 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXu Wang
Delayed Bottlenecking: Alleviating Forgetting in Pre-trained Graph Neural Networks
Apr 23, 2024
Pre-training GNNs to extract transferable knowledge and apply it to downstream tasks has become the de facto standard of graph representation learning. Recent works focused on designing self-supervised pre-training tasks to extract useful and universal transferable knowledge from large-scale unlabeled data. However, they have to face an inevitable question: traditional pre-training strategies that aim at extracting useful information about pre-training tasks, may not extract all useful information about the downstream task. In this paper, we reexamine the pre-training process within traditional pre-training and fine-tuning frameworks from the perspective of Information Bottleneck (IB) and confirm that the forgetting phenomenon in pre-training phase may cause detrimental effects on downstream tasks. Therefore, we propose a novel \underline{D}elayed \underline{B}ottlenecking \underline{P}re-training (DBP) framework which maintains as much as possible mutual information between latent representations and training data during pre-training phase by suppressing the compression operation and delays the compression operation to fine-tuning phase to make sure the compression can be guided with labeled fine-tuning data and downstream tasks. To achieve this, we design two information control objectives that can be directly optimized and further integrate them into the actual model design. Extensive experiments on both chemistry and biology domains demonstrate the effectiveness of DBP.
FACTUAL: A Novel Framework for Contrastive Learning Based Robust SAR Image Classification
Apr 04, 2024Deep Learning (DL) Models for Synthetic Aperture Radar (SAR) Automatic Target Recognition (ATR), while delivering improved performance, have been shown to be quite vulnerable to adversarial attacks. Existing works improve robustness by training models on adversarial samples. However, by focusing mostly on attacks that manipulate images randomly, they neglect the real-world feasibility of such attacks. In this paper, we propose FACTUAL, a novel Contrastive Learning framework for Adversarial Training and robust SAR classification. FACTUAL consists of two components: (1) Differing from existing works, a novel perturbation scheme that incorporates realistic physical adversarial attacks (such as OTSA) to build a supervised adversarial pre-training network. This network utilizes class labels for clustering clean and perturbed images together into a more informative feature space. (2) A linear classifier cascaded after the encoder to use the computed representations to predict the target labels. By pre-training and fine-tuning our model on both clean and adversarial samples, we show that our model achieves high prediction accuracy on both cases. Our model achieves 99.7% accuracy on clean samples, and 89.6% on perturbed samples, both outperforming previous state-of-the-art methods.
Weakly-Supervised 3D Scene Graph Generation via Visual-Linguistic Assisted Pseudo-labeling
Apr 03, 2024Learning to build 3D scene graphs is essential for real-world perception in a structured and rich fashion. However, previous 3D scene graph generation methods utilize a fully supervised learning manner and require a large amount of entity-level annotation data of objects and relations, which is extremely resource-consuming and tedious to obtain. To tackle this problem, we propose 3D-VLAP, a weakly-supervised 3D scene graph generation method via Visual-Linguistic Assisted Pseudo-labeling. Specifically, our 3D-VLAP exploits the superior ability of current large-scale visual-linguistic models to align the semantics between texts and 2D images, as well as the naturally existing correspondences between 2D images and 3D point clouds, and thus implicitly constructs correspondences between texts and 3D point clouds. First, we establish the positional correspondence from 3D point clouds to 2D images via camera intrinsic and extrinsic parameters, thereby achieving alignment of 3D point clouds and 2D images. Subsequently, a large-scale cross-modal visual-linguistic model is employed to indirectly align 3D instances with the textual category labels of objects by matching 2D images with object category labels. The pseudo labels for objects and relations are then produced for 3D-VLAP model training by calculating the similarity between visual embeddings and textual category embeddings of objects and relations encoded by the visual-linguistic model, respectively. Ultimately, we design an edge self-attention based graph neural network to generate scene graphs of 3D point cloud scenes. Extensive experiments demonstrate that our 3D-VLAP achieves comparable results with current advanced fully supervised methods, meanwhile significantly alleviating the pressure of data annotation.
Semi-Instruct: Bridging Natural-Instruct and Self-Instruct for Code Large Language Models
Mar 01, 2024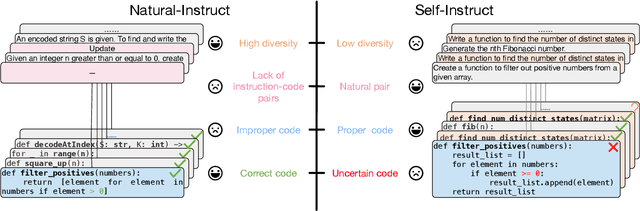
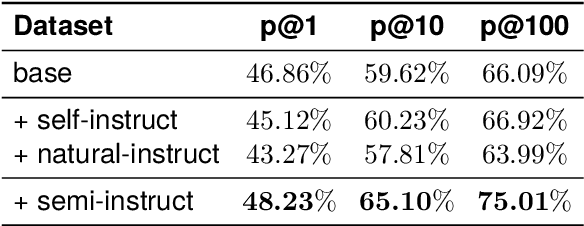
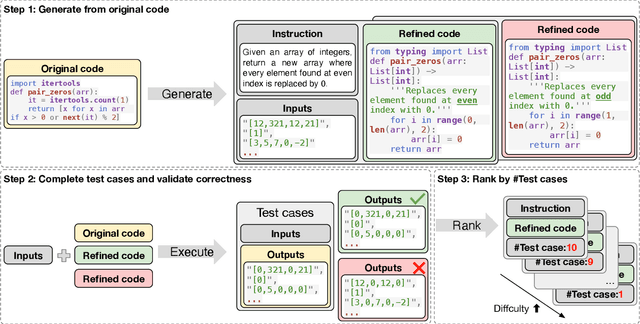
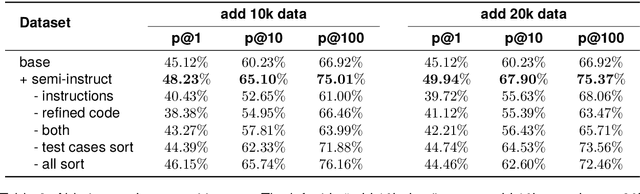
Instruction tuning plays a pivotal role in Code Large Language Models (Code LLMs) for the task of program synthesis. Presently, two dominant paradigms for collecting tuning data are natural-instruct (human-written) and self-instruct (automatically generated). Natural-instruct includes diverse and correct codes but lacks instruction-code pairs, and exists improper code formats like nested single-line codes. In contrast, self-instruct automatically generates proper paired data. However, it suffers from low diversity due to generating duplicates and cannot ensure the correctness of codes. To bridge the both paradigms, we propose \textbf{Semi-Instruct}. It first converts diverse but improper codes from natural-instruct into proper instruction-code pairs through a method similar to self-instruct. To verify the correctness of generated codes, we design a novel way to construct test cases by generating cases' inputs and executing correct codes from natural-instruct to get outputs. Finally, diverse and correct instruction-code pairs are retained for instruction tuning. Experiments show that semi-instruct is significantly better than natural-instruct and self-instruct. Furthermore, the performance steadily improves as data scale increases.
Surgment: Segmentation-enabled Semantic Search and Creation of Visual Question and Feedback to Support Video-Based Surgery Learning
Feb 27, 2024Videos are prominent learning materials to prepare surgical trainees before they enter the operating room (OR). In this work, we explore techniques to enrich the video-based surgery learning experience. We propose Surgment, a system that helps expert surgeons create exercises with feedback based on surgery recordings. Surgment is powered by a few-shot-learning-based pipeline (SegGPT+SAM) to segment surgery scenes, achieving an accuracy of 92\%. The segmentation pipeline enables functionalities to create visual questions and feedback desired by surgeons from a formative study. Surgment enables surgeons to 1) retrieve frames of interest through sketches, and 2) design exercises that target specific anatomical components and offer visual feedback. In an evaluation study with 11 surgeons, participants applauded the search-by-sketch approach for identifying frames of interest and found the resulting image-based questions and feedback to be of high educational value.
Decentralized Federated Unlearning on Blockchain
Feb 26, 2024Blockchained Federated Learning (FL) has been gaining traction for ensuring the integrity and traceability of FL processes. Blockchained FL involves participants training models locally with their data and subsequently publishing the models on the blockchain, forming a Directed Acyclic Graph (DAG)-like inheritance structure that represents the model relationship. However, this particular DAG-based structure presents challenges in updating models with sensitive data, due to the complexity and overhead involved. To address this, we propose Blockchained Federated Unlearning (BlockFUL), a generic framework that redesigns the blockchain structure using Chameleon Hash (CH) technology to mitigate the complexity of model updating, thereby reducing the computational and consensus costs of unlearning tasks.Furthermore, BlockFUL supports various federated unlearning methods, ensuring the integrity and traceability of model updates, whether conducted in parallel or serial. We conduct a comprehensive study of two typical unlearning methods, gradient ascent and re-training, demonstrating the efficient unlearning workflow in these two categories with minimal CH and block update operations. Additionally, we compare the computation and communication costs of these methods.
MultiPoT: Multilingual Program of Thoughts Harnesses Multiple Programming Languages
Feb 16, 2024Program of Thoughts (PoT) is an approach characterized by its executable intermediate steps, which ensure the accuracy of the numerical calculations in the reasoning process. Currently, PoT primarily uses Python. However, relying solely on a single language may result in suboptimal solutions and overlook the potential benefits of other programming languages. In this paper, we conduct comprehensive experiments on the programming languages used in PoT and find that no single language consistently delivers optimal performance across all tasks and models. The effectiveness of each language varies depending on the specific scenarios. Inspired by this, we propose a task and model agnostic approach called MultiPoT, which harnesses strength and diversity from various languages. Experimental results reveal that it significantly outperforms Python Self-Consistency. Furthermore, it achieves comparable or superior performance compared to the best monolingual PoT in almost all tasks across all models. In particular, MultiPoT achieves more than 4.6\% improvement on average on both Starcoder and ChatGPT (gpt-3.5-turbo).
3DPFIX: Improving Remote Novices' 3D Printing Troubleshooting through Human-AI Collaboration
Feb 02, 2024The widespread consumer-grade 3D printers and learning resources online enable novices to self-train in remote settings. While troubleshooting plays an essential part of 3D printing, the process remains challenging for many remote novices even with the help of well-developed online sources, such as online troubleshooting archives and online community help. We conducted a formative study with 76 active 3D printing users to learn how remote novices leverage online resources in troubleshooting and their challenges. We found that remote novices cannot fully utilize online resources. For example, the online archives statically provide general information, making it hard to search and relate their unique cases with existing descriptions. Online communities can potentially ease their struggles by providing more targeted suggestions, but a helper who can provide custom help is rather scarce, making it hard to obtain timely assistance. We propose 3DPFIX, an interactive 3D troubleshooting system powered by the pipeline to facilitate Human-AI Collaboration, designed to improve novices' 3D printing experiences and thus help them easily accumulate their domain knowledge. We built 3DPFIX that supports automated diagnosis and solution-seeking. 3DPFIX was built upon shared dialogues about failure cases from Q&A discourses accumulated in online communities. We leverage social annotations (i.e., comments) to build an annotated failure image dataset for AI classifiers and extract a solution pool. Our summative study revealed that using 3DPFIX helped participants spend significantly less effort in diagnosing failures and finding a more accurate solution than relying on their common practice. We also found that 3DPFIX users learn about 3D printing domain-specific knowledge. We discuss the implications of leveraging community-driven data in developing future Human-AI Collaboration designs.
A Survey on Data Augmentation in Large Model Era
Jan 27, 2024Large models, encompassing large language and diffusion models, have shown exceptional promise in approximating human-level intelligence, garnering significant interest from both academic and industrial spheres. However, the training of these large models necessitates vast quantities of high-quality data, and with continuous updates to these models, the existing reservoir of high-quality data may soon be depleted. This challenge has catalyzed a surge in research focused on data augmentation methods. Leveraging large models, these data augmentation techniques have outperformed traditional approaches. This paper offers an exhaustive review of large model-driven data augmentation methods, adopting a comprehensive perspective. We begin by establishing a classification of relevant studies into three main categories: image augmentation, text augmentation, and paired data augmentation. Following this, we delve into various data post-processing techniques pertinent to large model-based data augmentation. Our discussion then expands to encompass the array of applications for these data augmentation methods within natural language processing, computer vision, and audio signal processing. We proceed to evaluate the successes and limitations of large model-based data augmentation across different scenarios. Concluding our review, we highlight prospective challenges and avenues for future exploration in the field of data augmentation. Our objective is to furnish researchers with critical insights, ultimately contributing to the advancement of more sophisticated large models. We consistently maintain the related open-source materials at: https://github.com/MLGroup-JLU/LLM-data-aug-survey.
PepGB: Facilitating peptide drug discovery via graph neural networks
Jan 26, 2024Peptides offer great biomedical potential and serve as promising drug candidates. Currently, the majority of approved peptide drugs are directly derived from well-explored natural human peptides. It is quite necessary to utilize advanced deep learning techniques to identify novel peptide drugs in the vast, unexplored biochemical space. Despite various in silico methods having been developed to accelerate peptide early drug discovery, existing models face challenges of overfitting and lacking generalizability due to the limited size, imbalanced distribution and inconsistent quality of experimental data. In this study, we propose PepGB, a deep learning framework to facilitate peptide early drug discovery by predicting peptide-protein interactions (PepPIs). Employing graph neural networks, PepGB incorporates a fine-grained perturbation module and a dual-view objective with contrastive learning-based peptide pre-trained representation to predict PepPIs. Through rigorous evaluations, we demonstrated that PepGB greatly outperforms baselines and can accurately identify PepPIs for novel targets and peptide hits, thereby contributing to the target identification and hit discovery processes. Next, we derive an extended version, diPepGB, to tackle the bottleneck of modeling highly imbalanced data prevalent in lead generation and optimization processes. Utilizing directed edges to represent relative binding strength between two peptide nodes, diPepGB achieves superior performance in real-world assays. In summary, our proposed frameworks can serve as potent tools to facilitate peptide early drug discovery.