 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSherry Yang
Video as the New Language for Real-World Decision Making
Feb 27, 2024
Both text and video data are abundant on the internet and support large-scale self-supervised learning through next token or frame prediction. However, they have not been equally leveraged: language models have had significant real-world impact, whereas video generation has remained largely limited to media entertainment. Yet video data captures important information about the physical world that is difficult to express in language. To address this gap, we discuss an under-appreciated opportunity to extend video generation to solve tasks in the real world. We observe how, akin to language, video can serve as a unified interface that can absorb internet knowledge and represent diverse tasks. Moreover, we demonstrate how, like language models, video generation can serve as planners, agents, compute engines, and environment simulators through techniques such as in-context learning, planning and reinforcement learning. We identify major impact opportunities in domains such as robotics, self-driving, and science, supported by recent work that demonstrates how such advanced capabilities in video generation are plausibly within reach. Lastly, we identify key challenges in video generation that mitigate progress. Addressing these challenges will enable video generation models to demonstrate unique value alongside language models in a wider array of AI applications.
Code as Reward: Empowering Reinforcement Learning with VLMs
Feb 07, 2024Pre-trained Vision-Language Models (VLMs) are able to understand visual concepts, describe and decompose complex tasks into sub-tasks, and provide feedback on task completion. In this paper, we aim to leverage these capabilities to support the training of reinforcement learning (RL) agents. In principle, VLMs are well suited for this purpose, as they can naturally analyze image-based observations and provide feedback (reward) on learning progress. However, inference in VLMs is computationally expensive, so querying them frequently to compute rewards would significantly slowdown the training of an RL agent. To address this challenge, we propose a framework named Code as Reward (VLM-CaR). VLM-CaR produces dense reward functions from VLMs through code generation, thereby significantly reducing the computational burden of querying the VLM directly. We show that the dense rewards generated through our approach are very accurate across a diverse set of discrete and continuous environments, and can be more effective in training RL policies than the original sparse environment rewards.
Foundation Models for Decision Making: Problems, Methods, and Opportunities
Mar 07, 2023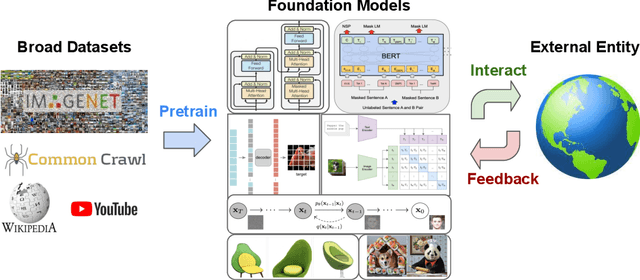
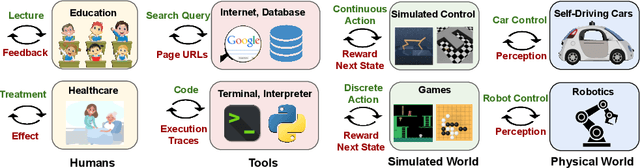


Foundation models pretrained on diverse data at scale have demonstrated extraordinary capabilities in a wide range of vision and language tasks. When such models are deployed in real world environments, they inevitably interface with other entities and agents. For example, language models are often used to interact with human beings through dialogue, and visual perception models are used to autonomously navigate neighborhood streets. In response to these developments, new paradigms are emerging for training foundation models to interact with other agents and perform long-term reasoning. These paradigms leverage the existence of ever-larger datasets curated for multimodal, multitask, and generalist interaction. Research at the intersection of foundation models and decision making holds tremendous promise for creating powerful new systems that can interact effectively across a diverse range of applications such as dialogue, autonomous driving, healthcare, education, and robotics. In this manuscript, we examine the scope of foundation models for decision making, and provide conceptual tools and technical background for understanding the problem space and exploring new research directions. We review recent approaches that ground foundation models in practical decision making applications through a variety of methods such as prompting, conditional generative modeling, planning, optimal control, and reinforcement learning, and discuss common challenges and open problems in the field.
Multi-Environment Pretraining Enables Transfer to Action Limited Datasets
Dec 05, 2022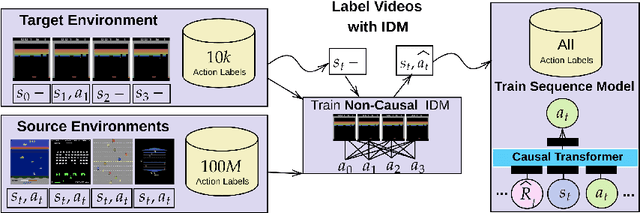

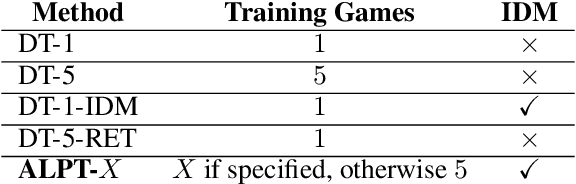
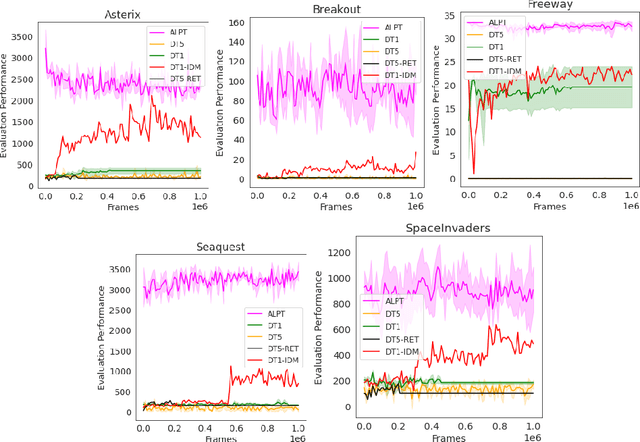
Using massive datasets to train large-scale models has emerged as a dominant approach for broad generalization in natural language and vision applications. In reinforcement learning, however, a key challenge is that available data of sequential decision making is often not annotated with actions - for example, videos of game-play are much more available than sequences of frames paired with their logged game controls. We propose to circumvent this challenge by combining large but sparsely-annotated datasets from a \emph{target} environment of interest with fully-annotated datasets from various other \emph{source} environments. Our method, Action Limited PreTraining (ALPT), leverages the generalization capabilities of inverse dynamics modelling (IDM) to label missing action data in the target environment. We show that utilizing even one additional environment dataset of labelled data during IDM pretraining gives rise to substantial improvements in generating action labels for unannotated sequences. We evaluate our method on benchmark game-playing environments and show that we can significantly improve game performance and generalization capability compared to other approaches, using annotated datasets equivalent to only $12$ minutes of gameplay. Highlighting the power of IDM, we show that these benefits remain even when target and source environments share no common actions.