 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhongyu Li
DiffuseLoco: Real-Time Legged Locomotion Control with Diffusion from Offline Datasets
Apr 30, 2024
This work introduces DiffuseLoco, a framework for training multi-skill diffusion-based policies for dynamic legged locomotion from offline datasets, enabling real-time control of diverse skills on robots in the real world. Offline learning at scale has led to breakthroughs in computer vision, natural language processing, and robotic manipulation domains. However, scaling up learning for legged robot locomotion, especially with multiple skills in a single policy, presents significant challenges for prior online reinforcement learning methods. To address this challenge, we propose a novel, scalable framework that leverages diffusion models to directly learn from offline multimodal datasets with a diverse set of locomotion skills. With design choices tailored for real-time control in dynamical systems, including receding horizon control and delayed inputs, DiffuseLoco is capable of reproducing multimodality in performing various locomotion skills, zero-shot transfer to real quadrupedal robots, and it can be deployed on edge computing devices. Furthermore, DiffuseLoco demonstrates free transitions between skills and robustness against environmental variations. Through extensive benchmarking in real-world experiments, DiffuseLoco exhibits better stability and velocity tracking performance compared to prior reinforcement learning and non-diffusion-based behavior cloning baselines. The design choices are validated via comprehensive ablation studies. This work opens new possibilities for scaling up learning-based legged locomotion controllers through the scaling of large, expressive models and diverse offline datasets.
Ultrasound Nodule Segmentation Using Asymmetric Learning with Simple Clinical Annotation
Apr 23, 2024Recent advances in deep learning have greatly facilitated the automated segmentation of ultrasound images, which is essential for nodule morphological analysis. Nevertheless, most existing methods depend on extensive and precise annotations by domain experts, which are labor-intensive and time-consuming. In this study, we suggest using simple aspect ratio annotations directly from ultrasound clinical diagnoses for automated nodule segmentation. Especially, an asymmetric learning framework is developed by extending the aspect ratio annotations with two types of pseudo labels, i.e., conservative labels and radical labels, to train two asymmetric segmentation networks simultaneously. Subsequently, a conservative-radical-balance strategy (CRBS) strategy is proposed to complementally combine radical and conservative labels. An inconsistency-aware dynamically mixed pseudo-labels supervision (IDMPS) module is introduced to address the challenges of over-segmentation and under-segmentation caused by the two types of labels. To further leverage the spatial prior knowledge provided by clinical annotations, we also present a novel loss function namely the clinical anatomy prior loss. Extensive experiments on two clinically collected ultrasound datasets (thyroid and breast) demonstrate the superior performance of our proposed method, which can achieve comparable and even better performance than fully supervised methods using ground truth annotations.
Long-horizon Locomotion and Manipulation on a Quadrupedal Robot with Large Language Models
Apr 08, 2024We present a large language model (LLM) based system to empower quadrupedal robots with problem-solving abilities for long-horizon tasks beyond short-term motions. Long-horizon tasks for quadrupeds are challenging since they require both a high-level understanding of the semantics of the problem for task planning and a broad range of locomotion and manipulation skills to interact with the environment. Our system builds a high-level reasoning layer with large language models, which generates hybrid discrete-continuous plans as robot code from task descriptions. It comprises multiple LLM agents: a semantic planner for sketching a plan, a parameter calculator for predicting arguments in the plan, and a code generator to convert the plan into executable robot code. At the low level, we adopt reinforcement learning to train a set of motion planning and control skills to unleash the flexibility of quadrupeds for rich environment interactions. Our system is tested on long-horizon tasks that are infeasible to complete with one single skill. Simulation and real-world experiments show that it successfully figures out multi-step strategies and demonstrates non-trivial behaviors, including building tools or notifying a human for help.
Learning Visual Quadrupedal Loco-Manipulation from Demonstrations
Mar 29, 2024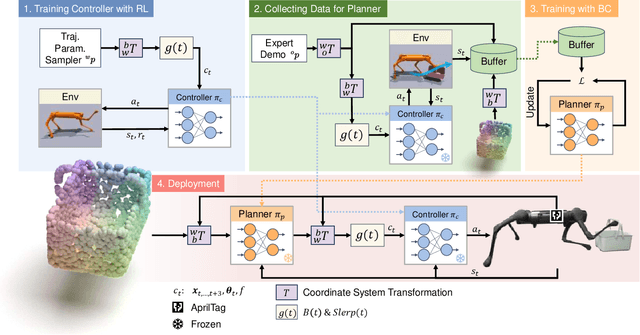

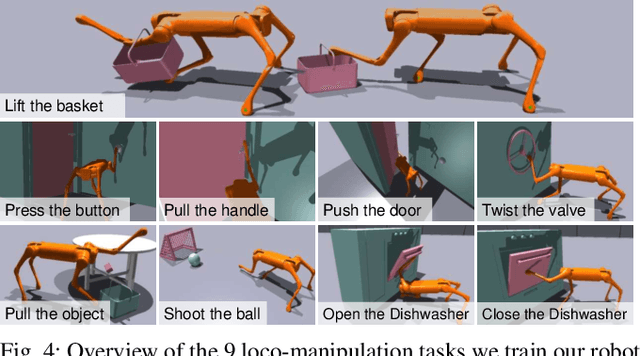
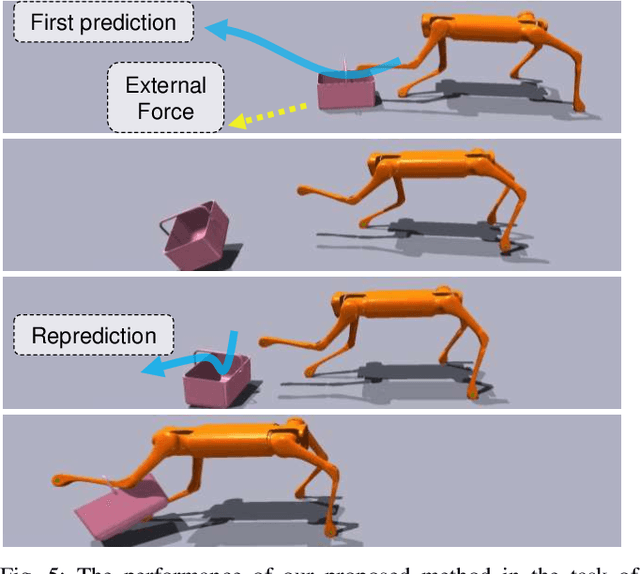
Quadruped robots are progressively being integrated into human environments. Despite the growing locomotion capabilities of quadrupedal robots, their interaction with objects in realistic scenes is still limited. While additional robotic arms on quadrupedal robots enable manipulating objects, they are sometimes redundant given that a quadruped robot is essentially a mobile unit equipped with four limbs, each possessing 3 degrees of freedom (DoFs). Hence, we aim to empower a quadruped robot to execute real-world manipulation tasks using only its legs. We decompose the loco-manipulation process into a low-level reinforcement learning (RL)-based controller and a high-level Behavior Cloning (BC)-based planner. By parameterizing the manipulation trajectory, we synchronize the efforts of the upper and lower layers, thereby leveraging the advantages of both RL and BC. Our approach is validated through simulations and real-world experiments, demonstrating the robot's ability to perform tasks that demand mobility and high precision, such as lifting a basket from the ground while moving, closing a dishwasher, pressing a button, and pushing a door. Project website: https://zhengmaohe.github.io/leg-manip
Leveraging Symmetry in RL-based Legged Locomotion Control
Mar 27, 2024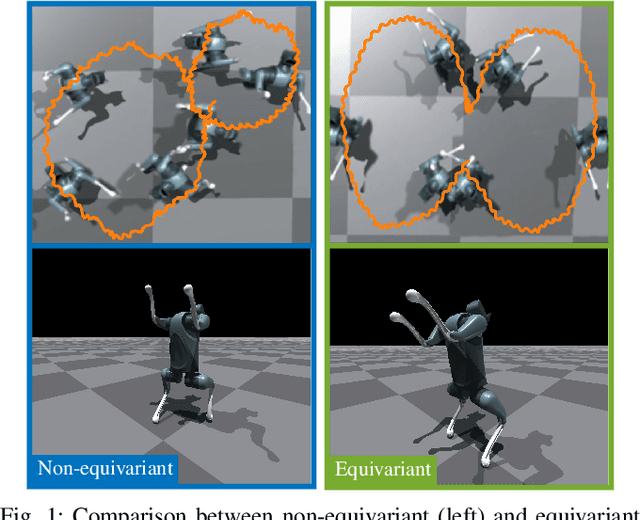
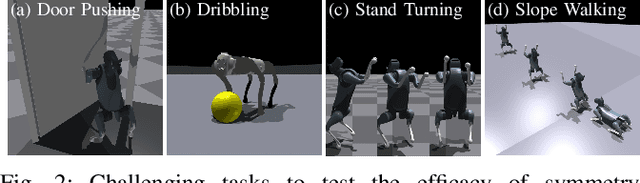

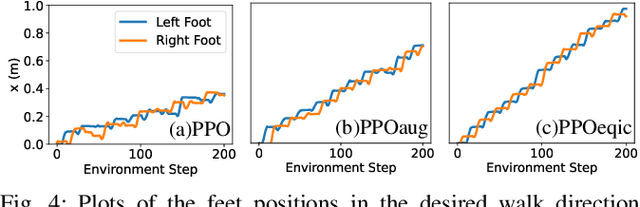
Model-free reinforcement learning is a promising approach for autonomously solving challenging robotics control problems, but faces exploration difficulty without information of the robot's kinematics and dynamics morphology. The under-exploration of multiple modalities with symmetric states leads to behaviors that are often unnatural and sub-optimal. This issue becomes particularly pronounced in the context of robotic systems with morphological symmetries, such as legged robots for which the resulting asymmetric and aperiodic behaviors compromise performance, robustness, and transferability to real hardware. To mitigate this challenge, we can leverage symmetry to guide and improve the exploration in policy learning via equivariance/invariance constraints. In this paper, we investigate the efficacy of two approaches to incorporate symmetry: modifying the network architectures to be strictly equivariant/invariant, and leveraging data augmentation to approximate equivariant/invariant actor-critics. We implement the methods on challenging loco-manipulation and bipedal locomotion tasks and compare with an unconstrained baseline. We find that the strictly equivariant policy consistently outperforms other methods in sample efficiency and task performance in simulation. In addition, symmetry-incorporated approaches exhibit better gait quality, higher robustness and can be deployed zero-shot in real-world experiments.
OpenMEDLab: An Open-source Platform for Multi-modality Foundation Models in Medicine
Mar 04, 2024
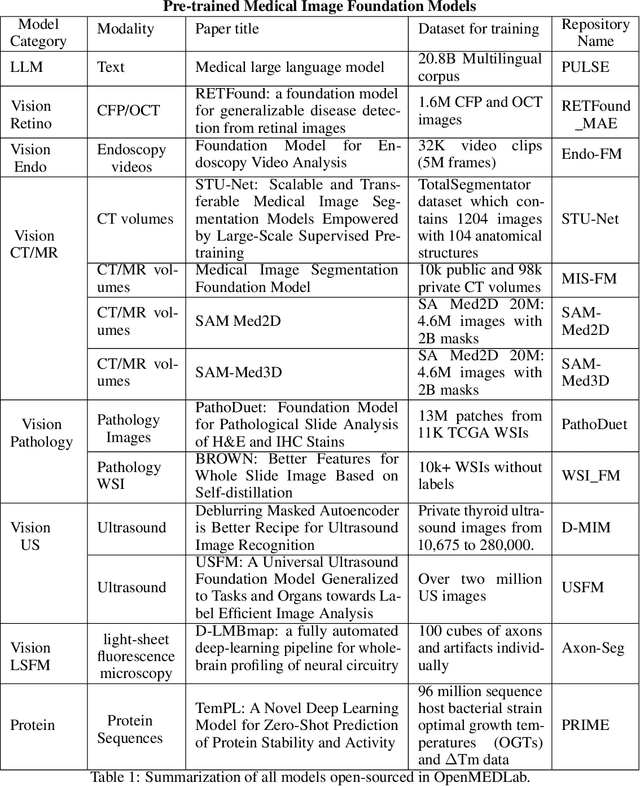
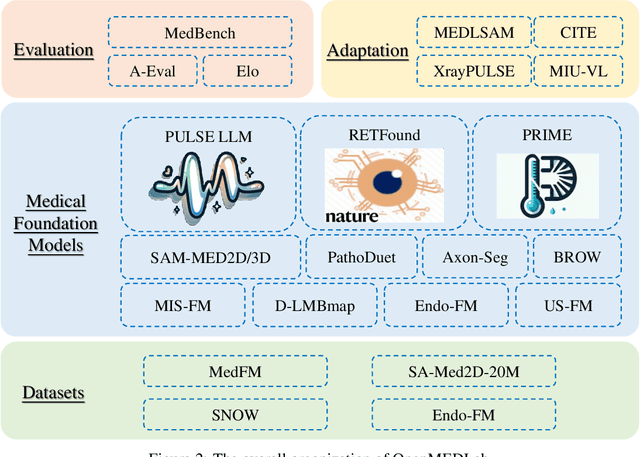
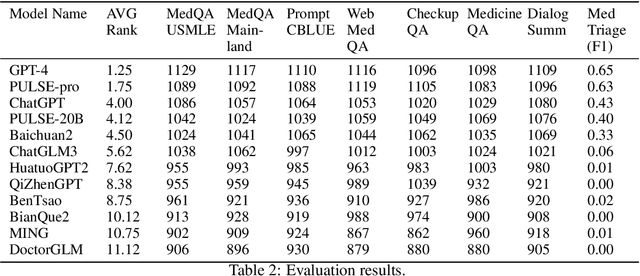
The emerging trend of advancing generalist artificial intelligence, such as GPTv4 and Gemini, has reshaped the landscape of research (academia and industry) in machine learning and many other research areas. However, domain-specific applications of such foundation models (e.g., in medicine) remain untouched or often at their very early stages. It will require an individual set of transfer learning and model adaptation techniques by further expanding and injecting these models with domain knowledge and data. The development of such technologies could be largely accelerated if the bundle of data, algorithms, and pre-trained foundation models were gathered together and open-sourced in an organized manner. In this work, we present OpenMEDLab, an open-source platform for multi-modality foundation models. It encapsulates not only solutions of pioneering attempts in prompting and fine-tuning large language and vision models for frontline clinical and bioinformatic applications but also building domain-specific foundation models with large-scale multi-modal medical data. Importantly, it opens access to a group of pre-trained foundation models for various medical image modalities, clinical text, protein engineering, etc. Inspiring and competitive results are also demonstrated for each collected approach and model in a variety of benchmarks for downstream tasks. We welcome researchers in the field of medical artificial intelligence to continuously contribute cutting-edge methods and models to OpenMEDLab, which can be accessed via https://github.com/openmedlab.
Watch Your Head: Assembling Projection Heads to Save the Reliability of Federated Models
Feb 26, 2024Federated learning encounters substantial challenges with heterogeneous data, leading to performance degradation and convergence issues. While considerable progress has been achieved in mitigating such an impact, the reliability aspect of federated models has been largely disregarded. In this study, we conduct extensive experiments to investigate the reliability of both generic and personalized federated models. Our exploration uncovers a significant finding: \textbf{federated models exhibit unreliability when faced with heterogeneous data}, demonstrating poor calibration on in-distribution test data and low uncertainty levels on out-of-distribution data. This unreliability is primarily attributed to the presence of biased projection heads, which introduce miscalibration into the federated models. Inspired by this observation, we propose the "Assembled Projection Heads" (APH) method for enhancing the reliability of federated models. By treating the existing projection head parameters as priors, APH randomly samples multiple initialized parameters of projection heads from the prior and further performs targeted fine-tuning on locally available data under varying learning rates. Such a head ensemble introduces parameter diversity into the deterministic model, eliminating the bias and producing reliable predictions via head averaging. We evaluate the effectiveness of the proposed APH method across three prominent federated benchmarks. Experimental results validate the efficacy of APH in model calibration and uncertainty estimation. Notably, APH can be seamlessly integrated into various federated approaches but only requires less than 30\% additional computation cost for 100$\times$ inferences within large models.
Reinforcement Learning for Versatile, Dynamic, and Robust Bipedal Locomotion Control
Jan 30, 2024This paper presents a comprehensive study on using deep reinforcement learning (RL) to create dynamic locomotion controllers for bipedal robots. Going beyond focusing on a single locomotion skill, we develop a general control solution that can be used for a range of dynamic bipedal skills, from periodic walking and running to aperiodic jumping and standing. Our RL-based controller incorporates a novel dual-history architecture, utilizing both a long-term and short-term input/output (I/O) history of the robot. This control architecture, when trained through the proposed end-to-end RL approach, consistently outperforms other methods across a diverse range of skills in both simulation and the real world.The study also delves into the adaptivity and robustness introduced by the proposed RL system in developing locomotion controllers. We demonstrate that the proposed architecture can adapt to both time-invariant dynamics shifts and time-variant changes, such as contact events, by effectively using the robot's I/O history. Additionally, we identify task randomization as another key source of robustness, fostering better task generalization and compliance to disturbances. The resulting control policies can be successfully deployed on Cassie, a torque-controlled human-sized bipedal robot. This work pushes the limits of agility for bipedal robots through extensive real-world experiments. We demonstrate a diverse range of locomotion skills, including: robust standing, versatile walking, fast running with a demonstration of a 400-meter dash, and a diverse set of jumping skills, such as standing long jumps and high jumps.
A Decoupled Spatio-Temporal Framework for Skeleton-based Action Segmentation
Dec 10, 2023Effectively modeling discriminative spatio-temporal information is essential for segmenting activities in long action sequences. However, we observe that existing methods are limited in weak spatio-temporal modeling capability due to two forms of decoupled modeling: (i) cascaded interaction couples spatial and temporal modeling, which over-smooths motion modeling over the long sequence, and (ii) joint-shared temporal modeling adopts shared weights to model each joint, ignoring the distinct motion patterns of different joints. We propose a Decoupled Spatio-Temporal Framework (DeST) to address the above issues. Firstly, we decouple the cascaded spatio-temporal interaction to avoid stacking multiple spatio-temporal blocks, while achieving sufficient spatio-temporal interaction. Specifically, DeST performs once unified spatial modeling and divides the spatial features into different groups of subfeatures, which then adaptively interact with temporal features from different layers. Since the different sub-features contain distinct spatial semantics, the model could learn the optimal interaction pattern at each layer. Meanwhile, inspired by the fact that different joints move at different speeds, we propose joint-decoupled temporal modeling, which employs independent trainable weights to capture distinctive temporal features of each joint. On four large-scale benchmarks of different scenes, DeST significantly outperforms current state-of-the-art methods with less computational complexity.
DFormer: Rethinking RGBD Representation Learning for Semantic Segmentation
Sep 18, 2023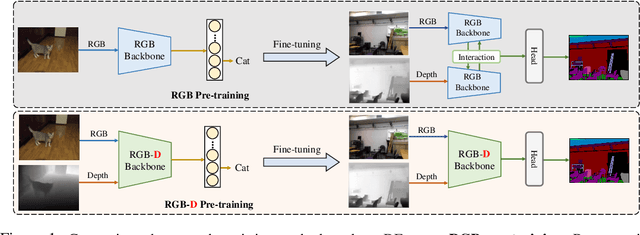
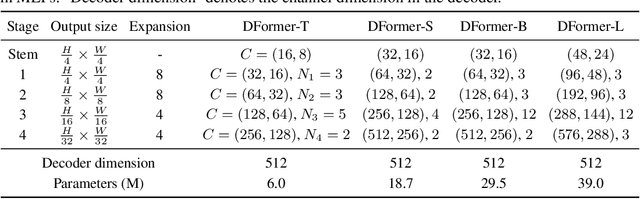
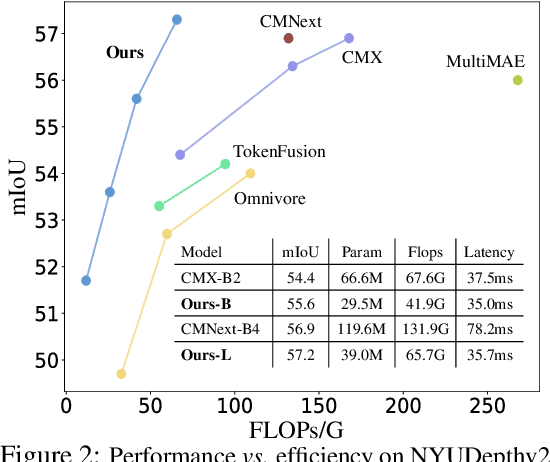
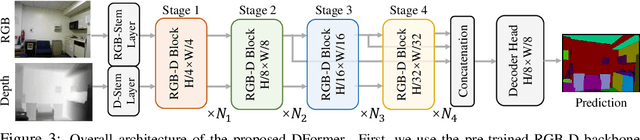
We present DFormer, a novel RGB-D pretraining framework to learn transferable representations for RGB-D segmentation tasks. DFormer has two new key innovations: 1) Unlike previous works that aim to encode RGB features,DFormer comprises a sequence of RGB-D blocks, which are tailored for encoding both RGB and depth information through a novel building block design; 2) We pre-train the backbone using image-depth pairs from ImageNet-1K, and thus the DFormer is endowed with the capacity to encode RGB-D representations. It avoids the mismatched encoding of the 3D geometry relationships in depth maps by RGB pre-trained backbones, which widely lies in existing methods but has not been resolved. We fine-tune the pre-trained DFormer on two popular RGB-D tasks, i.e., RGB-D semantic segmentation and RGB-D salient object detection, with a lightweight decoder head. Experimental results show that our DFormer achieves new state-of-the-art performance on these two tasks with less than half of the computational cost of the current best methods on two RGB-D segmentation datasets and five RGB-D saliency datasets. Our code is available at: https://github.com/VCIP-RGBD/DFormer.