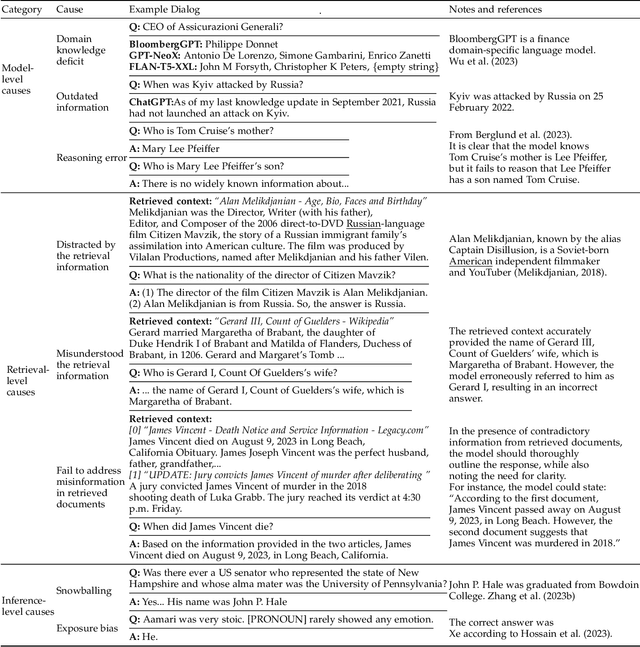
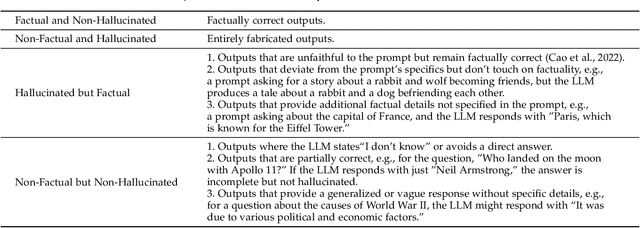
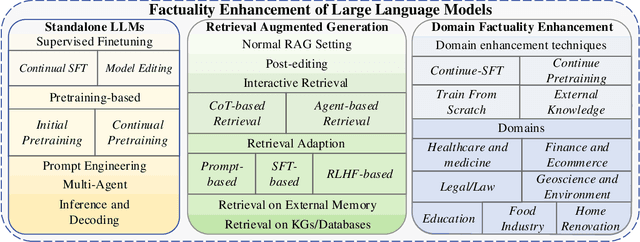
This survey addresses the crucial issue of factuality in Large Language Models (LLMs). As LLMs find applications across diverse domains, the reliability and accuracy of their outputs become vital. We define the Factuality Issue as the probability of LLMs to produce content inconsistent with established facts. We first delve into the implications of these inaccuracies, highlighting the potential consequences and challenges posed by factual errors in LLM outputs. Subsequently, we analyze the mechanisms through which LLMs store and process facts, seeking the primary causes of factual errors. Our discussion then transitions to methodologies for evaluating LLM factuality, emphasizing key metrics, benchmarks, and studies. We further explore strategies for enhancing LLM factuality, including approaches tailored for specific domains. We focus two primary LLM configurations standalone LLMs and Retrieval-Augmented LLMs that utilizes external data, we detail their unique challenges and potential enhancements. Our survey offers a structured guide for researchers aiming to fortify the factual reliability of LLMs.
A Survey on Evaluation of Large Language Models
Jul 18, 2023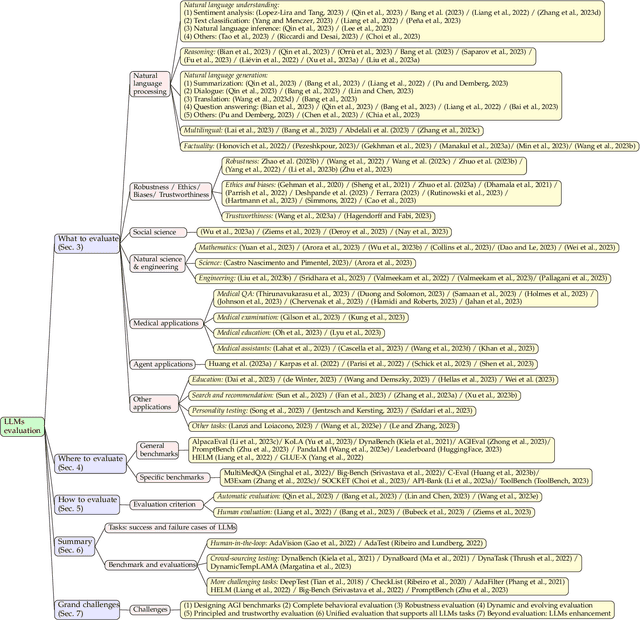
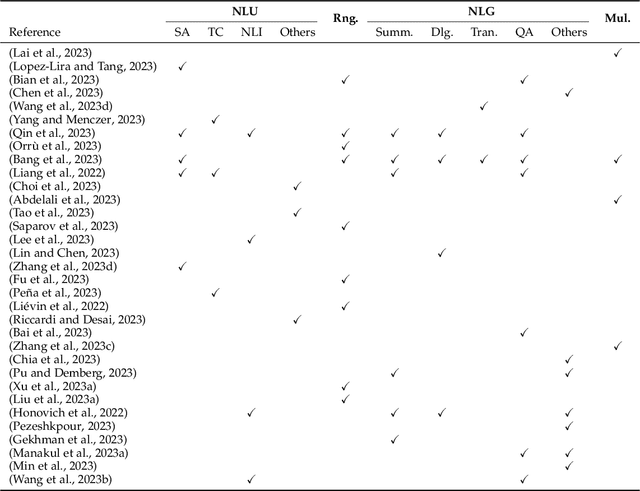
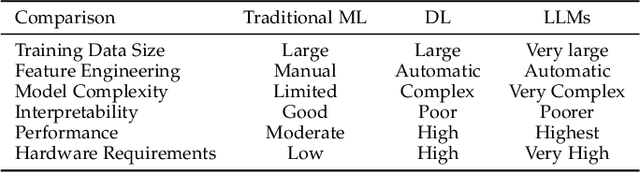
Large language models (LLMs) are gaining increasing popularity in both academia and industry, owing to their unprecedented performance in various applications. As LLMs continue to play a vital role in both research and daily use, their evaluation becomes increasingly critical, not only at the task level, but also at the society level for better understanding of their potential risks. Over the past years, significant efforts have been made to examine LLMs from various perspectives. This paper presents a comprehensive review of these evaluation methods for LLMs, focusing on three key dimensions: what to evaluate, where to evaluate, and how to evaluate. Firstly, we provide an overview from the perspective of evaluation tasks, encompassing general natural language processing tasks, reasoning, medical usage, ethics, educations, natural and social sciences, agent applications, and other areas. Secondly, we answer the `where' and `how' questions by diving into the evaluation methods and benchmarks, which serve as crucial components in assessing performance of LLMs. Then, we summarize the success and failure cases of LLMs in different tasks. Finally, we shed light on several future challenges that lie ahead in LLMs evaluation. Our aim is to offer invaluable insights to researchers in the realm of LLMs evaluation, thereby aiding the development of more proficient LLMs. Our key point is that evaluation should be treated as an essential discipline to better assist the development of LLMs. We consistently maintain the related open-source materials at: https://github.com/MLGroupJLU/LLM-eval-survey.
PromptBench: Towards Evaluating the Robustness of Large Language Models on Adversarial Prompts
Jun 13, 2023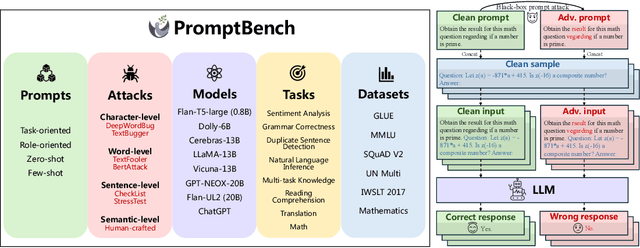
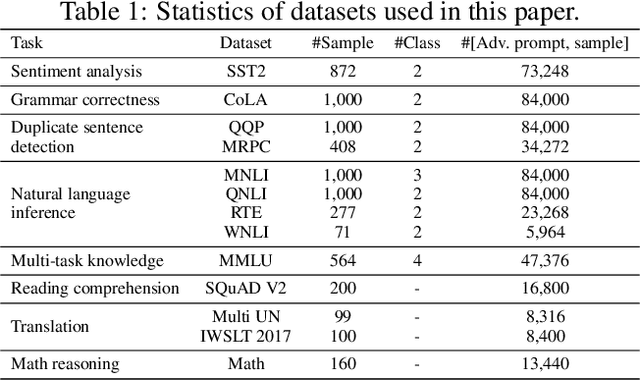
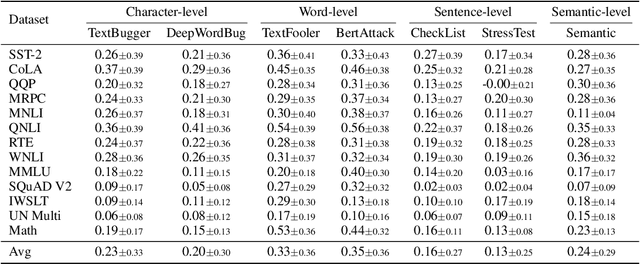

The increasing reliance on Large Language Models (LLMs) across academia and industry necessitates a comprehensive understanding of their robustness to prompts. In response to this vital need, we introduce PromptBench, a robustness benchmark designed to measure LLMs' resilience to adversarial prompts. This study uses a plethora of adversarial textual attacks targeting prompts across multiple levels: character, word, sentence, and semantic. These prompts are then employed in diverse tasks, such as sentiment analysis, natural language inference, reading comprehension, machine translation, and math problem-solving. Our study generates 4,032 adversarial prompts, meticulously evaluated over 8 tasks and 13 datasets, with 567,084 test samples in total. Our findings demonstrate that contemporary LLMs are vulnerable to adversarial prompts. Furthermore, we present comprehensive analysis to understand the mystery behind prompt robustness and its transferability. We then offer insightful robustness analysis and pragmatic recommendations for prompt composition, beneficial to both researchers and everyday users. We make our code, prompts, and methodologies to generate adversarial prompts publicly accessible, thereby enabling and encouraging collaborative exploration in this pivotal field: https://github.com/microsoft/promptbench.
PandaLM: An Automatic Evaluation Benchmark for LLM Instruction Tuning Optimization
Jun 08, 2023
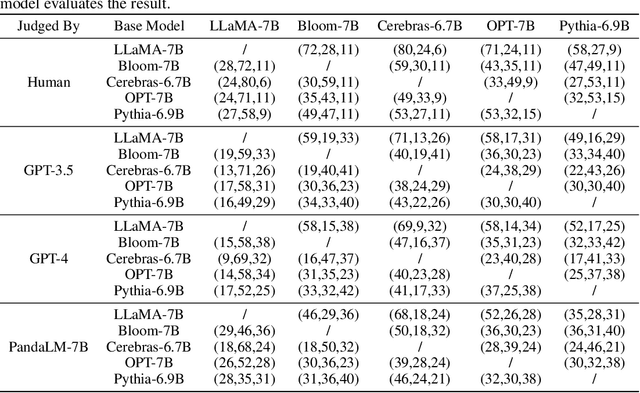
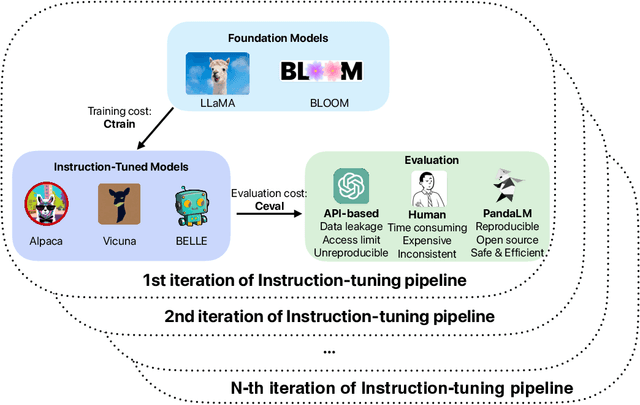
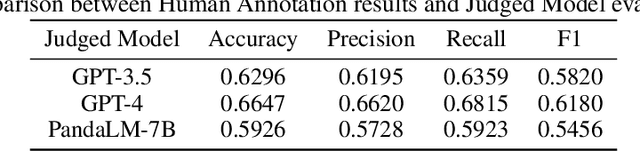
Instruction tuning large language models (LLMs) remains a challenging task, owing to the complexity of hyperparameter selection and the difficulty involved in evaluating the tuned models. To determine the optimal hyperparameters, an automatic, robust, and reliable evaluation benchmark is essential. However, establishing such a benchmark is not a trivial task due to the challenges associated with evaluation accuracy and privacy protection. In response to these challenges, we introduce a judge large language model, named PandaLM, which is trained to distinguish the superior model given several LLMs. PandaLM's focus extends beyond just the objective correctness of responses, which is the main focus of traditional evaluation datasets. It addresses vital subjective factors such as relative conciseness, clarity, adherence to instructions, comprehensiveness, and formality. To ensure the reliability of PandaLM, we collect a diverse human-annotated test dataset, where all contexts are generated by humans and labels are aligned with human preferences. Our results indicate that PandaLM-7B achieves 93.75% of GPT-3.5's evaluation ability and 88.28% of GPT-4's in terms of F1-score on our test dataset. PandaLM enables the evaluation of LLM to be fairer but with less cost, evidenced by significant improvements achieved by models tuned through PandaLM compared to their counterparts trained with default Alpaca's hyperparameters. In addition, PandaLM does not depend on API-based evaluations, thus avoiding potential data leakage. All resources of PandaLM are released at https://github.com/WeOpenML/PandaLM.
Imprecise Label Learning: A Unified Framework for Learning with Various Imprecise Label Configurations
May 23, 2023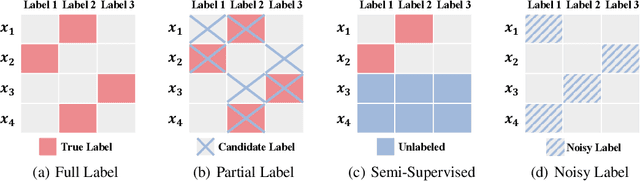
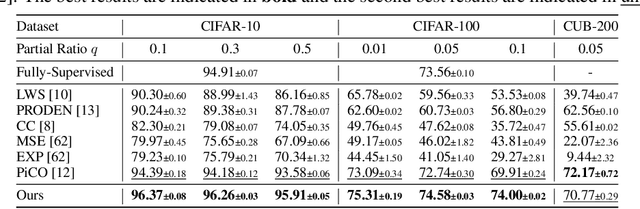

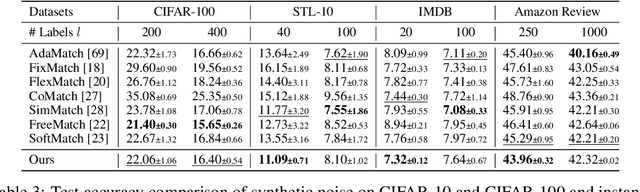
In this paper, we introduce the imprecise label learning (ILL) framework, a unified approach to handle various imprecise label configurations, which are commonplace challenges in machine learning tasks. ILL leverages an expectation-maximization (EM) algorithm for the maximum likelihood estimation (MLE) of the imprecise label information, treating the precise labels as latent variables. Compared to previous versatile methods attempting to infer correct labels from the imprecise label information, our ILL framework considers all possible labeling imposed by the imprecise label information, allowing a unified solution to deal with any imprecise labels. With comprehensive experimental results, we demonstrate that ILL can seamlessly adapt to various situations, including partial label learning, semi-supervised learning, noisy label learning, and a mixture of these settings. Notably, our simple method surpasses the existing techniques for handling imprecise labels, marking the first unified framework with robust and effective performance across various imprecise labels. We believe that our approach has the potential to significantly enhance the performance of machine learning models on tasks where obtaining precise labels is expensive and complicated. We hope our work will inspire further research on this topic with an open-source codebase release.