 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiang Wan
UWAFA-GAN: Ultra-Wide-Angle Fluorescein Angiography Transformation via Multi-scale Generation and Registration Enhancement
May 01, 2024
Fundus photography, in combination with the ultra-wide-angle fundus (UWF) techniques, becomes an indispensable diagnostic tool in clinical settings by offering a more comprehensive view of the retina. Nonetheless, UWF fluorescein angiography (UWF-FA) necessitates the administration of a fluorescent dye via injection into the patient's hand or elbow unlike UWF scanning laser ophthalmoscopy (UWF-SLO). To mitigate potential adverse effects associated with injections, researchers have proposed the development of cross-modality medical image generation algorithms capable of converting UWF-SLO images into their UWF-FA counterparts. Current image generation techniques applied to fundus photography encounter difficulties in producing high-resolution retinal images, particularly in capturing minute vascular lesions. To address these issues, we introduce a novel conditional generative adversarial network (UWAFA-GAN) to synthesize UWF-FA from UWF-SLO. This approach employs multi-scale generators and an attention transmit module to efficiently extract both global structures and local lesions. Additionally, to counteract the image blurriness issue that arises from training with misaligned data, a registration module is integrated within this framework. Our method performs non-trivially on inception scores and details generation. Clinical user studies further indicate that the UWF-FA images generated by UWAFA-GAN are clinically comparable to authentic images in terms of diagnostic reliability. Empirical evaluations on our proprietary UWF image datasets elucidate that UWAFA-GAN outperforms extant methodologies. The code is accessible at https://github.com/Tinysqua/UWAFA-GAN.
MileBench: Benchmarking MLLMs in Long Context
Apr 29, 2024Despite the advancements and impressive performance of Multimodal Large Language Models (MLLMs) on benchmarks, their effectiveness in real-world, long-context, and multi-image tasks is unclear due to the benchmarks' limited scope. Existing benchmarks often focus on single-image and short-text samples, and when assessing multi-image tasks, they either limit the image count or focus on specific task (e.g time-series captioning), potentially obscuring the performance challenges of MLLMs. To address these limitations, we introduce MileBench, a pioneering benchmark designed to test the MultImodal Long-contExt capabilities of MLLMs. This benchmark comprises not only multimodal long contexts, but also multiple tasks requiring both comprehension and generation. We establish two distinct evaluation sets, diagnostic and realistic, to systematically assess MLLMs' long-context adaptation capacity and their ability to complete tasks in long-context scenarios. Our experimental results, obtained from testing 20 models, revealed that while the closed-source GPT-4(Vision) and Gemini 1.5 outperform others, most open-source MLLMs struggle in long-context situations. Interestingly, the performance gap tends to widen with an increase in the number of images. We strongly encourage an intensification of research efforts towards enhancing MLLMs' long-context capabilities, especially in scenarios involving multiple images.
Extracting Clean and Balanced Subset for Noisy Long-tailed Classification
Apr 10, 2024Real-world datasets usually are class-imbalanced and corrupted by label noise. To solve the joint issue of long-tailed distribution and label noise, most previous works usually aim to design a noise detector to distinguish the noisy and clean samples. Despite their effectiveness, they may be limited in handling the joint issue effectively in a unified way. In this work, we develop a novel pseudo labeling method using class prototypes from the perspective of distribution matching, which can be solved with optimal transport (OT). By setting a manually-specific probability measure and using a learned transport plan to pseudo-label the training samples, the proposed method can reduce the side-effects of noisy and long-tailed data simultaneously. Then we introduce a simple yet effective filter criteria by combining the observed labels and pseudo labels to obtain a more balanced and less noisy subset for a robust model training. Extensive experiments demonstrate that our method can extract this class-balanced subset with clean labels, which brings effective performance gains for long-tailed classification with label noise.
Apollo: An Lightweight Multilingual Medical LLM towards Democratizing Medical AI to 6B People
Mar 09, 2024
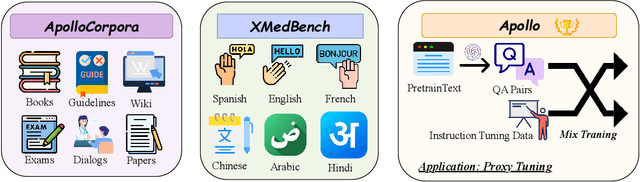
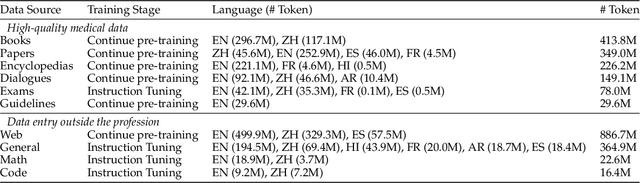

Despite the vast repository of global medical knowledge predominantly being in English, local languages are crucial for delivering tailored healthcare services, particularly in areas with limited medical resources. To extend the reach of medical AI advancements to a broader population, we aim to develop medical LLMs across the six most widely spoken languages, encompassing a global population of 6.1 billion. This effort culminates in the creation of the ApolloCorpora multilingual medical dataset and the XMedBench benchmark. In the multilingual medical benchmark, the released Apollo models, at various relatively-small sizes (i.e., 0.5B, 1.8B, 2B, 6B, and 7B), achieve the best performance among models of equivalent size. Especially, Apollo-7B is the state-of-the-art multilingual medical LLMs up to 70B. Additionally, these lite models could be used to improve the multi-lingual medical capabilities of larger models without fine-tuning in a proxy-tuning fashion. We will open-source training corpora, code, model weights and evaluation benchmark.
Large Multimodal Agents: A Survey
Feb 23, 2024Large language models (LLMs) have achieved superior performance in powering text-based AI agents, endowing them with decision-making and reasoning abilities akin to humans. Concurrently, there is an emerging research trend focused on extending these LLM-powered AI agents into the multimodal domain. This extension enables AI agents to interpret and respond to diverse multimodal user queries, thereby handling more intricate and nuanced tasks. In this paper, we conduct a systematic review of LLM-driven multimodal agents, which we refer to as large multimodal agents ( LMAs for short). First, we introduce the essential components involved in developing LMAs and categorize the current body of research into four distinct types. Subsequently, we review the collaborative frameworks integrating multiple LMAs , enhancing collective efficacy. One of the critical challenges in this field is the diverse evaluation methods used across existing studies, hindering effective comparison among different LMAs . Therefore, we compile these evaluation methodologies and establish a comprehensive framework to bridge the gaps. This framework aims to standardize evaluations, facilitating more meaningful comparisons. Concluding our review, we highlight the extensive applications of LMAs and propose possible future research directions. Our discussion aims to provide valuable insights and guidelines for future research in this rapidly evolving field. An up-to-date resource list is available at https://github.com/jun0wanan/awesome-large-multimodal-agents.
Cell Graph Transformer for Nuclei Classification
Feb 20, 2024Nuclei classification is a critical step in computer-aided diagnosis with histopathology images. In the past, various methods have employed graph neural networks (GNN) to analyze cell graphs that model inter-cell relationships by considering nuclei as vertices. However, they are limited by the GNN mechanism that only passes messages among local nodes via fixed edges. To address the issue, we develop a cell graph transformer (CGT) that treats nodes and edges as input tokens to enable learnable adjacency and information exchange among all nodes. Nevertheless, training the transformer with a cell graph presents another challenge. Poorly initialized features can lead to noisy self-attention scores and inferior convergence, particularly when processing the cell graphs with numerous connections. Thus, we further propose a novel topology-aware pretraining method that leverages a graph convolutional network (GCN) to learn a feature extractor. The pre-trained features may suppress unreasonable correlations and hence ease the finetuning of CGT. Experimental results suggest that the proposed cell graph transformer with topology-aware pretraining significantly improves the nuclei classification results, and achieves the state-of-the-art performance. Code and models are available at https://github.com/lhaof/CGT
UniCell: Universal Cell Nucleus Classification via Prompt Learning
Feb 20, 2024The recognition of multi-class cell nuclei can significantly facilitate the process of histopathological diagnosis. Numerous pathological datasets are currently available, but their annotations are inconsistent. Most existing methods require individual training on each dataset to deduce the relevant labels and lack the use of common knowledge across datasets, consequently restricting the quality of recognition. In this paper, we propose a universal cell nucleus classification framework (UniCell), which employs a novel prompt learning mechanism to uniformly predict the corresponding categories of pathological images from different dataset domains. In particular, our framework adopts an end-to-end architecture for nuclei detection and classification, and utilizes flexible prediction heads for adapting various datasets. Moreover, we develop a Dynamic Prompt Module (DPM) that exploits the properties of multiple datasets to enhance features. The DPM first integrates the embeddings of datasets and semantic categories, and then employs the integrated prompts to refine image representations, efficiently harvesting the shared knowledge among the related cell types and data sources. Experimental results demonstrate that the proposed method effectively achieves the state-of-the-art results on four nucleus detection and classification benchmarks. Code and models are available at https://github.com/lhaof/UniCell
ALLaVA: Harnessing GPT4V-synthesized Data for A Lite Vision-Language Model
Feb 18, 2024Recent advancements in Large Vision-Language Models (LVLMs) have enabled processing of multimodal inputs in language models but require significant computational resources for deployment, especially in edge devices. This study aims to bridge the performance gap between traditional-scale LVLMs and resource-friendly lite versions by adopting high-quality training data. To do this, a synthetic dataset is created by leveraging GPT-4V's ability to generate detailed captions, complex reasoning instructions and detailed answers from images. The resulted model trained with our data, ALLaVA, achieves competitive performance on 12 benchmarks up to 3B LVLMs. This work highlights the feasibility of adopting high-quality data in crafting more efficient LVLMs. Our online demo is available at \url{https://allava.freedomai.cn}.
ICHPro: Intracerebral Hemorrhage Prognosis Classification Via Joint-attention Fusion-based 3d Cross-modal Network
Feb 17, 2024Intracerebral Hemorrhage (ICH) is the deadliest subtype of stroke, necessitating timely and accurate prognostic evaluation to reduce mortality and disability. However, the multi-factorial nature and complexity of ICH make methods based solely on computed tomography (CT) image features inadequate. Despite the capacity of cross-modal networks to fuse additional information, the effective combination of different modal features remains a significant challenge. In this study, we propose a joint-attention fusion-based 3D cross-modal network termed ICHPro that simulates the ICH prognosis interpretation process utilized by neurosurgeons. ICHPro includes a joint-attention fusion module to fuse features from CT images with demographic and clinical textual data. To enhance the representation of cross-modal features, we introduce a joint loss function. ICHPro facilitates the extraction of richer cross-modal features, thereby improving classification performance. Upon testing our method using a five-fold cross-validation, we achieved an accuracy of 89.11%, an F1 score of 0.8767, and an AUC value of 0.9429. These results outperform those obtained from other advanced methods based on the test dataset, thereby demonstrating the superior efficacy of ICHPro. The code is available at our Github: https://github.com/YU-deep/ICH.
nnMamba: 3D Biomedical Image Segmentation, Classification and Landmark Detection with State Space Model
Feb 05, 2024In the field of biomedical image analysis, the quest for architectures capable of effectively capturing long-range dependencies is paramount, especially when dealing with 3D image segmentation, classification, and landmark detection. Traditional Convolutional Neural Networks (CNNs) struggle with locality respective field, and Transformers have a heavy computational load when applied to high-dimensional medical images. In this paper, we introduce nnMamba, a novel architecture that integrates the strengths of CNNs and the advanced long-range modeling capabilities of State Space Sequence Models (SSMs). nnMamba adds the SSMs to the convolutional residual-block to extract local features and model complex dependencies. For diffirent tasks, we build different blocks to learn the features. Extensive experiments demonstrate nnMamba's superiority over state-of-the-art methods in a suite of challenging tasks, including 3D image segmentation, classification, and landmark detection. nnMamba emerges as a robust solution, offering both the local representation ability of CNNs and the efficient global context processing of SSMs, setting a new standard for long-range dependency modeling in medical image analysis. Code is available at https://github.com/lhaof/nnMamba