 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaoran Tang
ST-LLM: Large Language Models Are Effective Temporal Learners
Mar 30, 2024
Large Language Models (LLMs) have showcased impressive capabilities in text comprehension and generation, prompting research efforts towards video LLMs to facilitate human-AI interaction at the video level. However, how to effectively encode and understand videos in video-based dialogue systems remains to be solved. In this paper, we investigate a straightforward yet unexplored question: Can we feed all spatial-temporal tokens into the LLM, thus delegating the task of video sequence modeling to the LLMs? Surprisingly, this simple approach yields significant improvements in video understanding. Based upon this, we propose ST-LLM, an effective video-LLM baseline with Spatial-Temporal sequence modeling inside LLM. Furthermore, to address the overhead and stability issues introduced by uncompressed video tokens within LLMs, we develop a dynamic masking strategy with tailor-made training objectives. For particularly long videos, we have also designed a global-local input module to balance efficiency and effectiveness. Consequently, we harness LLM for proficient spatial-temporal modeling, while upholding efficiency and stability. Extensive experimental results attest to the effectiveness of our method. Through a more concise model and training pipeline, ST-LLM establishes a new state-of-the-art result on VideoChatGPT-Bench and MVBench. Codes have been available at https://github.com/TencentARC/ST-LLM.
Surgment: Segmentation-enabled Semantic Search and Creation of Visual Question and Feedback to Support Video-Based Surgery Learning
Feb 27, 2024Videos are prominent learning materials to prepare surgical trainees before they enter the operating room (OR). In this work, we explore techniques to enrich the video-based surgery learning experience. We propose Surgment, a system that helps expert surgeons create exercises with feedback based on surgery recordings. Surgment is powered by a few-shot-learning-based pipeline (SegGPT+SAM) to segment surgery scenes, achieving an accuracy of 92\%. The segmentation pipeline enables functionalities to create visual questions and feedback desired by surgeons from a formative study. Surgment enables surgeons to 1) retrieve frames of interest through sketches, and 2) design exercises that target specific anatomical components and offer visual feedback. In an evaluation study with 11 surgeons, participants applauded the search-by-sketch approach for identifying frames of interest and found the resulting image-based questions and feedback to be of high educational value.
Context Matters: Data-Efficient Augmentation of Large Language Models for Scientific Applications
Dec 21, 2023
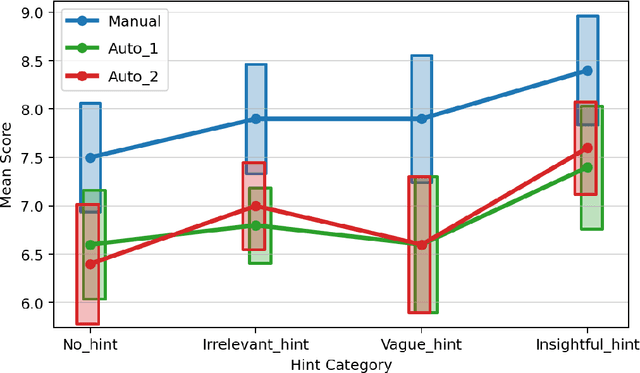

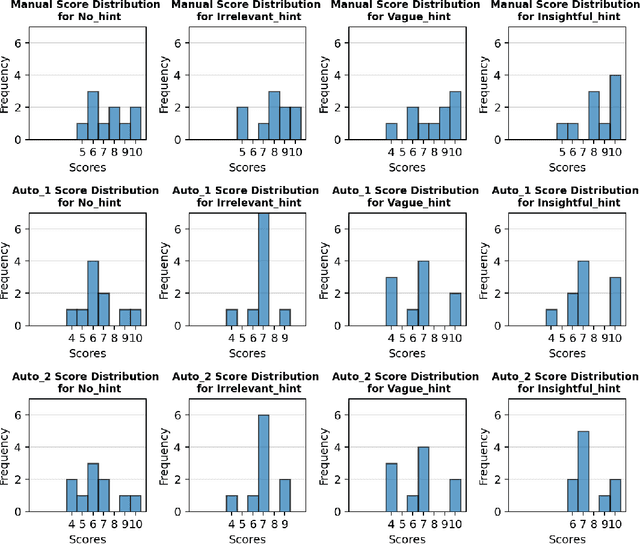
In this paper, we explore the challenges inherent to Large Language Models (LLMs) like GPT-4, particularly their propensity for hallucinations, logic mistakes, and incorrect conclusions when tasked with answering complex questions. The capacity of LLMs to present erroneous answers in a coherent and semantically rigorous manner further complicates the detection of factual inaccuracies. This issue is especially pronounced in fields that require specialized expertise. Our work delves into these challenges, aiming to enhance the understanding and mitigation of such errors, thereby contributing to the improvement of LLM accuracy and reliability in scientific and other specialized domains. Our findings reveal a non-linear relationship between the context's relevancy and the answers' measured quality. In addition, we demonstrate that with the correct calibration, it is possible to automate the grading procedure -- a finding suggesting that, at least to some degree, the LLMs can be used to self-examine the quality of their own performance. Finally, we describe an experimental platform that can be seen as a proof-of-concept of the techniques described in this work.
Retrieving Conditions from Reference Images for Diffusion Models
Dec 05, 2023Recent diffusion-based subject driven generative methods have enabled image generations with good fidelity for specific objects or human portraits. However, to achieve better versatility for applications, we argue that not only improved datasets and evaluations are desired, but also more careful methods to retrieve only relevant information from conditional images are anticipated. To this end, we propose an anime figures dataset RetriBooru-V1, with enhanced identity and clothing labels. We state new tasks enabled by this dataset, and introduce a new diversity metric to measure success in completing these tasks, quantifying the flexibility of image generations. We establish an RAG-inspired baseline method, designed to retrieve precise conditional information from reference images. Then, we compare with current methods on existing task to demonstrate the capability of the proposed method. Finally, we provide baseline experiment results on new tasks, and conduct ablation studies on the possible structural choices.
Weighted Joint Maximum Mean Discrepancy Enabled Multi-Source-Multi-Target Unsupervised Domain Adaptation Fault Diagnosis
Oct 20, 2023Despite the remarkable results that can be achieved by data-driven intelligent fault diagnosis techniques, they presuppose the same distribution of training and test data as well as sufficient labeled data. Various operating states often exist in practical scenarios, leading to the problem of domain shift that hinders the effectiveness of fault diagnosis. While recent unsupervised domain adaptation methods enable cross-domain fault diagnosis, they struggle to effectively utilize information from multiple source domains and achieve effective diagnosis faults in multiple target domains simultaneously. In this paper, we innovatively proposed a weighted joint maximum mean discrepancy enabled multi-source-multi-target unsupervised domain adaptation (WJMMD-MDA), which realizes domain adaptation under multi-source-multi-target scenarios in the field of fault diagnosis for the first time. The proposed method extracts sufficient information from multiple labeled source domains and achieves domain alignment between source and target domains through an improved weighted distance loss. As a result, domain-invariant and discriminative features between multiple source and target domains are learned with cross-domain fault diagnosis realized. The performance of the proposed method is evaluated in comprehensive comparative experiments on three datasets, and the experimental results demonstrate the superiority of this method.
HashEncoding: Autoencoding with Multiscale Coordinate Hashing
Nov 29, 2022

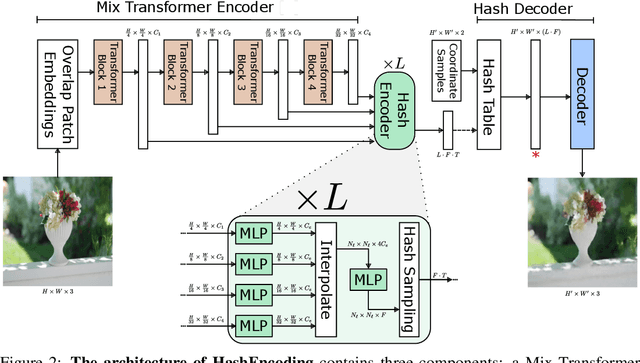

We present HashEncoding, a novel autoencoding architecture that leverages a non-parametric multiscale coordinate hash function to facilitate a per-pixel decoder without convolutions. By leveraging the space-folding behaviour of hashing functions, HashEncoding allows for an inherently multiscale embedding space that remains much smaller than the original image. As a result, the decoder requires very few parameters compared with decoders in traditional autoencoders, approaching a non-parametric reconstruction of the original image and allowing for greater generalizability. Finally, by allowing backpropagation directly to the coordinate space, we show that HashEncoding can be exploited for geometric tasks such as optical flow.
Is Self-Supervised Learning More Robust Than Supervised Learning?
Jun 10, 2022
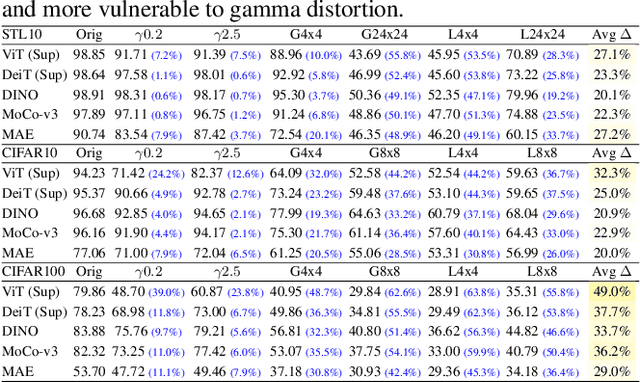
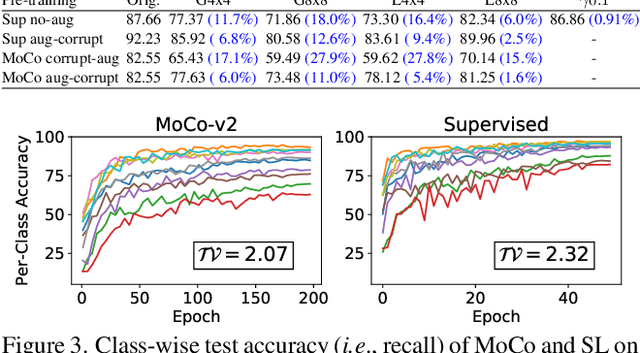

Self-supervised contrastive learning is a powerful tool to learn visual representation without labels. Prior work has primarily focused on evaluating the recognition accuracy of various pre-training algorithms, but has overlooked other behavioral aspects. In addition to accuracy, distributional robustness plays a critical role in the reliability of machine learning models. We design and conduct a series of robustness tests to quantify the behavioral differences between contrastive learning and supervised learning to downstream or pre-training data distribution changes. These tests leverage data corruptions at multiple levels, ranging from pixel-level gamma distortion to patch-level shuffling and to dataset-level distribution shift. Our tests unveil intriguing robustness behaviors of contrastive and supervised learning. On the one hand, under downstream corruptions, we generally observe that contrastive learning is surprisingly more robust than supervised learning. On the other hand, under pre-training corruptions, we find contrastive learning vulnerable to patch shuffling and pixel intensity change, yet less sensitive to dataset-level distribution change. We attempt to explain these results through the role of data augmentation and feature space properties. Our insight has implications in improving the downstream robustness of supervised learning.
Shuffle Augmentation of Features from Unlabeled Data for Unsupervised Domain Adaptation
Jan 28, 2022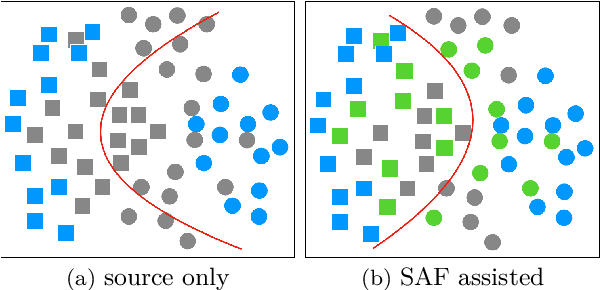
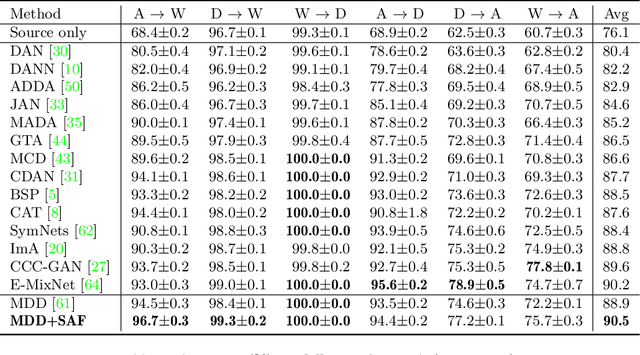
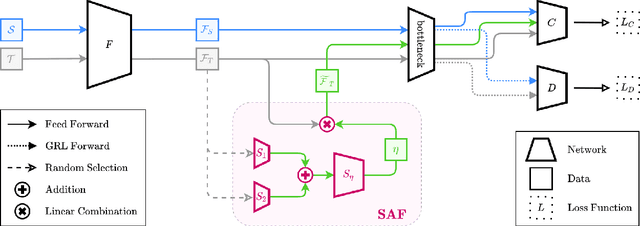
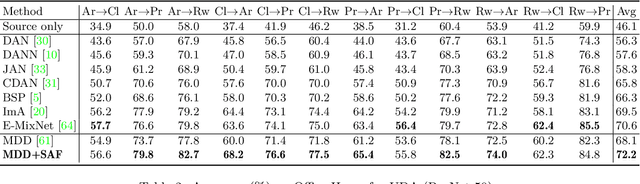
Unsupervised Domain Adaptation (UDA), a branch of transfer learning where labels for target samples are unavailable, has been widely researched and developed in recent years with the help of adversarially trained models. Although existing UDA algorithms are able to guide neural networks to extract transferable and discriminative features, classifiers are merely trained under the supervision of labeled source data. Given the inevitable discrepancy between source and target domains, the classifiers can hardly be aware of the target classification boundaries. In this paper, Shuffle Augmentation of Features (SAF), a novel UDA framework, is proposed to address the problem by providing the classifier with supervisory signals from target feature representations. SAF learns from the target samples, adaptively distills class-aware target features, and implicitly guides the classifier to find comprehensive class borders. Demonstrated by extensive experiments, the SAF module can be integrated into any existing adversarial UDA models to achieve performance improvements.
Why Does Hierarchy (Sometimes) Work So Well in Reinforcement Learning?
Sep 23, 2019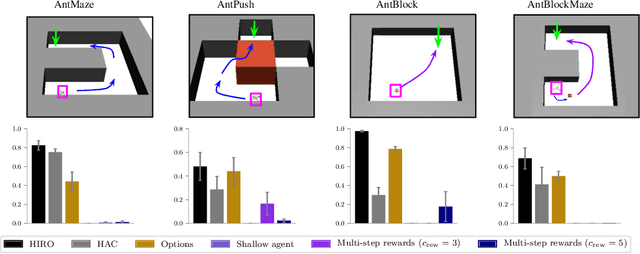
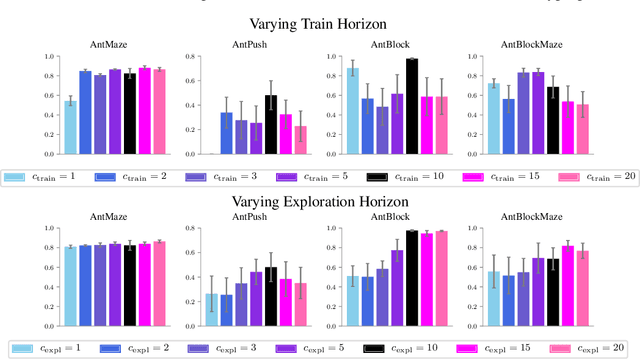
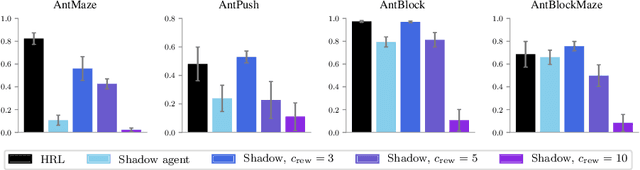
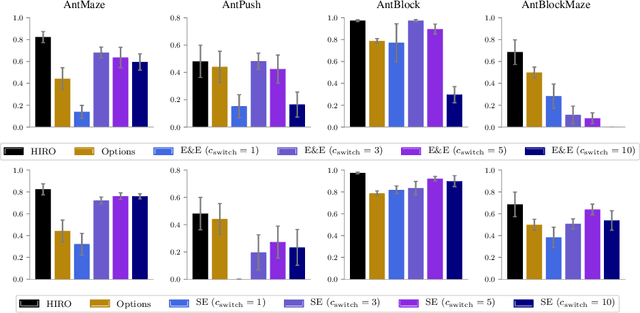
Hierarchical reinforcement learning has demonstrated significant success at solving difficult reinforcement learning (RL) tasks. Previous works have motivated the use of hierarchy by appealing to a number of intuitive benefits, including learning over temporally extended transitions, exploring over temporally extended periods, and training and exploring in a more semantically meaningful action space, among others. However, in fully observed, Markovian settings, it is not immediately clear why hierarchical RL should provide benefits over standard "shallow" RL architectures. In this work, we isolate and evaluate the claimed benefits of hierarchical RL on a suite of tasks encompassing locomotion, navigation, and manipulation. Surprisingly, we find that most of the observed benefits of hierarchy can be attributed to improved exploration, as opposed to easier policy learning or imposed hierarchical structures. Given this insight, we present exploration techniques inspired by hierarchy that achieve performance competitive with hierarchical RL while at the same time being much simpler to use and implement.
Modular Architecture for StarCraft II with Deep Reinforcement Learning
Nov 08, 2018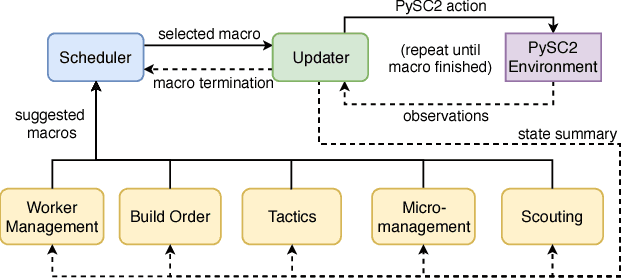

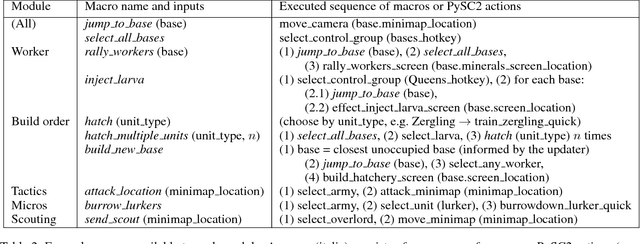
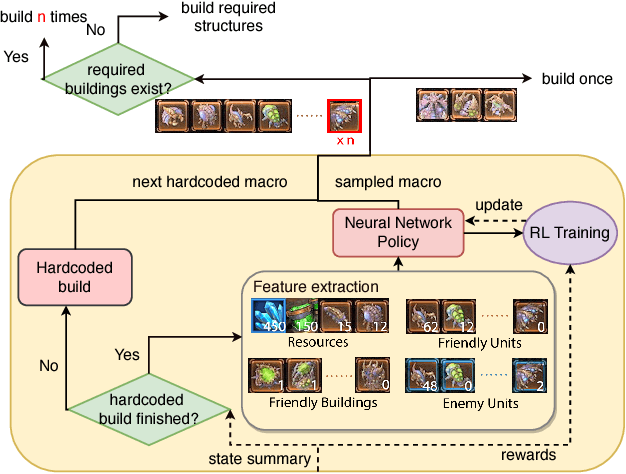
We present a novel modular architecture for StarCraft II AI. The architecture splits responsibilities between multiple modules that each control one aspect of the game, such as build-order selection or tactics. A centralized scheduler reviews macros suggested by all modules and decides their order of execution. An updater keeps track of environment changes and instantiates macros into series of executable actions. Modules in this framework can be optimized independently or jointly via human design, planning, or reinforcement learning. We apply deep reinforcement learning techniques to training two out of six modules of a modular agent with self-play, achieving 94% or 87% win rates against the "Harder" (level 5) built-in Blizzard bot in Zerg vs. Zerg matches, with or without fog-of-war.