 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePieter Abbeel
HumanoidBench: Simulated Humanoid Benchmark for Whole-Body Locomotion and Manipulation
Mar 15, 2024
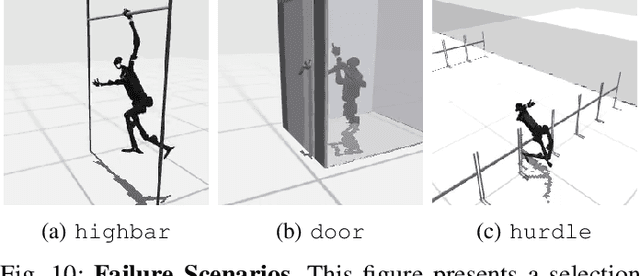

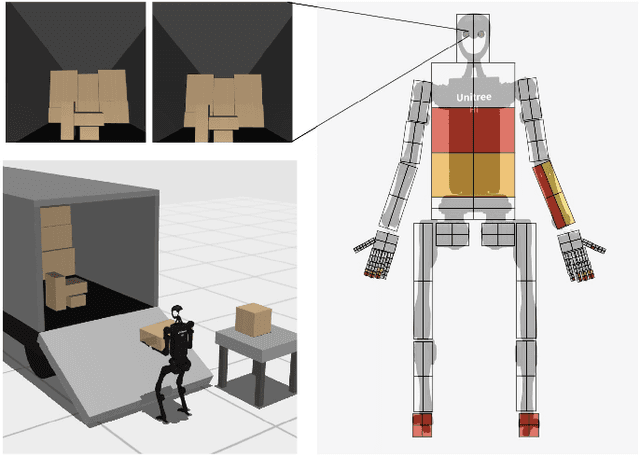

Humanoid robots hold great promise in assisting humans in diverse environments and tasks, due to their flexibility and adaptability leveraging human-like morphology. However, research in humanoid robots is often bottlenecked by the costly and fragile hardware setups. To accelerate algorithmic research in humanoid robots, we present a high-dimensional, simulated robot learning benchmark, HumanoidBench, featuring a humanoid robot equipped with dexterous hands and a variety of challenging whole-body manipulation and locomotion tasks. Our findings reveal that state-of-the-art reinforcement learning algorithms struggle with most tasks, whereas a hierarchical learning baseline achieves superior performance when supported by robust low-level policies, such as walking or reaching. With HumanoidBench, we provide the robotics community with a platform to identify the challenges arising when solving diverse tasks with humanoid robots, facilitating prompt verification of algorithms and ideas. The open-source code is available at https://sferrazza.cc/humanoidbench_site.
Closing the Visual Sim-to-Real Gap with Object-Composable NeRFs
Mar 07, 2024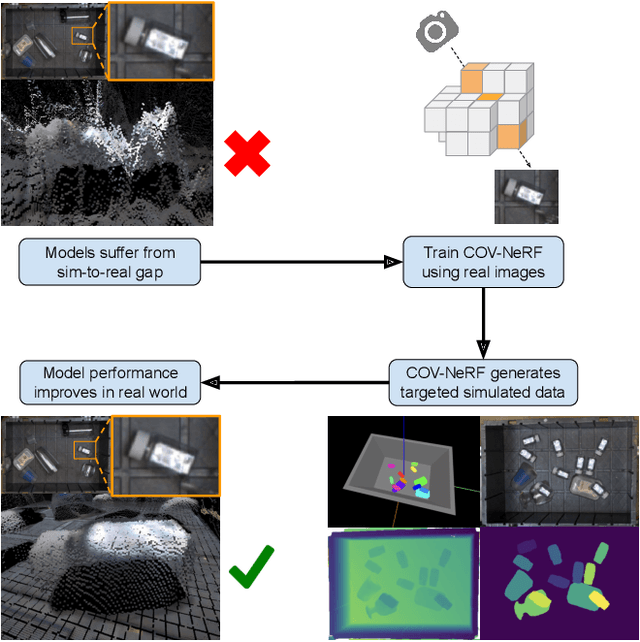
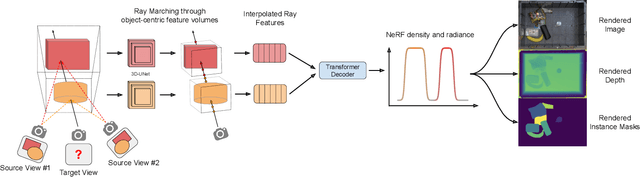


Deep learning methods for perception are the cornerstone of many robotic systems. Despite their potential for impressive performance, obtaining real-world training data is expensive, and can be impractically difficult for some tasks. Sim-to-real transfer with domain randomization offers a potential workaround, but often requires extensive manual tuning and results in models that are brittle to distribution shift between sim and real. In this work, we introduce Composable Object Volume NeRF (COV-NeRF), an object-composable NeRF model that is the centerpiece of a real-to-sim pipeline for synthesizing training data targeted to scenes and objects from the real world. COV-NeRF extracts objects from real images and composes them into new scenes, generating photorealistic renderings and many types of 2D and 3D supervision, including depth maps, segmentation masks, and meshes. We show that COV-NeRF matches the rendering quality of modern NeRF methods, and can be used to rapidly close the sim-to-real gap across a variety of perceptual modalities.
MOKA: Open-Vocabulary Robotic Manipulation through Mark-Based Visual Prompting
Mar 05, 2024
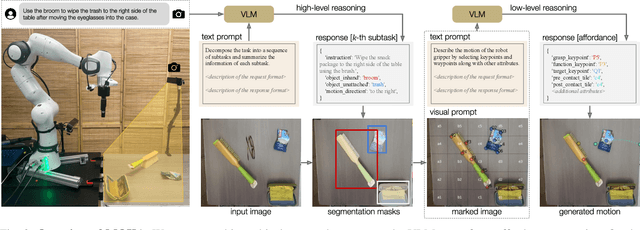

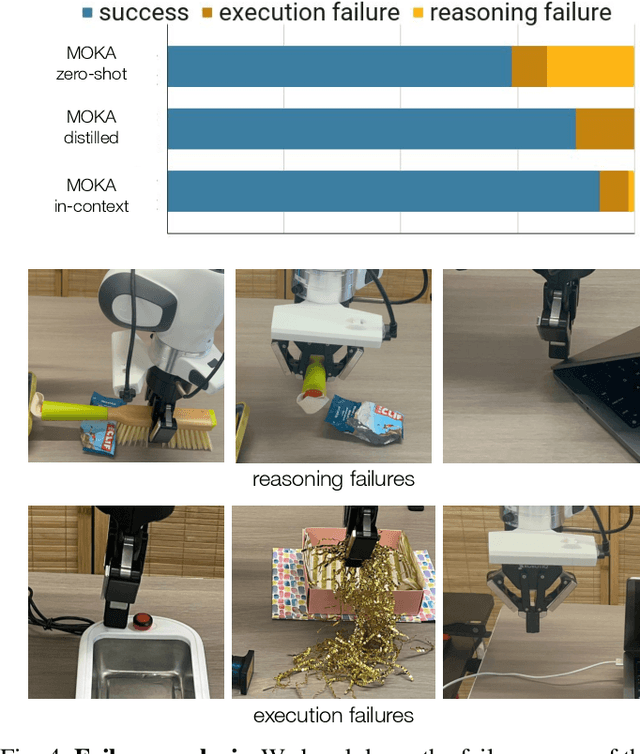
Open-vocabulary generalization requires robotic systems to perform tasks involving complex and diverse environments and task goals. While the recent advances in vision language models (VLMs) present unprecedented opportunities to solve unseen problems, how to utilize their emergent capabilities to control robots in the physical world remains an open question. In this paper, we present MOKA (Marking Open-vocabulary Keypoint Affordances), an approach that employs VLMs to solve robotic manipulation tasks specified by free-form language descriptions. At the heart of our approach is a compact point-based representation of affordance and motion that bridges the VLM's predictions on RGB images and the robot's motions in the physical world. By prompting a VLM pre-trained on Internet-scale data, our approach predicts the affordances and generates the corresponding motions by leveraging the concept understanding and commonsense knowledge from broad sources. To scaffold the VLM's reasoning in zero-shot, we propose a visual prompting technique that annotates marks on the images, converting the prediction of keypoints and waypoints into a series of visual question answering problems that are feasible for the VLM to solve. Using the robot experiences collected in this way, we further investigate ways to bootstrap the performance through in-context learning and policy distillation. We evaluate and analyze MOKA's performance on a variety of manipulation tasks specified by free-form language descriptions, such as tool use, deformable body manipulation, and object rearrangement.
Twisting Lids Off with Two Hands
Mar 04, 2024


Manipulating objects with two multi-fingered hands has been a long-standing challenge in robotics, attributed to the contact-rich nature of many manipulation tasks and the complexity inherent in coordinating a high-dimensional bimanual system. In this work, we consider the problem of twisting lids of various bottle-like objects with two hands, and demonstrate that policies trained in simulation using deep reinforcement learning can be effectively transferred to the real world. With novel engineering insights into physical modeling, real-time perception, and reward design, the policy demonstrates generalization capabilities across a diverse set of unseen objects, showcasing dynamic and dexterous behaviors. Our findings serve as compelling evidence that deep reinforcement learning combined with sim-to-real transfer remains a promising approach for addressing manipulation problems of unprecedented complexity.
Video as the New Language for Real-World Decision Making
Feb 27, 2024Both text and video data are abundant on the internet and support large-scale self-supervised learning through next token or frame prediction. However, they have not been equally leveraged: language models have had significant real-world impact, whereas video generation has remained largely limited to media entertainment. Yet video data captures important information about the physical world that is difficult to express in language. To address this gap, we discuss an under-appreciated opportunity to extend video generation to solve tasks in the real world. We observe how, akin to language, video can serve as a unified interface that can absorb internet knowledge and represent diverse tasks. Moreover, we demonstrate how, like language models, video generation can serve as planners, agents, compute engines, and environment simulators through techniques such as in-context learning, planning and reinforcement learning. We identify major impact opportunities in domains such as robotics, self-driving, and science, supported by recent work that demonstrates how such advanced capabilities in video generation are plausibly within reach. Lastly, we identify key challenges in video generation that mitigate progress. Addressing these challenges will enable video generation models to demonstrate unique value alongside language models in a wider array of AI applications.
Unsupervised Zero-Shot Reinforcement Learning via Functional Reward Encodings
Feb 27, 2024Can we pre-train a generalist agent from a large amount of unlabeled offline trajectories such that it can be immediately adapted to any new downstream tasks in a zero-shot manner? In this work, we present a functional reward encoding (FRE) as a general, scalable solution to this zero-shot RL problem. Our main idea is to learn functional representations of any arbitrary tasks by encoding their state-reward samples using a transformer-based variational auto-encoder. This functional encoding not only enables the pre-training of an agent from a wide diversity of general unsupervised reward functions, but also provides a way to solve any new downstream tasks in a zero-shot manner, given a small number of reward-annotated samples. We empirically show that FRE agents trained on diverse random unsupervised reward functions can generalize to solve novel tasks in a range of simulated robotic benchmarks, often outperforming previous zero-shot RL and offline RL methods. Code for this project is provided at: https://github.com/kvfrans/fre
A StrongREJECT for Empty Jailbreaks
Feb 15, 2024The rise of large language models (LLMs) has drawn attention to the existence of "jailbreaks" that allow the models to be used maliciously. However, there is no standard benchmark for measuring the severity of a jailbreak, leaving authors of jailbreak papers to create their own. We show that these benchmarks often include vague or unanswerable questions and use grading criteria that are biased towards overestimating the misuse potential of low-quality model responses. Some jailbreak techniques make the problem worse by decreasing the quality of model responses even on benign questions: we show that several jailbreaking techniques substantially reduce the zero-shot performance of GPT-4 on MMLU. Jailbreaks can also make it harder to elicit harmful responses from an "uncensored" open-source model. We present a new benchmark, StrongREJECT, which better discriminates between effective and ineffective jailbreaks by using a higher-quality question set and a more accurate response grading algorithm. We show that our new grading scheme better accords with human judgment of response quality and overall jailbreak effectiveness, especially on the sort of low-quality responses that contribute the most to over-estimation of jailbreak performance on existing benchmarks. We release our code and data at https://github.com/alexandrasouly/strongreject.
World Model on Million-Length Video And Language With RingAttention
Feb 13, 2024Current language models fall short in understanding aspects of the world not easily described in words, and struggle with complex, long-form tasks. Video sequences offer valuable temporal information absent in language and static images, making them attractive for joint modeling with language. Such models could develop a understanding of both human textual knowledge and the physical world, enabling broader AI capabilities for assisting humans. However, learning from millions of tokens of video and language sequences poses challenges due to memory constraints, computational complexity, and limited datasets. To address these challenges, we curate a large dataset of diverse videos and books, utilize the RingAttention technique to scalably train on long sequences, and gradually increase context size from 4K to 1M tokens. This paper makes the following contributions: (a) Largest context size neural network: We train one of the largest context size transformers on long video and language sequences, setting new benchmarks in difficult retrieval tasks and long video understanding. (b) Solutions for overcoming vision-language training challenges, including using masked sequence packing for mixing different sequence lengths, loss weighting to balance language and vision, and model-generated QA dataset for long sequence chat. (c) A highly-optimized implementation with RingAttention, masked sequence packing, and other key features for training on millions-length multimodal sequences. (d) Fully open-sourced a family of 7B parameter models capable of processing long text documents (LWM-Text, LWM-Text-Chat) and videos (LWM, LWM-Chat) of over 1M tokens. This work paves the way for training on massive datasets of long video and language to develop understanding of both human knowledge and the multimodal world, and broader capabilities.
Reinforcement Learning for Versatile, Dynamic, and Robust Bipedal Locomotion Control
Jan 30, 2024This paper presents a comprehensive study on using deep reinforcement learning (RL) to create dynamic locomotion controllers for bipedal robots. Going beyond focusing on a single locomotion skill, we develop a general control solution that can be used for a range of dynamic bipedal skills, from periodic walking and running to aperiodic jumping and standing. Our RL-based controller incorporates a novel dual-history architecture, utilizing both a long-term and short-term input/output (I/O) history of the robot. This control architecture, when trained through the proposed end-to-end RL approach, consistently outperforms other methods across a diverse range of skills in both simulation and the real world.The study also delves into the adaptivity and robustness introduced by the proposed RL system in developing locomotion controllers. We demonstrate that the proposed architecture can adapt to both time-invariant dynamics shifts and time-variant changes, such as contact events, by effectively using the robot's I/O history. Additionally, we identify task randomization as another key source of robustness, fostering better task generalization and compliance to disturbances. The resulting control policies can be successfully deployed on Cassie, a torque-controlled human-sized bipedal robot. This work pushes the limits of agility for bipedal robots through extensive real-world experiments. We demonstrate a diverse range of locomotion skills, including: robust standing, versatile walking, fast running with a demonstration of a 400-meter dash, and a diverse set of jumping skills, such as standing long jumps and high jumps.
FMB: a Functional Manipulation Benchmark for Generalizable Robotic Learning
Jan 16, 2024In this paper, we propose a real-world benchmark for studying robotic learning in the context of functional manipulation: a robot needs to accomplish complex long-horizon behaviors by composing individual manipulation skills in functionally relevant ways. The core design principles of our Functional Manipulation Benchmark (FMB) emphasize a harmonious balance between complexity and accessibility. Tasks are deliberately scoped to be narrow, ensuring that models and datasets of manageable scale can be utilized effectively to track progress. Simultaneously, they are diverse enough to pose a significant generalization challenge. Furthermore, the benchmark is designed to be easily replicable, encompassing all essential hardware and software components. To achieve this goal, FMB consists of a variety of 3D-printed objects designed for easy and accurate replication by other researchers. The objects are procedurally generated, providing a principled framework to study generalization in a controlled fashion. We focus on fundamental manipulation skills, including grasping, repositioning, and a range of assembly behaviors. The FMB can be used to evaluate methods for acquiring individual skills, as well as methods for combining and ordering such skills to solve complex, multi-stage manipulation tasks. We also offer an imitation learning framework that includes a suite of policies trained to solve the proposed tasks. This enables researchers to utilize our tasks as a versatile toolkit for examining various parts of the pipeline. For example, researchers could propose a better design for a grasping controller and evaluate it in combination with our baseline reorientation and assembly policies as part of a pipeline for solving multi-stage tasks. Our dataset, object CAD files, code, and evaluation videos can be found on our project website: https://functional-manipulation-benchmark.github.io